目录
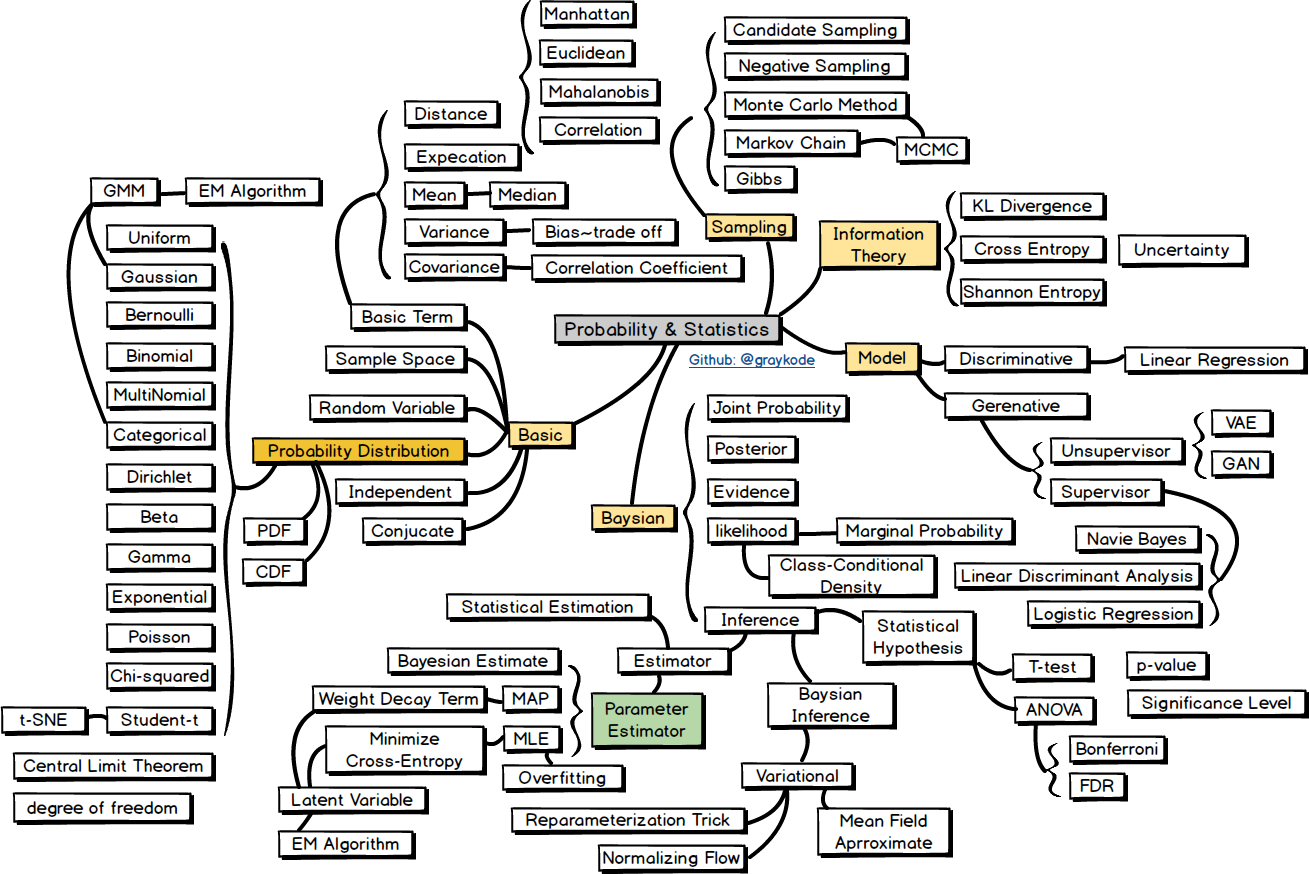
概率与统计

Basic
- Sample Space:样本空间
- Random Variable:随机变量
- Independent:独立性
- Conjucate:共轭
Basic Term
- Expecation:期望
- Mean:均值
- Variance:方差
- Covariance:协方差
- Correlation Coefficient:相关系数
- Distance:距离
- Manhattan
- Euclidean
- Mahalanobis
- Correlation
Probability Distribution
- PDF:概率分布函数
- CDF:累积分布函数
- Uniform:均匀分布
- GMM - EM ALgorithm
- Gaussian:高斯分布(正态分布)
- Categorical:类别分布
- Bernoulli:伯努利分布
- Binomial:二项分布
- MultiNormial:多元正态分布
- Dirichlet:狄利克雷分布
- Beta:贝塔分布
- Gamma:伽马分布
- Exponential:指数分布
- Chi-squared:卡方分布
- Student-t:t 分布
- Central Limit Theorem:中心极限定理
- degree of freedom:自由度
- KL Divergence:KL 散度
- Cross Entropy:交叉熵
- Shannon Entropy:信息熵
Sampling
- Candidate Sampling:候选人抽样
- Negative Sampling:负采样
- MCMC:马尔科夫蒙特卡洛模拟
- Monte Carlo Method:蒙特卡洛方法
- Markov Chain:马尔科夫链
- Gibbs:吉布斯采样
Model
- Discriminative:判别性
- Gerenative
- Unsupervisor
- Supervisor
- Navie Bayes
- Linear Discriminant Analysis
- Logistic Regression
Baysian
- Joint Probability
- Posterior
- Evidence
Likelihood
- Marginal Probability
- Class-Conditional Density
Inference
- Estimator
- Statistical Estimation
- Parameter Estimator
- Bayesian Estimate
- MAP
- MLE
- Minimize Cross-Entropy
- Overfitting
- Latent Variable
- EM Algorithm
- Statistical Hypothesis
- p-value
- Significance Level
- T-test
- ANOVA
- Baysian Inference
- Variational
- Reparameterization Trick
- Normalizing Flow
- Mean Field Approximate
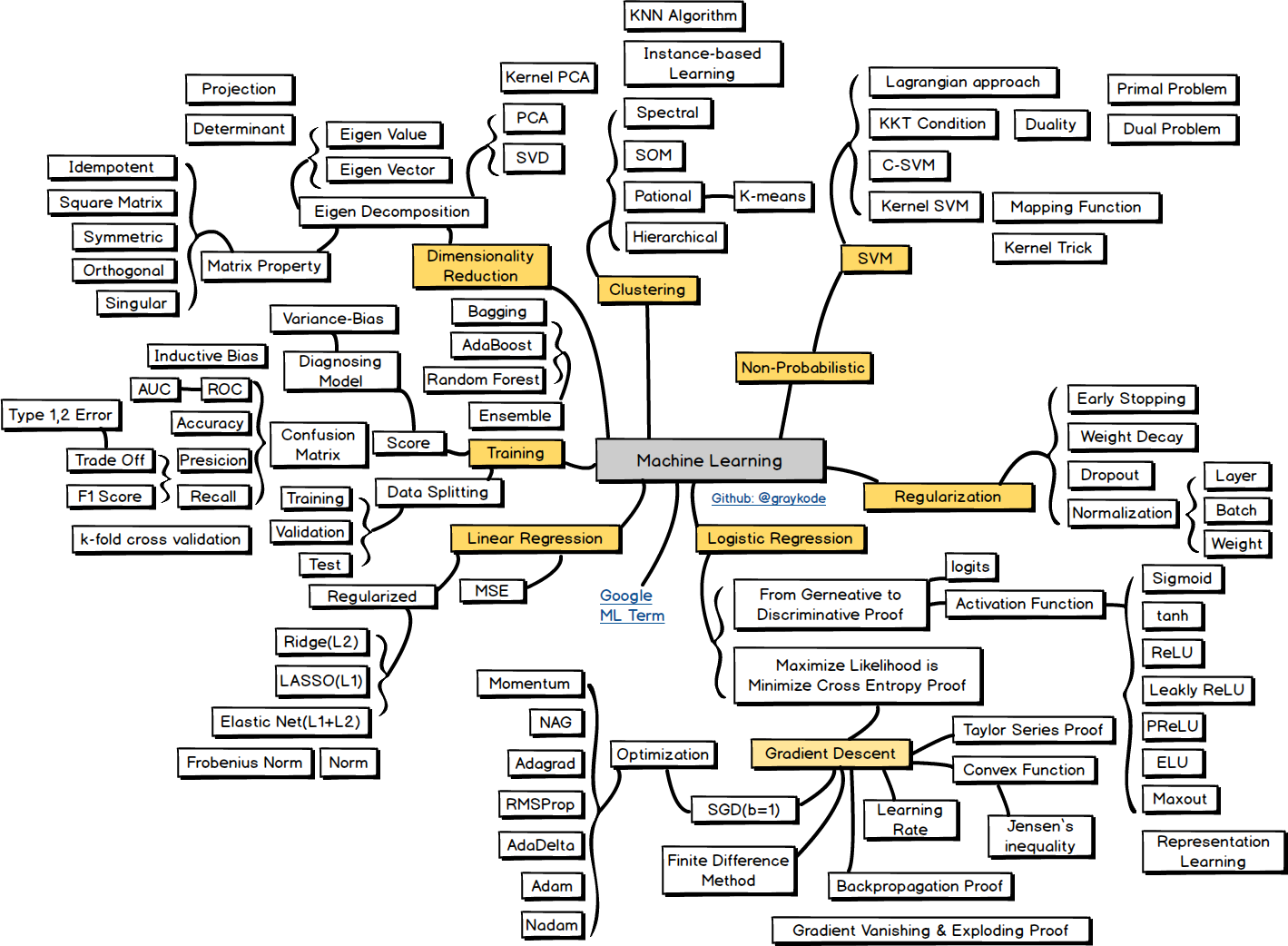
机器学习

Linear Regression
- MSE
- Regularized
- Ridge(L2)
- LASSO(L1)
- Elastic Net(L1 + L2)
Logistic Regression
- From Gerneative to Discriminative Proof
- logits
- Activation Function
- Sigmoid
- tanh
- ReLU
- Leakly ReLU
- PReLU
- ELU
- Maxout
- Representation Learning
- Maximize Likelihood is Minimize Cross Entropy Proof
- Gradient Descent
- Taylor Series Proof
- Convex Function
- SGD(b = 1)
- Optimization
- Momentum
- NAG
- Adagrad
- RMSProp
- AdaDelta
- Adam
- Nadam
- Learning Rate
- Backpropagation Proof
- Gradient Vanishing & Exploding Proof
- Finite Difference Method
Non-Probabilistic
- SVM
- Lagrangian approach
- KKT Condition
- Duality
- Primal Problem
- Dual Problem
- C-SVM
- Kernel SVM
- Mapping Function
- Kernel Trick
Ensemble
- Bagging
- AdaBoost
- Random Forest
Clustering
- Hierarchical
- Pational
- SOM
- Spectral
- KNN Algorithm
- Instance-based Learning
Dimensionality Reduction
- Eigen Decomposition
- Eigen Value
- Eigen Vector
- PCA
- SVD
- Matrix Property
- Idempotent
- Square Matrix
- Symmetric
- Orthogonal
- Singular
Training
- Data Splitting
- Training
- Validation
- Test
- k-fold cross validation
- Score
- Diagnosing Model
- Confusion Matrix
- Accuracy
- AUC-ROC
- Presicion
- Recall
- Trade Off
- Type 1, 2 Error
- F1 Score
Regularization
- Early Stopping
- Weight Decay
- Dropout
- Normalization
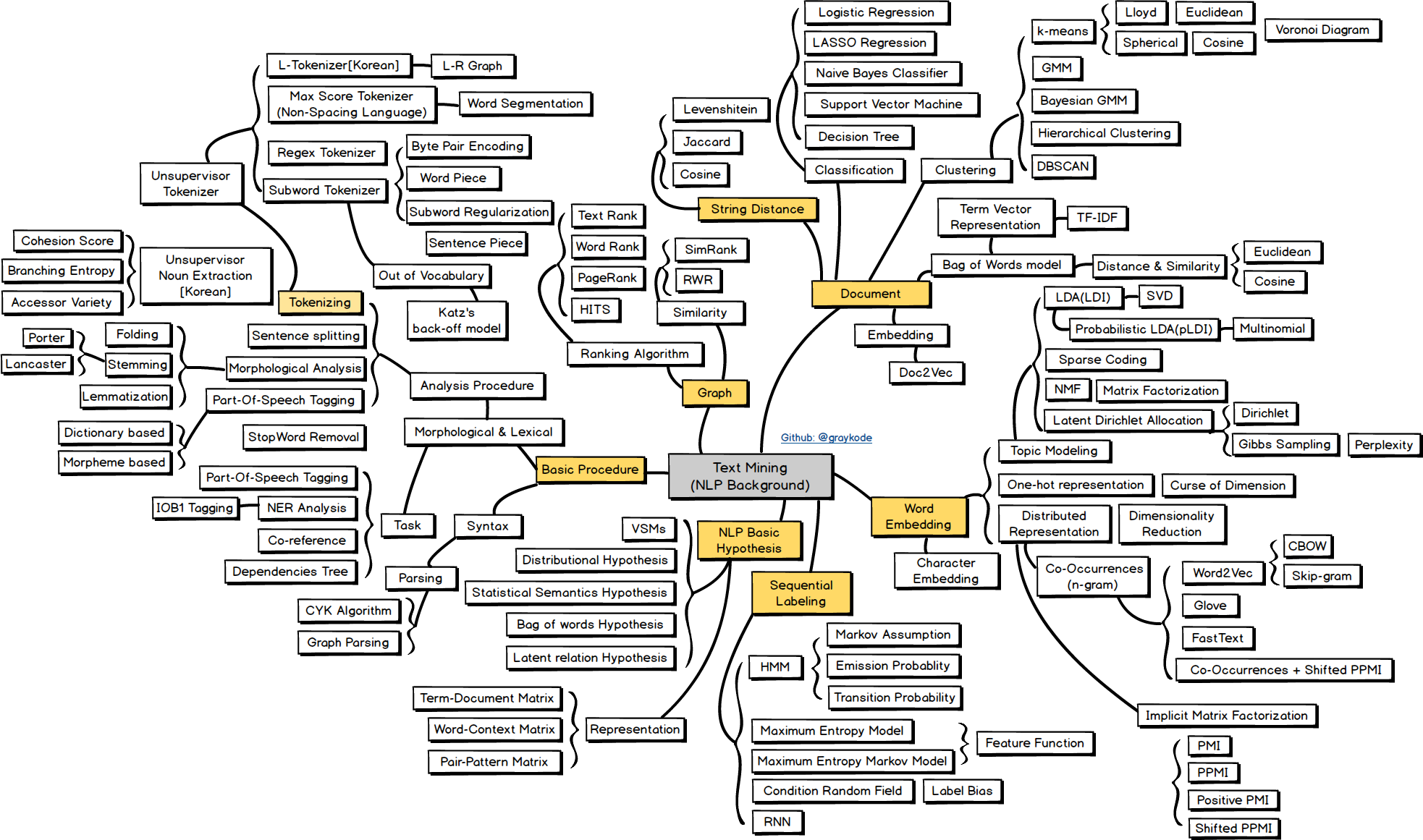
文本挖掘

Basic Procedure
- Morphological & Lexical
- Analysis Procedure
- Sentence splitting
- Morphological Analysis
- Part-Of-Speech Tagging
- Task
- Syntax
- Parsing
- CKY Algorithm
- Graph Parsing
NLP Basic HyPothesis
Sequential Labeling
- HMM
- Markov Assumption
- Emission Probablity
- Transition Probability
- Maximum Entropy Model
- Maximum Entropy Markov Model
- Condition Random Field
- RNN
Word Embedding
- Topic Modeling
- LDA(LDI)
- SVD
- Probabilistic LDA(pLDI)
- Sparse Coding
- NMF -> Matrix Factorization
- Laten Dirichlet Allocation
- Dirichlet
- Gibbs Sampling -> Perplexity
- One-hot Representation
- Distributed Representation
- Dimensionality Reduction
- Co-Occurrence(n-gram)
- Word2Vec
- GloVe
- FastText
- Co-Occurrence + Shifted PPMI
- Implicit Matrix Factorization
- PMI
- PPMI
- Positive PMI
- Shifted PPMI
- Character Embedding
Graph
- Ranking Algorithm
- Text Rank
- Word Rank
- PageRank
- HITS
- Similarity
Document
String Distance
- Levenshitein
- Jaccard
- Cosine
Classification
- Logistic Regression
- LASSO Regression
- Naive Bayes Classifer
- Support Vector Machine
- Decision Tree
Clustering
- K-Means
- Lloyd
- Euclidean
- Spherical
- Cosine
- Voronoi Diagram
- GMM
- Bayesian GMM
- Hierarchical Clustering
- DBSCAN
Bag of Words model
- Term Vector Representation
- Distance & Similarity
Embedding
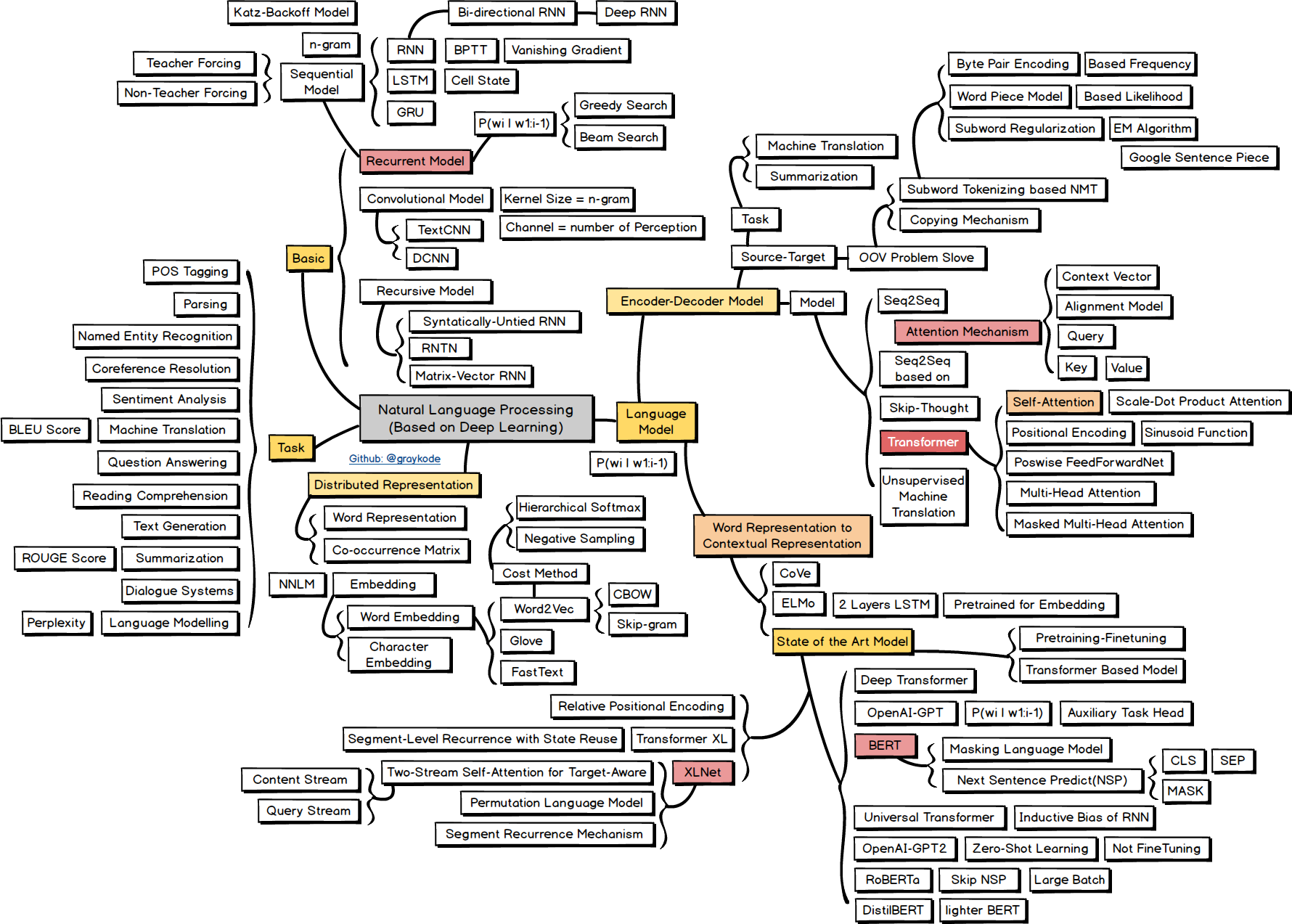
自然语言处理

Task
- POS Tagging:词性标注
- Parsing:解析
- Named Entity Recognition:命令实体识别
- Coreference Resolution:指代消解
- Sentiment Analysis:情感分析
- Machine Translation:机器翻译
- Question Answering:问答系统
- Reading Comprehension:阅读理解
- Text Generation:文本生成
- Summarization:文本摘要
- Dialogue Systems:对话系统
- Language Modeling:语言模型
Basic
Recurrent Model
- Sequential Model
- n-gram
- Katz-Backoff Model
- RNN
- Bi-directional RNN
- Deep RNN
- BPTT
- Vanishing Gradient
- LSTM
- GRU
- Teacher Forcing
- Non-Teacher Forcing
- P(wi|w1:i−1)
- Greedy Search
- Beam Search
Convolutional Model
- Kernel Size = n-gram
- Channel = number of Perception
- TextCNN
- DCNN
Recursive Model
- Syntatically-Untied RNN
- RNTN
- Matrix-Vector RNN
Language Model
Word Representation to Contextual Representation
- CoVe
- ELMo
- 2 Layers LSTM
- Pretrained for Embedding
- State of the Art Model
- Models 1:
- Pretraining-Finetuning
- Transformer Based Model
- Models 2:
- Transformer
- OpenAI-GPT
- P(wi|w1:i−1)
- Auxiliary Task Head
- BERT
- Masking Language Model
- Next Sentence Predict(NSP)
- Universal Transformer
- OpenAI-GPT2
- Zero-Shot Learning
- Not FineTuning
- OpenAI-GPT3
- RoBERTTa
- DistilBERT
- Models 3:
- Relative Positional Encoding
- Transformer XL
- Segment-Level Recurrence with State Reuse
- XLNet
- Two-Stream Self-Attention for Target-Aware
- Content Stream
- Query Stream
- Permutation Language Model
- Segment Recurrence Mechanism
Encoder-Decoder Model
- Source-Target
- OOV Problem Slove
- Subword Tokenizing based NMT
- Byte Pair Encoding
- Word Piece Model
- Subword Regularization
- EM Algorithm
- Google Sentence Piece
- Copying Mechanism
- Task
- Machine Translation
- Summarization
- Model
- Seq2Seq
- Attention Mechanism
- Context Vector
- Alignment Model
- Query
- Key Value
- Seq2Seq based on
- Skip-Thought
- Transformer
- Self-Attention
- Scale-Dot Product Attention
- Positional Encoding
- Poswise FeedForwardNet
- Multi-Head Attention
- Masked Multi-Head Attention
- Unsupervised Machine Translation
Distributed Representation
- Word Representation
- Co-Occurrence Matrix
- Co-Occurrences + Shifted PPMI
- NNLM
- Embedding
- Word Embedding
- Word2Vec
- CostMethod
- Hierarchical Softmax
- Negative Sampling
- GloVe
- FastText
- Character Embedding