LLM 框架--LangChain
wangzf / 2024-05-15
LangChain 简介
框架简介
ChatGPT 的巨大成功激发了越来越多的开发者兴趣,他们希望利用 OpenAI 提供的 API 或者私有化模型, 来开发基于大型语言模型的应用程序。尽管大型语言模型的调用相对简单,但要创建完整的应用程序, 仍然需要大量的定制开发工作,包括 API 集成、互动逻辑、数据存储等等。 为了解决这个问题,从 2022 年开始,许多机构和个人相继推出了多个开源项目, 旨在帮助开发者们快速构建基于大型语言模型的端到端应用程序或工作流程。 其中一个备受关注的项目就是 LangChain 框架。
LangChain 框架是一个开源工具,充分利用了大型语言模型的强大能力,以便开发各种下游应用。 它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。 具体来说,LangChain 框架可以实现数据感知和环境互动,也就是说, 它能够让语言模型与其他数据来源连接,并且允许语言模型与其所处的环境进行互动。

LangChain 是一个用于开发由大型语言模型(LLMs)支持的应用程序的框架。 LangChain 简化了 LLM 应用生命周期的每个阶段:
- 开发:使用 LangChain 的开源构建块、组件和第三方集成来构建应用程序。 使用 LangGraph 构建具有一级流式和人机交互支持的有状态 Agent
- 生产化:使用 LangSmith 检查、监控和评估 Chain,以便持续优化和部署 Chain
- 部署:使用 LangGraph Cloud 将 LangGraph 应用程序转变为生产就绪的 API 和助手
框架架构
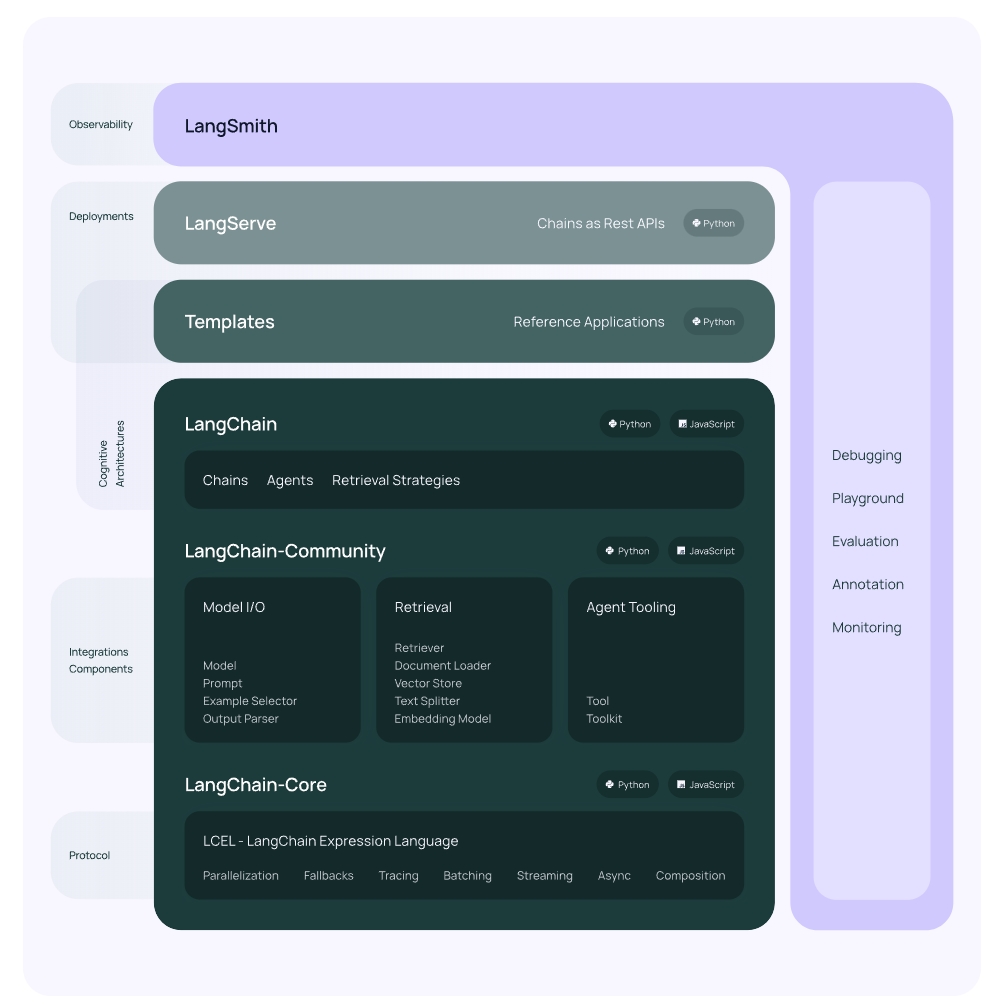
具体来说,该框架由以下开源库组成:
- LangChain Core:
langchain-core- LangChain 框架的核心库、核心组件, 提供了基础抽象和 LangChain 表达式语言(LangChain Expression Language, LCEL), 提供基础架构和工具,用于构建、运行和与 LLM 交互的应用程序,为 LangChain 应用程序的开发提供了坚实的基础。 用到的处理文档、格式化 prompt、输出解析等都来自这个库。
- Parallelization
- Fallbacks
- Tracing
- Batching
- Streaming
- Async
- Composition
- LangChain:
langchain- Chains
- Agents
- Retrieval Strategies
- LangChain Community:
langchain-community- 第三方集成。专注于第三方集成,极大地丰富了 LangChain 的生态系统, 使得开发者可以更容易地构建复杂和强大的应用程序,同时也促进了社区的合作和共享。
- Model I/O
- Model: LLMs
- Prompt
- Example Selector
- Output Parser
- Retrieval
- Retrieval
- Document Loader
- Vector Store
- Text Splitter
- Embedding Model
- Agent Tooling
- Tool
- Toolkit
- 集成包(integration packages)
langchain-openailangchain-anthropic- …
- LangGraph
- 应用构建
- LangServe
- 部署服务,用于将 LangChain 应用程序部署到云端,提供可扩展、高可用的托管解决方案, 并带有监控和日志功能。简化部署流程,让开发者可以专注于应用程序的开发,而不必担心底层的基础设施和运维工作。
- LangSmith
- 开发者平台,专注于 LangChain 应用程序的开发、调试和测试,提供可视化界面和性能分析工具, 旨在帮助开发者提高应用程序的质量,确保它们在部署前达到预期的性能和稳定性标准。
- debugging
- playground
- prompt management
- annotation
- testing/evaluate
- monitoring
- LangChain CLI:命令行工具,使开发者能够通过终端与 LangChain 框架交互,执行项目初始化、测试、部署等任务。 提高开发效率,让开发者能够通过简单的命令来管理整个应用程序的生命周期。
核心概念
LangChain 作为一种大模型应用开发框架,针对当前 AI 应用开发中的一些关键挑战提供了有效的 解决方案, 概述如下:
- 数据时效性
- LangChain 可以通过集成外部知识库和向量数据库,允许开发者将最新的数据和信息注入模型中, 从而提高应用的时效性。
- token 数量限制
- LangChain 通过优化提示词和链的管理,帮助开发者突破模型 token 数量限制,例如通过分块处理长文档, 或者使用特定的提示模版来引导模型生成更有效的输出。
- 网络连接限制
- 大语言模型本身无法联网查询,但 LangChain 可以作为中间件, 帮助开发者将模型与实时数据源连接起来, 例如通过 API 调用获取最新的信息,然后将这些信息作为输入传递给模型。
- 数据源整合限制
- LangChain 支持与多种数据源的整合,包括私有数据库、API 和其他第三方工具, 这使得开发者能够构建更加灵活和多样化的应用,充分利用不同数据源的优化。
LangChain 是一个专为开发大模型驱动的应用而设计的框架,它赋予应用程序以下 特性:
- 能够理解和适应上下文
- 将大模与各种上下文信息(如提示指令、小样本示例、外挂知识库内容等)相结合, 使之能够根据不同情境做出响应。
- 具备推理能力
- 依靠大模型进行推理分析,以决定如何基于提供的上下文信息做出回答或采取相应行动。
LangChain 的 核心优势 包括两个方面:
- 组件化
- 提供一系列工具和集成模块,既可以单独使用,也可与 LangChain 框架其他部分结合, 提高与大模型协作的效率和灵活性。
- 现成的链
- 内置多个组件组合,专为处理复杂任务设计,提供即插即用的高级功能。
LangChain 通过组件化和现成的链,降低了使用大模型构建应用的门槛,可以适应广泛的应用场景。 得益于最初设计中足够的抽象层次,LangChain 能够与大模型应用形态的演进保持同步。 应用形态的 总体迭代过程 概述如下:
- 入门阶段
- 构建以单一提示词为中心的应用程序
- 进阶阶段
- 通过组合一系列提示词创建更复杂的应用
- 发展阶段
- 开发由大模型驱动的智能代理(agent)应用
- 探索阶段
- 实现多个智能代理(agent)协同工作,以应对高度复杂的应用场景
核心模块
LangChain 使用以下 6 种核心模块提供标准化、可扩展的接口和外部集成, 分别是:模型 I/O(Model I/O)模块、检索(Retrieval)模块、链(Chain)模块、 记忆(Memory)模块、代理(Agent)模块 和 回调(Callback)模块。
在 LangChain 的组件系统中,各个模块相互协作,共同构建复杂的大模型应用。模型 I/O 模块确保与语言模型高效变互, 包括输入提示管理和输出解析。检索模块补充了这一流程,为生成过程提供必要的外部知识,提高了模型的响应质量。 紧随其后的链模块,通过定义一系列组件调用,将模型 I/O 模块和检索模块的功能事联起来,实现特定的业务逻辑。 记忆模块为链提供了记忆功能,以维持应用的状态,并且在整个应用运行期间管理信息流。 代理模块进一步增强了 LangChain 的灵活性,通过智能代理动态地决定行动的序列,这些代理利用了前述所有模块的能力。 最后,回调模块以其全局和请求级别的自定义处理逻辑,为开发者构建应用提供了细粒度的控制和响应能力。 正是这些能力的结合,LangChain 的真正潜力得以释放,使开发者能够构建出响应迅速、高度定制的 AI 应用。
模型 I/O 模块
模型 I/O 模块主要与大模型交互相关,由三个部分组成:
- 提示词管理部分用于模块化,动态选择和管理模型输入;
- 语言模型部分通过调用接口调用大模型;
- 输出解析器负责从模型输出中提取信息。
检索模块
LangChain 提供了一个 检索增强生成(retrieval-augmented generation, RAG)模块。
- 从外部检索 用户特定数据 并将其整合到大模型中,包括超过 100 种 文档加载器, 可以从各种 数据源(如私有数据库/公共网站以及企业知识库等) 加载 不同格式(HTML、PDF、Word、Excel、图像等)的文档。
- 为了提取文档的相关部分,文档转换器引擎 可以将大文档分割成小块。 检索模块提供了多种算法和针对特定文档类型的优化逻辑。
- 文本嵌入模型 也是检索过程的关键组成部分,它们可以捕捉文本的语义从而快速找到相似的文本。 检索模块集成了多种类型的嵌入模型,并提供标准接口以简化模型间的切换。
- 为了高效存储和搜索嵌入向量,检索模块与超过 50 种 向量存储引擎集成, 既支持开源的本地向量数据库,也可以接入云厂商托管的私有数据库。 开发者可以根据需要,通过标准接口灵活地在不同的向量存储之间切换。
检索模块扩展了 LangChain 的功能,允许从外部数据源种提取并整合信息, 增强了语言模型的回答能力。这种增强生成的能力为链模块种的复杂应用场景提供了支持。
链模块
链定义为对一系列组件的组合调用。既可以在处理简单应用时单独使用链, 也可以在处理复杂应用时将多个链和其他组件组合起来进行链式连接。
LangChain 提供了两种方式来实现链:
- 早期的 Chain 编程接口
- 是一种命令式编程
- 最新的 LangChain 表达式(LangChain Expression Language, LCEL)
- 是一种声明式编程
- 官方推荐使用 LCEL 的方式构建链。LCEL 的核心优势在于提供了直观的语法, 并支持流式传输、异步调用、批处理、并行化、重试和追踪等特性
- 通过 Chain 编程接口构建的链也可以被 LCEL 使用,两者并非完全互斥
链模块代表了 LangChain 中组件调用的核心,它不仅可以将模型 I/O 模块和检索模块的能力结合起来, 还可以构建出更加复杂的业务逻辑。链的灵活性为记忆模块的引入提供了理想的衔接点,使得应用能够维持状态。
记忆模块
记忆模块用于保存应用运行期间的信息,以维持应用的状态。 这个需求主要源自大多数大模型应用有一个聊天界面, 而聊天对话的一个基本特点使应用能够读取历史互动信息。因此,设计一个对话系统时, 它至少应该能够具备直接访问过去一段消息的能力,这种能力称为 “记忆”。LangChain 提供了很多工具来为系统添加记忆功能, 这些工具可以独立使用,也可以无缝整合到一条链中。
典型的记忆系统需要支持两个基本动作:读取 和 写入。每条链都定义了一些核心的执行逻辑, 并期望特定的输入,其中一些输入直接来自用户,但也有一些输入可能来自记忆。链在运行过程中,通常需要与记忆系统互动两次:
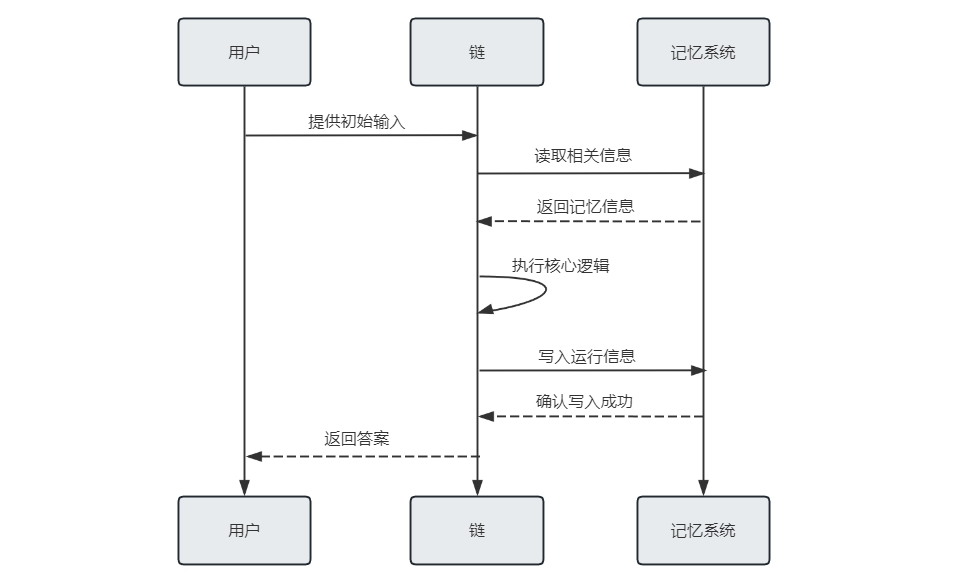
- 第一次是在接收到初始用户输入但在执行核心逻辑之前,链将从其记忆系统中读取信息,用于增强用户输入;
- 第二次是在执行核心逻辑之后、返回答案之前,链将把当前运行的输入和输出写入记忆系统,以便在未来的运行中可以参考。
链模块定义了如何调用各种组件,记忆模块则确保这些操作可以在需要时回顾之前的信息。 这个能力对于接下来要介绍的代理模块至关重要,因为代理需要记忆来做出更加智能的决策。
代理模块
代理的核思想是使用大模型来选择一系列要采取的行动。在链模块中,一系列调用是完全硬编码在代码中的。 而在代理模块中,使用大模型作为推理引擎来决定采取何种行动以及行动的顺序。
代理模块包含 4 个关键组件,它们之间的交互关系如下图:
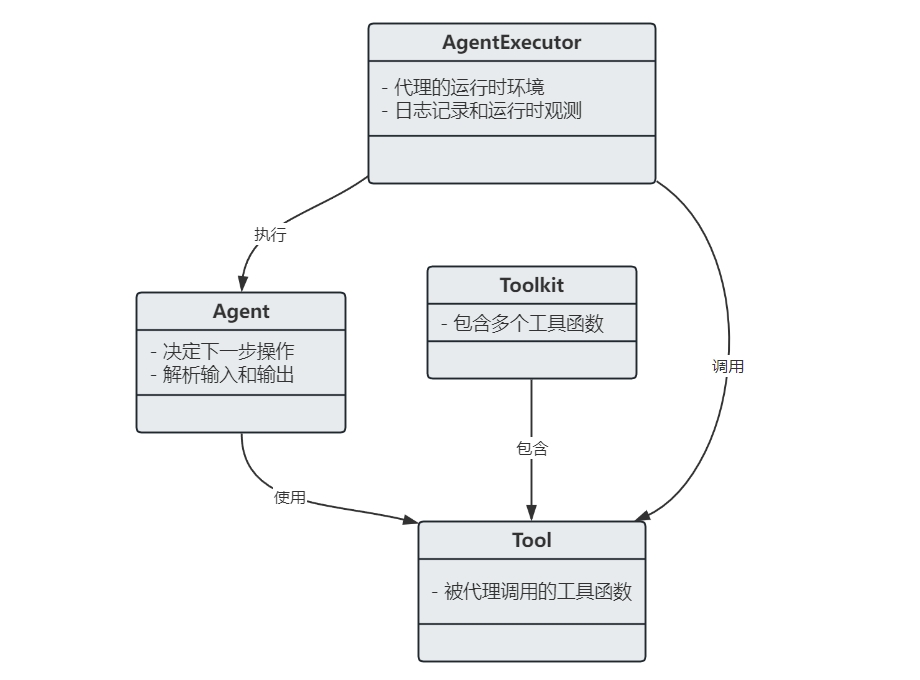
- Agent
- 通过大模型和提示词来决定下一步操作的决策组件。这个组件的输入包括可用的工具列表、 用户输入以及之前执行的步骤(中间步骤)。基于这些输入信息, Agent 组件会产生下一步的操作或是向用户发送最终响应,不同的 Agent 组件有不同的推理引导方式、 输入和输出解析方法。Agent 组件的类型多样,有结构化输入代理、零提示 ReAct 代理、 自问搜索式代理、OpenAI functions 代理等。
- Tool
- 这是代理调用的函数,对于构建智能代理至关重要。以合适的方式描述这些工具, 确保智能代理能够正常识别并访问工具。若未提供正确的工具集或描述不当,智能代理将无法正常工作。
- Tookit
- LangChain 提供了一系列工具包,以帮助开发者实现特定的目标。一个工具包中包含 3~5 个工具。
- AgentExecutor
- 这是代理的运行时环境,负责调用代理并执行其选择的动作。其工作流程是:获取下一个动作, 然后在该动作不是结束标志时,执行该动作并根据结果获取下一个动作,直至返回最终动作。 这个过程虽然表面上看起来很简单,但执行器封装了多种复杂情况,比如智能代理选取了不存在的工具、 调用的工具出错以及代理输出的结果无法解析为工具调用等, 同时还负责在各个层面(代理决策、工具调用)进行日志记录和提供可观测性支持, 支持最终输出到终端或指定文件。
回调模块
回调用于在特定操作(如 API 请求)发生时执行预定的处理程序,例如链、工具、代理等的构造和请求时, 都可以指定回调来执行预定程序。
回调有两种实现方式:
- 构造器回调 适用于跨越整个对象生命周期的操作,如日志记录或监视,而不是特定于单个请求
- 请求回调 适用于需要针对单个请求进行特别处理的场量,如将请求的输出实时传输到 WebSoeket 连接
回调模块为 LangChain 提供了高度的互动性和自定义响应能力,无论是在应用构建过程中记录日志, 还是处理实时数据流,皆可胜任。这为整个 LangChain 提供了一个可编程的反馈循环, 使得每个模块都能在适当的时候发挥作用,共同打造出一个高效、智能的大模型应用。
LangChain 使用
LangChain 为构建 LLM 应用提供了多种模块,这些模块既可以在简单应用中独立使用, 也可以通过 LCEL 进行复杂的组合。LCEL 定义了统一的可执行接口,让许多模块能够在组件之间无缝衔接。
一条简单而常见的处理链通常包含以下三个要素:
- 语言模型(LLM/ChatModel)
- 作为核心推理引擎,语言模型负责理解输入并生成输出。 要有效地使用 LangChain,需要了解不同类型的语言模型及其操作方式
- 提示模板(prompt template)
- 提示模板为语言模型提供具体的指令,指导其生成期望的输出。 正确配置指示模板可以显著提升模型的响应质量
- 输出解析器(output parser)
- 输出解析器将语言模型的原始响应转换成更易于理解和处理的格式, 以便后续步骤可以更有效地利用这些信息
LangChain 环境安装
开发环境
- Python 3.9+
langchain 库安装
pip:
$ pip install langchain
$ pip install langchain-experimental
conda:
$ conda install langchain -c conda-forge
源代码:
$ git clone https://github.com/langchain-ai/langchain.git
$ cd langchain
$ pip install -e .
其他库安装
LLM 应用托管服务 LangServe:用于一键部署 LangChain 应用
$ pip install langchain-cli
LLM 应用监控服务 LangSmith:用于调试和监控,默认包含在 LangChain 安装包中(如需单独使用,使用下面的命令)
$ pip install langsmith
OpenAI 的 GPT-3.5 模型需要安装 OpenAI SDK:
$ pip install openai
python-dotenv:为了支持与多种外部资源的集成,安装 python-dotenv 来管理访问密钥:
$ pip install python-dotenv
$ pip install fastapi
语言模型
简介:
LangChain 集成的模型主要分为两种:
- LLM:文本生成型模型,接收一个字符串作为输入,并返回一个字符串作为输出,
用于根据用户提供的提示词自动生成高质量文本的场景
- API:
langchain.llms
- API:
- ChatModel:对话型模型,接收一个消息列表作为输入,
并返回一个条消息作为输出,用于一问一答模式与用户持续对话的场景
- API:
langchain.chat_models
- API:
基本消息接口由 BaseMessage 定义,它有两个必需的属性:
- 内容(content):消息的内容,通常是一个字符串。
在 LangChain 中调用 LLM(
langchain.llms) 或 ChatModel(langchain.chat_models) 最简单的方法是使用invoke接口, 这是所有 LCEL 对象都默认实现的同步调用方法langchain.llms.invoke:输入一个字符串,返回一个字符串langchain.chat_models.invoke:输入一个BaseMessage列表,返回一个BaseMessage
- 角色(role):消息的发送方。LangChain 提供了几个对象来轻松区分不同的角色:
HumanMessage:人类(用户)输入的BaseMessageAIMessage:AI 助手(大模型)输出的BaseMessageSystemMessage:系统预设的BaseMessageFunctionMessage:调用自定义函数或工具输出的BaseMessageToolMessage:调用第三方工具输出的BaseMessageChatMessage:如果上述内置角色不能满足你的需求,可以用它自定义需要的角色, LangChain 在这方面提供了足够的灵活性
示例:
导入一个 LLM 和一个 ChatModel:
# 导入通用补全模型 OpenAI
from langchain_openai import OpenAI
# 导入聊天模型 ChatOpenAI
from langchain_community.chat_models import ChatOpenAI
llm = OpenAI()
chat_model = ChatOpenAI()
LLM 和 ChatModel 对象均提供了丰富的初始化配置,这里只传入字符串作演示:
# 导入表示用户输入的 HumanMessage
from langchain_core.messages import HumanMessage
text = "给生产杯子的公司取一个名字。"
message = [HumanMessage(content = text)]
def main():
print(llm.invoke(text))
# >> 茶杯屋
print(chat_model.invoke(message))
# >> content="杯享"
if __name__ = "__main__":
main()
提示模版
简介:
大多数 LLM 应用不会直接将用户输入传递给 LLM,而是将其添加到预先设计的 提示模板, 目的是给具体的任务提供额外的上下文。
上面的示例中,传递给大模型的文本包含 生成公司名称 的指令,对于具体的应用来说, 最好的情况是用户只需提供 对产品的描述,而不用考虑给语言模型提供 完整的指令。
API:
PromptTemplate就是用来解决这个问题的,它将所有逻辑封装起来,自动将用户输入转换为完整的格式化的提示词。 使用提示模板替代原始字符串格式化的好处在于支持变量的 “部分” 处理,这意味着可以分步骤地格式化变量, 并且可以轻松地将不同地模板组合成一个完整的提示词,以实现更灵活地字符串处理。PromotTemplate不仅能生成包含字符串内容的消息列表,而且能细化每条消息的具体信息,如角色和在列表中的位置, 比如ChatPromptTemplate作为ChatMessageTemplate的一个集合, 每个ChatMessageTemplate都定义了格式化聊天消息的规则,包括角色和内容的指定。
示例:
示例 1:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template("给生产{product}的公司取一个名字。")
res = prompt.format(product = "杯子")
print(res)
给生产杯子的公司取一个名字。
示例 2:
from langchain.prompts import ChatPromptTemplate
template = "你是一个能将{input_language}翻译成{output_language}的助手。"
human_template = "{text}"
chat_prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template),
])
res = chat_prompt.format_message(
input_language = "中文",
output_language = "英文",
text = "我爱编程"
)
print(res)
[
SystemMessage(content="你是一个能将中文翻译成英文的助手。", additional_kwargs={})
HumanMessage(content="我爱编程")
]
输出解析器
简介:
输出解析器将大模型的原始输出转换为下游应用易于使用的格式,主要类型包括:
- 将 LLM 的文本输出转换为结构化信息(例如 JSON、XML 等)
- 将
ChatMessage转换为纯字符串 - 将除消息外的内容(如从自定义函数调用中返回的额外信息)转换为字符串
示例:
编写一个将 以逗号分隔的字符串 转换为 列表 的解析器
from langchain_openai import OpenAI
from langchain.schema import HumanMessage
from langchain.schema import BaseOutputParser
llm = OpenAI()
text = "给生产杯子的公司取三个合适的中文名字,以逗号分隔的形式输出。"
message = [HumanMessage(content = text)]
class CommaSeparatedListOutputParser(BaseOutputParser):
"""
将 LLM 的输出内容解析为列表
"""
def parse(self, text: str):
"""
解析 LLM 调用的输出
"""
return text.strip().split(",")
def main():
llms_response = llm.invoke(text)
print(CommaSeparatedListOutputParser().parse(llms_response))
if __name__ == "__main__":
main()
["杯子之家", "瓷杯工坊", "品质杯子"]
使用 LCEL 进行组合
将上述环节组合成一个 应用,这个应用会将 输入变量 传递给 提示模板 以创建 提示词, 将 提示词 传递给 大模型,然后通过一个输出解析器(可选步骤)处理输出。
LCEL
LCEL 提供了一种声明式的方法,用于简化不同组件的组合过程。随着越来越多 LCEL 组件的推出, LCEL 的功能也在不断扩展。它巧妙地融合了专业编程和低代码编程两种方式的优势。
- 在专业编程方面,LCEL 实现了一种标准化的流程。 它允许创建 LangChain 称之为可运行的或者是规模较小的应用, 这些应用可以结合起来,打造出更大型、功能更强大的应用。 采用这种组件化的方法,不仅能够提高效率,还能使组件得到重复利用。
- 在低代码方面,类似 Flowise 这样的工具有时可能会变得复杂且难以管理, 而使用 LCEL 则方便简单,易于理解。 LCEL 的这些特性使得它成为构建和扩展 LangChain 应用的强大工具, 无论是都对于专业开发者还是希望简化开发流程的用户。
使用 LCEL 有以下好处:
- LCEL 采取了专业编码和低代码结合的方式,开发者可以使用基本组件, 并按照从左到右的顺序将它们串联起来。
- LCEL 不只实现了提示链的功能,还包含了对应用进行管理的特性, 如流式处理,批量调用链、日志记录等。
- LCEL 的这种表达式语言作为一层抽象层,简化了 LangChain 应用的开发, 并为功能及其顺序提供更直观的视觉呈现。 因为 LangChain 已经不仅仅是将一系列提示词简单串联起来, 而是对大模型应用相关功能进行有序组织。
- LCEL 底层实现了 “runnable” 协议, 所有实现该协议的组件都可以描述为一个可被调用、 批处理、流式处理、转化和组合的工作单元。
为了简化用户创建自定义 LCEL 组件的过程,LangChain 引入了 Runnable 对象。
这个对象可以将多个操作序列组合成一个组件,既可以通过编程方式直接调用,
也可以作为 API 对外暴露,这已被大多数组件所采用。Runnable 对象的引入不仅简化了自定义组件的过程,
也使得以标准方式调用这些组件称为可能。Runnable 对象生命的标准接口包括以下几个部分:
stream:以流式方式返回响应数据invoke:对单个输入调用链batch:对一组输入调用链
此外,还包括对标准接口的异步调用方式定义:
astream:以流式方式异步返回响应数据ainvoke:对单个输入异步调用链abatch:对一组输入异步调用链astream_log:在流式返回最终响应的同时,实时返回链执行过程中的每个步骤
不同组件的输入和输出类型:
| 组件 | 输入类型 | 输出类型 |
|---|---|---|
| Prompt | 字典 | PromptValue |
| ChatModel | 单个字符串、聊天消息列表或 PromptValue | ChatMessage |
| LLM | 单个字符串、聊天消息列表或 PromptValue | 字符串 |
| OutputParser | LLM 或 ChatModel 的输出 | 取决于解析器 |
| Retriever | 单个字符串 | 文档列表 |
| Tool | 单个字符串或字典,取决于具体工具 | 取决于工具 |
所有继承自 Runnable 对象的组件都必须包括输入和输出模式说明,
即 input_schema 和 output_schema,用于校验输入和输出数据。
示例
from typing import List
from langchain_community.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser
class CommaSeparatedListOutputParser(BaseOutputParser[List[str]]):
"""
将 LLM 输出内容解析为列表
"""
def parse(self, text: str) -> List[str]:
"""
解析 LLM 调用的输出
"""
return text.strip().split(",")
template = """你是一个能生成以逗号分隔的列表的助手,用户会传入一个类别,
你应该生成该类别下的 5 个对象,并以逗号分隔的形式返回。
只返回以逗号分隔的内容,不要包含其他内容。"""
human_template = "{text}"
chat_prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template),
])
if __name__ == "__main__":
chain = chat_prompt | ChatOpenAI() | CommaSeparatedListOutputParser()
print(chain.invoke({"text": "动物"}))
["狗, 猫, 鸟, 鱼, 兔子"]
使用 LangSmith 进行观测
在 env 文件中设置好下面的环境变量,接着执行一次之前的应用示例,
会发现所有组件的调用过程都自动记录到 LangSmith 中。
可运行序列 RunnableSequence 由 ChatPromptTemplate、
ChatOpenAI 和 CommaSeparatedListOutputParser 三种基本组件组成,
每个组件的输入、输出、延迟时间、token 消耗情况、执行顺序等会被记录下来。
有了这些指标,对应用运行时的状态进行观测就方便了很多,也可以将这些监控记录用于评估 AI 应用的稳定性。
使用 LangServe 提供服务
简介
构建了一个 LangChain 程序,接下来需要对其进行部署,通过接口的方式供下游应用调用,
而 LangServe 的作用就在于此:帮助开发者将 LCEL 链作为 RESTful API 进行部署。
为了创建应用服务器,在 serve.py 文件中定义三样东西:
- 链的定义
- FastAPI 应用声明
- 用于服务链的路由定义,可以使用
langserve.add_routes完成
示例
from typing import List
from langchain.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatOpenAI
from langchain.schema import BaseOutputParser
from langserve import add_routes
from fastapi import FastAPI
# global variable
LOGGING_LABEL = __file__.split('/')[-1][:-3]
# ------------------------------
# 链定义
# ------------------------------
# output parser
class CommaSeparatedListOutputParser(BaseOutputParser[List[str]]):
"""
将 LLM 中逗号分隔格式的输出内容解析为列表
"""
def parse(self, text: str) -> List[str]:
"""
解析 LLM 调用的输出
"""
return text.strip().split(", ")
# prompt template
template = """你是一个能生成都好分隔的列表的助手,用户会传入一个类别,你应该生成改类别下的 5 个对象,
并以都好分隔的形式返回。
只返回一都好分隔的内容,不要包含其他内容。"""
human_template = "{text}"
chat_prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template),
])
# chain
first_chain = chat_prompt | ChatOpenAI() | CommaSeparatedListOutputParser()
# ------------------------------
# 应用定义
# ------------------------------
app = FastAPI(
title = "第一个 LangChain 应用",
version = "0.0.1",
description = "LangChain 应用接口",
)
# ------------------------------
# 添加链路由
# ------------------------------
add_routes(app, first_chain, path = "/first_app")
# 测试代码 main 函数
def main():
import uvicorn
uvicorn.run(app, host = "localhost", port = 8000)
if __name__ == "__main__":
main()
接着执行这个文件:
$ python serve.py
链会在 localhost:8000 上提供服务,可以在终端执行下面的命令:
$ curl -X POST http://localhost:8000/first_app/stream_log \
$ -H "Content-Type: application/json" \
$ -d '{
$ "input": {
$ "text": "动物"
$ },
$ "config": {}
$ }'
输出结果如下:
event: data
data: {"ops":[{"op":"add","path":"/stream_output/-","value":["猫","狗","鸟","鱼","蛇"]}]}
event: data
data: {"ops":[{"op": "replace","path":"/final_output","value":{"output":["猫","狗","鸟","鱼","蛇"]}}]}
event: end
由于每个 LangServe 服务都内置有一个简单的 UI,用于配置和调用应用, 因此可以直接在浏览器中打开地址 http://localhost:8000/first_app/playground 体验,效果是一样的。
上面两种方式可以用于自己测试接口,如果其他人想调用,LangServe 也封装好了,
可以通过 langserve.RemoteRunnable 轻松使用编程方式与服务进行交互:
from langserve import RemoteRunnable
if __name__ == "__main__":
remote_chain = RemoteRunnable("http://localhost:8000/first_app/")
print(remote_chain.invoke({"text": "动物"}))
["狗, 猫, 鸟, 鱼, 兔子"]
模型输入与输出
大模型输入与输出
在传统的软件开发实践中,API 的调用者和提供者通常遵循详细的文档规定, 以确保输出的一致性和可预测性。然而,大模型的运作方式有所不同。 它们更像是带有不确定性的“黑盒”,其输出不仅难以精确控制,而且很大程度上依赖输入的质量。
输入的质量直接影响模型的输出效果。模糊、错误或不相关的输入可能导致输出偏离预期; 相反,清晰、准确的输入有助于模型更好地理解请求,提供更相关的输出。
CRISPE 框架 由开源社区的 Matt Nigh 提出,它可以帮助我们为模型提供详细的背景、 任务目标和输出格式要求,这样的输入使得模型输出更加符合预期,内容更加清晰和详细。
| 概念 | 含义 | 示例 | ||
|---|---|---|---|---|
| CR(capacity and role, 能力与角色) | 希望模型扮演怎样的角色以及角色具备的能力 | 你是一个专门指导初学者编程的经验丰富的老师 | ||
| I(insight, 洞察力) | 完成任务依赖的背景信息 | 根据基础编程概念和最佳实践 | ||
| S(statement, 指令) | 希望模型做什么,任务的核心关键词和目标 | 解释 Python 中变量的作用,并给出实例 | ||
| P(personality, 个性) | 希望模型以什么风格或方式输出 | 使用简洁明了的语言,避免使用复杂的术语 | ||
| E(experiment, 尝试) | 要求模型提供多个答案,任务输出结果数量 | 提供两个不同的例子来展示变量的使用 |
上面描述的输入其实就是 提示词(prompt),提示词在于大模型的交互中扮演着关键角色。 它们是提供给模型的输入文本,可以引导模型生成特定主题或类型的文本, 在自然语言处理任务中,提示词通常作为问题或任务的输入,而模型的输出则是对这些输入的回答或完成任务的结果。
提示模板组件
LangChain 的提示模板组件是一个强大的工具,用于简化和高效地构建提示词。 其优势在于能够让我们 复用大部分静态内容,同时只需动态修改部分变量。
基础提示模板
在程序中引入 PromptTemplate 类,构建一个基础的提示模板。
这个类允许我们定义一个包含变量的模板字符串,从而在需要时替换这些变量。
from langchain.prompts import PromptTemplate
# 创建一个提示模板
template = PromptTemplate.from_template("翻译这段文字:{text},风格:{style}")
# 使用具体的值格式化模板
formatted_prompt = template.format(text = "我爱编程", style = "诙谐有趣")
print(formatted_prompt)
在这个示例中,{text} 和 {style} 时模板中的变量,它们可以被动态替换。
这种方式极大地简化了提示词的构建过程,特别是在处理复杂或重复的提示词时。
PromptTemplate 实际上时 BasePromptTemplate 的一个扩展,它特别实现了一个自己的 format 方法,
这个方法内部使用了 Python 的 f-string 语法。
LangChain 通过其设计,显著提升了提示词创建的灵活性和效率,这对于需要快速迭代和测试多种提示词的场景尤为重要。
自定义提示模板
目标是创建一个模板,它可以生成关于任务信息的 JSON 格式输出。
首先,从 langchain.prompts 引入 StringPromptTemplate 类,
并定义一个继承自此类的自定义模板类 PersonInfoPromptTemplate。
import json
from langchain.prompts import StringPromptTemplate
from langchain.pydantic_v1 import BaseModel, validator
delimiter = "####"
PROMPT = f"""将每个用户的信息用{delimiter}字符分割,并按照 JSON 格式提取姓名、职业和爱好信息。
示例如下:\n"""
class PersonInfoPromptTemplate(StringPromptTemplate, BaseModel):
"""
自定义提示模板,用于生成关于人物信息的 JSON 格式输出
"""
@validator("input_variables")
def validate_input_variables(cls, v):
"""
验证输入变量
"""
if "name" not in v:
raise ValueError("name 字段必须包含在 input_variable 中。")
if "occupation" not in v:
raise ValueError("occupation 字段必须包含在 input_variable 中。")
if "fun_fact" not in v:
raise ValueError("fun_fact 字段必须包含在 input_variable 中。")
return v
def format(self, **kwargs) -> str:
"""
格式化输入,生成 JSON 格式输出
"""
person_info = {
"name": kwargs.get("name"),
"occupation": kwargs.get("occupation"),
"fun_fact": kwargs.get("fun_fact"),
}
return PROMPT + json.dumps(person_info, ensure_ascii = False)
def _prompt_type(self):
"""
指定模板类型
"""
return "person-info"
# 使用模板
person_info_template = PersonInfoPromptTemplate(input_variables = ["name", "occupation", "fun_fact"])
prompt_output = person_info_template.format(
name = "张三 ",
occupation = "软件工程师 ",
fun_fact = "喜欢攀岩"
)
print(prompt_output)
将每个用户的信息用####字符分割,并按照 JSON 格式提取姓名、职业和爱好信息。示例如下:{"name": "张三 ", "occupation": "软件工程师 ", "fun_fact": "喜欢攀岩"}
使用 FewShotPromptTemplate
LangChain 还提供了 FewShotPromptTemplate 组件,用于创建包含少量示例的提示词,
这对于大模型执行新任务或不熟悉的任务特别有帮助。它通过在提示词中提供一些示例来“教”模型如何执行特定任务。
from langchain.prompts import PromptTemplate
from langchain.prompts import FewShotPromptTemplate
# prompt template
example_prompt = PromptTemplate(
input_variables = ["input", "output"],
template = "问题:{input}\n{output}",
)
# 创建 FewShotPromptTemplate 实例,示例中包含了一些教模型如何回答问题的样本
template = FewShowPromptTemplate(
examples = [
{"input": "1+1等于多少?", "output": "2"},
{"input": "3+1等于多少?", "output": "5"},
],
example_prompt = example_prompt,
input_variables = ["input"],
suffix = "问题:{input}",
)
prompt = template.format(input = "5-3等于多少?")
利用已有的少量示例来指导大模型处理类似的任务,这在模型未经特定训练或对某些任务不熟悉的情况下非常有用。 这种方法提高了模型处理新任务的能力,尤其是在数据有限的情况下。
示例选择器
上面提到的小样本学习需要提供少量示例,而示例选择器就是用来决定使用哪些示例的。 自定义示例选择器允许用户基于自定义逻辑从一组给定的示例中选择,这种选择器需要实现两个主要方法。
add_example方法:接收一个示例并将其添加到ExampleSelector中select_examples方法:接收输入变量(通常是用户输入)并返回用于小样本学习提示的一系列示例
LangChain 内置了 4 种选择器,它们都继承自 BaseExampleSelector:
LengthBasedExampleSelectorMaxMarginalRelevanceExampleSelectorSemanticSimilarityExampleSelectorNGramOverlapExampleSelector
输出解析器
LangChain 中的输出解析器负责将语言模型生成的文本转换为更为结构化和实用的格式。 比如,你可能不只需要一段文本,而是需要将其转换为 XML 格式、日期时间对象或者列表等具体的数据结构。
输出解析器的种类繁多,包括单不限于以下几类:
XMLOutputParser:将文本输出转换为 XML 格式DatetimeOutputParser:将文本输出转换为日期时间对象CommaSeparatedListOutputParser:将文本输出转换为列表
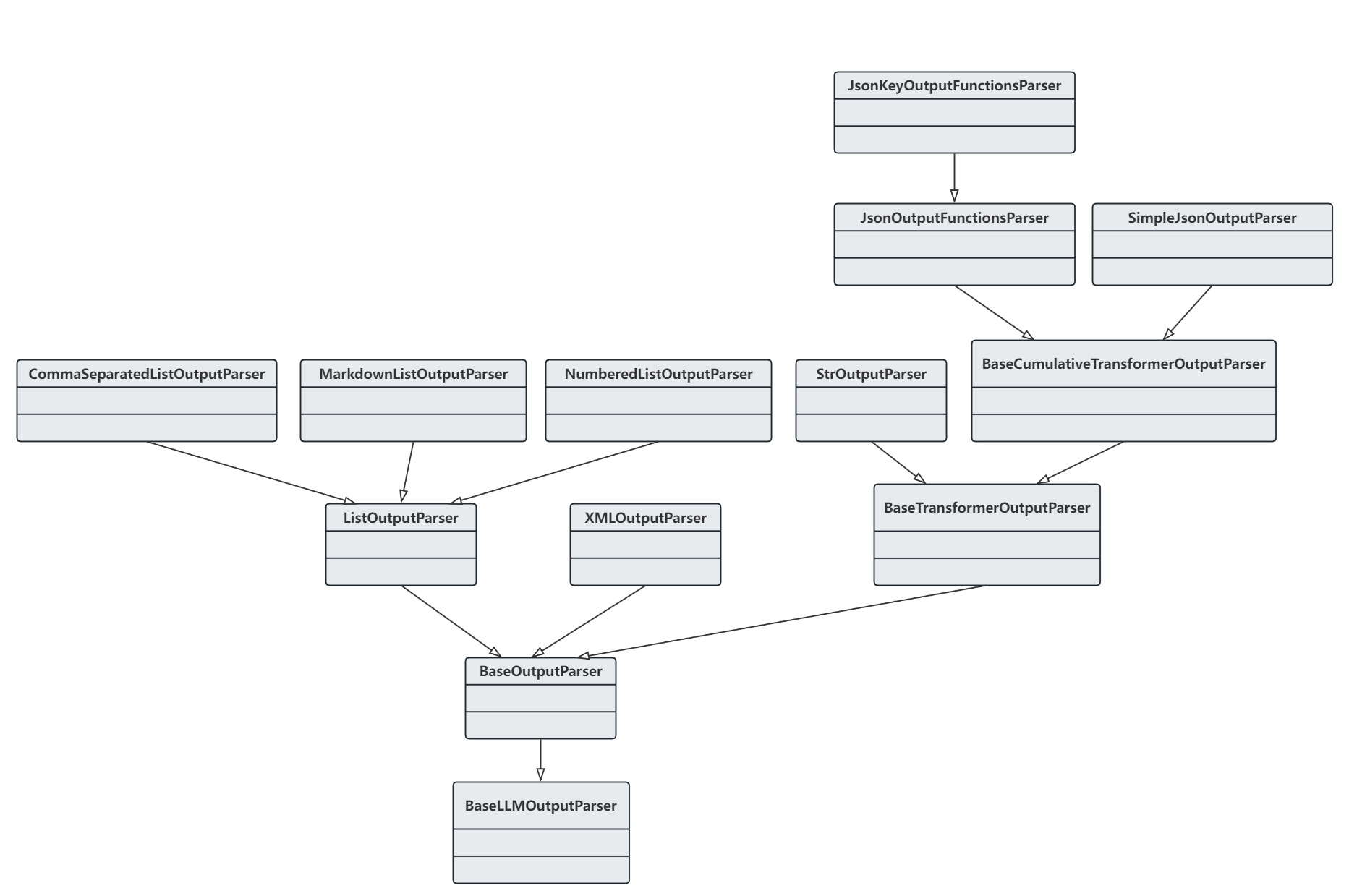
还可以根据需求自定义输出解析器,将文本转换为 JSON 格式、Python 数据类或数据库行等。 自定义输出解析器通常需要实现以下方法:
get_format_instructions:返回一个指令,用于指示语言模型如何格式化输出内容parse:解析语言模型的响应,转换成指定结构
可选方法:
parse_with_prompt:在处理语言模型的输出时,参考最初用于生成该输出的提示词(问题或指令), 可以更有效地理解和调整输出地结果,这在尝试改进或修正模型输出格式时非常有用, 比如明确要求模型输出 JSON 格式的情况。
示例
下面实现一个自定义输出解析器,从自然语言描述中提取花费记录信息用于记账:
import re
import json
from typing import Type
from langchain.schema import BaseOutputParser
from langchain.pydantic_v1 import BaseModel, ValidationError, Field
class CustomOutputParser(BaseOutputParser[BaseModel]):
pydantic_object: Type[T]
def parse(self, text: str) -> BaseModel:
"""
解析文本到 Pydantic 模型
Args:
text (str): 要解析的文本
Returns:
BaseModel: Pydantic 模型的一个实例
"""
try:
# 贪婪搜索第一个 JSON 候选
match = re.search(r"\{.*\}", text.strip(), re.MULTILINE | re.IGNORECASE | re.DOTALL)
json_str = match.group() if match else ""
json_object = json.loads(json_str, strict = False)
return self.pydantic_object.parse_obj(json_object)
except (json.JSONDecodeError, ValidationError) as e:
name = self.pydantic_object.__name__
def get_format_instructions(self) -> str:
"""
获取格式说明
Returns:
格式说明的字符串
"""
schema = self.pydantic_object.schema()
# 移除不必要的字段
reduced_schema = schema
if "title" in reduced_schema:
del reduced_schema["title"]
if "type" in reduced_schema:
del reduced_schema["type"]
# 确保 json 在上下文中格式正确(使用双引号)
schema_str = json.dumps(reduced_schema)
return CUSTOM_FORMAT_INSTRUCTIONS.format(schema = schema_str)
def parse_with_prompt(self):
"""
在处理语言模型的输出时,参考最初用于生成该输出的提示词(问题或指令),
可以更有效地理解和调整输出地结果
"""
pass
@property
def _type(self) -> str:
"""
获取解析器类型
Returns:
str: 解析器的类型字符串
"""
return "custom output parser"
class ExpenseRecord(BaseModel):
amount: float = Field(description = "花费金额")
category: str = Field(description = "花费类别")
date: str = Field(description = "花费日期")
description: str = Field(description = "花费描述")
# 创建 Pydantic 输出解析器实例
parser = CustomOutputParser(pydantic_object = ExpenseRecord)
# 定义获取花费记录的提示模板
expense_template = """
请将这些花费记录在我的账单中。
我的花费记录是:{query}
格式说明:
{format_instructions}
"""
# 使用提示模板创建实例
prompt = PromptTemplate(
template = expense_template,
input_variables = ["query"],
partial_variables = {
"format_instructions": parser.get_format_instructions()
},
)
# 格式化提示词
_input = prompt.format_prompt(query = "昨天白天我去超市花了 45 元买日用品,晚上我又花了 20 元打车。")
# 创建 OpenAI 模型实例
model = OpenAI(model_name = "text_davinci-003", temperature = 0)
# 使用模型处理格式化后的提示词
output = model(_input.to_string())
# 解析输出结果
expense_record = parser.parse(output)
# 遍历并打印花费记录的各个参数
for parameter in expense_record.__field__:
print(f"{parameter}: {expense_record.__dict__[parameter]},
{type(expense_record.__dict__[parameter])}")
TODO
大模型接口
聊天模型
LangChain 提供了一系列基础组件,用于与大模型进行交互。
在这些组件中,特别值得一提的是 BaseChatModel,它专为实现 对话交互 而设计。
这个组件能够理解用户的查询或指令,并生成相应的回复。
与通用语言模型组件相比,BaseChatModel 采用了不同的接口设计。
通用语言模型组件通常采用的是 “输入文本,输出文本” 的模式,
而 BaseChatModel 则以 “聊天消息” 的形式进行输入和输出,这使得它更适合模拟真实的对话场景。
LangChain 支持多种聊天模型,包括但不限于:
- ChatTongyi(阿里通义千问模型)
- QianfanChatEndpoint(百度千帆平台上的模型)
- AzureChatOpenAI(微软云上的 OpenAI 模型)
- ChatGooglePalm(谷歌 PaLM 模型)
- ChatOpenAI(OpenAI 模型)
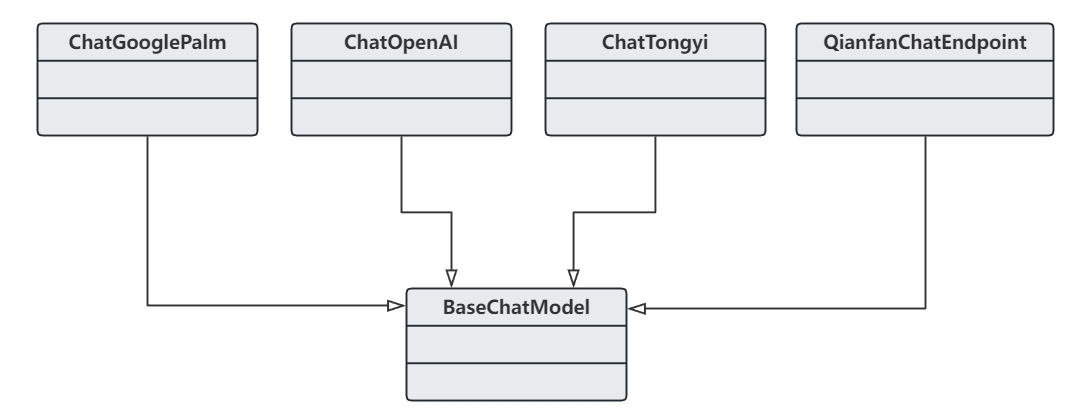
聊天模型还支持 批量模式 和 流模式。批量模式允许同时处理多组消息,适用于需要一次性处理大量对话的场景; 流模式更适合实时处理消息,提供连续的对话交互体验。这些功能使得聊天模型在对话交互方面更加灵活和强大。
聊天模型提示词的构建
在 LangChain 中,聊天模型的提示词构建基于多种类型的信息,而不是单纯的文本。这些消息类型包括下面这些:
AIMessage:大模型生成的消息HumanMessage:用户输入的消息SystemMessage:对话系统预设的消息ChatMessage:可以自定义类型的消息
为了创建这些类型的提示词,LangChain 提供了 MessagePromptTemplate,
它可以结合多个 BaseStringMessagePromptTemplate 来构建一个完整的 ChatPromptTemplate,
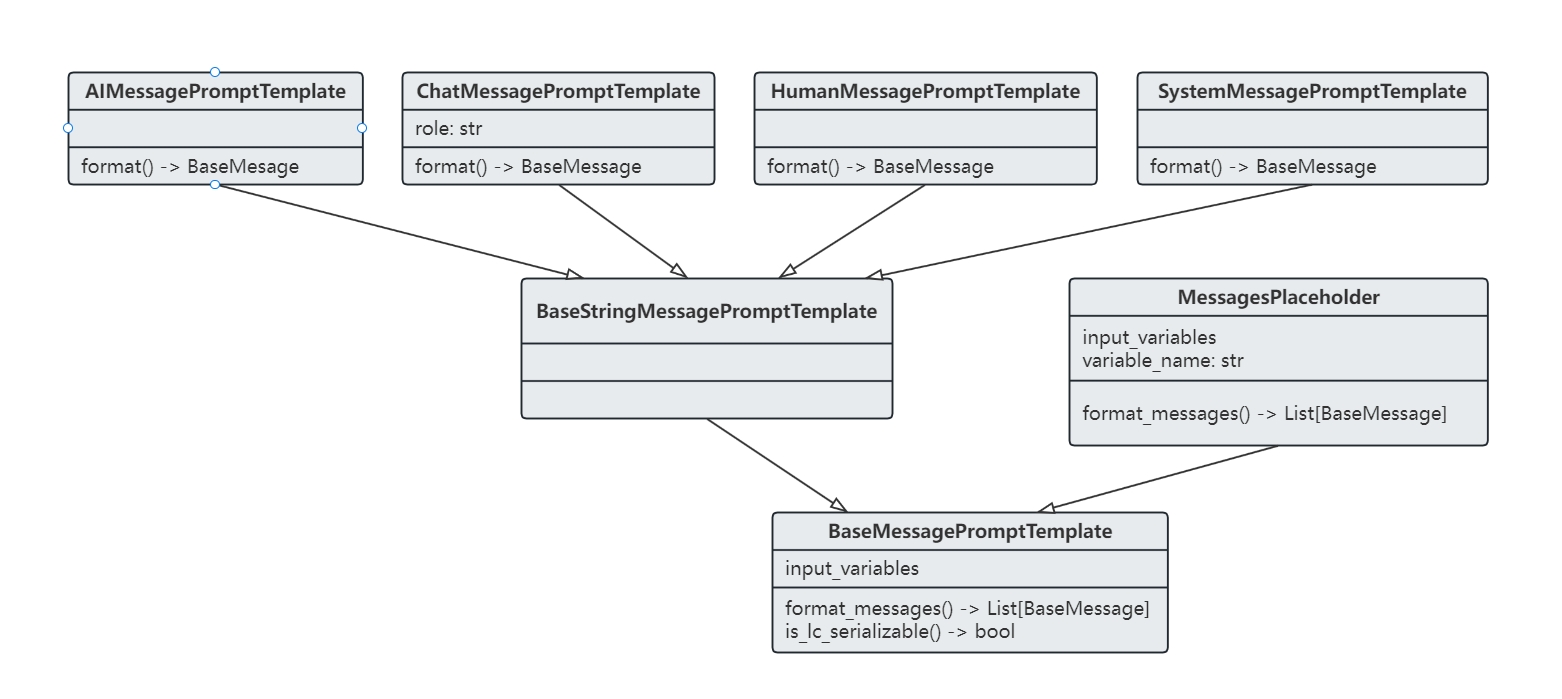
示例
假设我们要构建一个 设定翻译助手 的提示词,可以按照以下步骤操作:
from langchain.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
# 定义对话系统预设消息模版
template = "你是一个翻译助手,可以将{input_language}翻译为{output_language}。"
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
# 定义用户消息模版
human_template = "{talk}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
# 构建聊天提示模版
chat_prompt = ChatPromptTemplate.from_messages([
system_message_prompt,
human_message_prompt,
])
# 生成聊天消息
messages = chat_prompt.format_prompt(
input_language = "中文",
output_language = "英文",
talk = "我爱编程",
)
# 打印生成的聊天消息
for message in messages:
print(message)
('messages', [SystemMessage(content='你是一个翻译助手,可以将中文翻译为英文。'), HumanMessage(content='我爱编程')])
这段代码:
- 首先定义了对话系统预设消息和用户消息的模板,并通过
ChatPromptTemplate将它们组合起来。 - 然后,通过
format_prompt方法生成了两个消息:一个对话系统预设消息和一个用户消息
这样我们就成功地构建了一个适用于聊天模型的提示词。通过这种方式, LangChain 使得聊天模型提示词的创建更加灵活和高效,特别适合需要模拟对话交互的场景。
定制大模型接口
LangChain 的核心组成部分之一是 LLM 组件。当前市场上有多家大模型提供商,如 OpenAI、ChatGLM 和 Hugging Face 等,
为了简化与这些不同提供商的 LLM 进行交互的过程,LangChain 特别设计了 BaseLLM 类。BaseLLM 类提供了一个标准化的接口,
使得开发者能够通过统一的方式与各种 LLM 进行通信。无论它来自哪个提供商。这种设计极大地提高了灵活性和便捷性,
允许开发者轻松集成和切换不同的 LLM,而无须担心底层实现的差异。
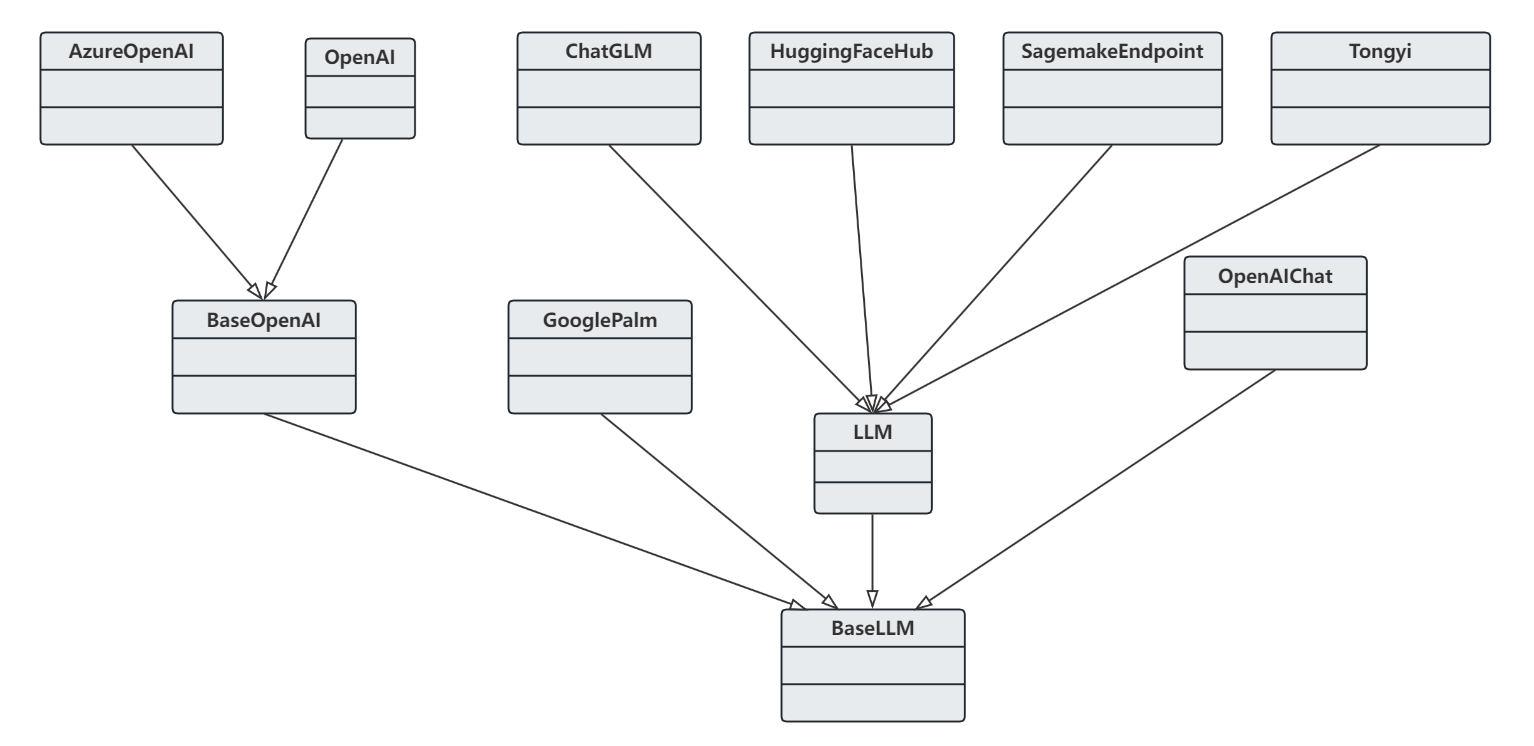
在实际的应用中,我们可能会使用私有部署的大模型,例如公司内部开发的模型。 为此,需要实现一个自定义的 LLM 组件,以便这些模型与 LangChain 的其他组件协同工作。 自定义 LLM 封装器需要实现以下行为和特性:
_call()方法,是与模型交互的核心接口,接收一个字符串和可选的停用词列表,返回一个字符串_identifying_params属性,提供关于该类的信息,有助于打印和调试,返回一个包含关键信息的字典
示例
下面以 GPT4All 模型为例,展示如何实现一个自定义的 LLM 组件。
GPT4All 是一个生态系统,支持在消费级 CPU 和 GPU 上训练和部署大模型。
import os
import sys
import io
import requests
from tqdm import tqdm
from pydantic import Field
from typing import List, Mapping, Optional, Any
from langchain.llms.base import LLM
from gpt4all import GPT4All
class CustomLLM(LLM):
"""
一个自定义的 LLM 类,用于集成 GPT4All 模型
参数:
model_folder_path: (str) 存放模型的文件夹路径
model_name: (str) 要使用的模型名称(<模型名称>.bin)
allow_download: (bool) 是否允许下载模型
backend: (str) 模型的后端(支持的后端: llama/gptj)
n_batch: (int)
n_threads: (int) 要使用的线程数
n_predict: (int) 要生成的最大 token 数
temp: (float) 用于采样的温度
top_p: (float) 用于采样的 top_p 值
top_k: (int) 用于采样的 top_k 值
"""
# 以下是类属性的定义
model_folder_path: str = Field(None, alias = "model_folder_path")
model_name: str = Field(None, alias = "model_name")
allow_download: bool = Field(None, alias = "allow_download")
# 所有可选参数
backend: Optional[str] = "llama"
n_batch: Optional[int] = 8
n_threads: Optional[int] = 4
n_predict: Optional[int] = 256
temp: Optional[float] = 0.7
top_p: Optional[float] = 0.1
top_k: Optional[int] = 40
# 初始化模型实例
gpt4_model_instance: Any = None
def __init__(self, model_folder_path, model_name, allow_download, **kwargs):
super(CustomLLM, self).__init__()
# 类构造函数的实现
self.model_folder_path: str = model_folder_path
self.model_name: str = model_name
self.allow_download: bool = allow_download
# 触发自动下载
self.auto_download()
# 创建 GPT4All 模型实例
self.gpt4_model_instance = GPT4All(
model_name = self.model_name,
model_path = self.model_folder_path,
)
def auto_download(self) -> None:
"""
此方法将会下载模型到指定路径
"""
...
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""
返回一个字典类型,包含 LLM 的唯一标识
"""
return {
"model_name": self.model_name,
"model_path": self.model_folder_path,
**self._get_model_default_parameters
}
@property
def _llm_type(self) -> str:
"""
它告诉我们正在使用什么类型的 LLM
例如:这里将使用 GPT4All 模型
"""
return "gpt4all"
def _call(self, prompt: str, stop: Optional[List[str]] = None, **kwargs) -> str:
"""
这是主要的方法,将在我们使用 LLM 时调用
重写基类方法,根据用户输入的 prompt 来响应用户,返回字符串。
Args:
prompt (str): _description_
stop (Optional[List[str]], optional): _description_. Defaults to None.
"""
params = {
**self._get_model_default_parameters,
**kwargs,
}
# 使用 GPT-4 模型实例开始一个聊天会话
with self.gpt4_model_instance.chat_session():
# 生成响应:根据输入的提示词(prompt)和参数(params)生成响应
response_generator = self.gpt4_model_instance.generate(prompt, **params)
# 判断是否是流式响应模式
if params["streaming"]:
# 创建一个字符串 IO 流来暂存响应数据
response = io.StringIO()
for token in response_generator:
# 遍历生成器生成的每个令牌(token)
print(token, end = "", flush = True)
response.write(token)
response_message = response.getvalue()
response.close()
return response_message
# 如果不是流式响应模式,直接返回响应生成器
return response_generator
扩展模型接口
LangChain 为 LLM 组件提供了一系列有用的扩展功能,以增强其交互能力和应用性能。
- 缓存功能:在处理频繁重复的请求时,缓存功能能够显著节省 API 调用成本,并提高应用程序的响应速度。 例如,如果你的应用需要多次询问相同的问题,缓存可以避免重复调用大模型提供商的 API,从而降低成本并加速处理速度。
- 流式支持:LangChain 为所有 LLM 组件实现了
Runnable对象接口,该接口提供了stream和astream方法, 为大模型提供了基本的流式处理能力。这允许你获取一个迭代器,它将返回大模型的最终响应。 虽然这种方法不支持逐 token 的流式传输,但它确保了代码的通用性,无论使用哪个大模型。 这对于需要异步处理或连续接收数据的应用场景尤为重要。
以上功能强化了 LangChain 与不同 LLM 的交互能力,无论是在成本控制、 性能优化还是满足特定应用需求方面,都提供了强有力的支持。
LCEL
LCEL 特点
- First-clss streaming support
- Async support
- Optimized parallel execution
- Retries and fallbacks
- Access intermediate results
- Input and output schemas
- Seamless LangSmith tracing
LCEL 操作指南
Runnable 接口
为了尽可能轻松地创建自定义链,LangChain 实现了 Runnable 协议。
许多 LangChang 组件都实现了 Runnable 协议,包括聊天模型(chat models)、LLMs、
输出解析器(output parseers)、检索器(retrievers)、提示模板(prompt templates)等。
还有一些用于处理 Runnable 对象的有用概念,如下:
-
Runnable 作为一个标准接口,可以轻松定义链并以标准方式调用它们。标准接口包括:
stream:流式响应块(stream back chunks of the response)invoke:再输入上调用 Chainbatch:再输入列表上调用 Chain
-
异步方法,应该与 asyncio
wait语法一起使用并实现并发:astream:异步响应流式响应块ainvoke:在输入上异步调用 Chainabatch:在输入列表上异步调用 Chainastream_log:除了最终响应外,还对中间步骤进行流式响应处理astream_events:Chain 中发生的 beta 事件
-
输入类型和输出类型尹组件而异:
组件 输入类型 输出类型 PromptDict PromptValueChatModel单个字符串、聊天消息列表或 PromptValueChatMessageLLM单个字符串、聊天消息列表或 PromptValueStringOutputParserLLM 或 ChatModel 的输出 取决于解析器 Retriever单个字符串 Documents 列表 Tool单个字符串或字典,具体取决于工具 取决于工具 -
所有 Runnable 程序都公开输入和输出模式以检查输入和输出:
input_schema:根据 Runnable 的结构自动生成的输入 Pydantic 模型output_schema:根据 Runnable 的结构自动生成的输出 Pydantic 模型
使用 LCEL 构建应用
- Using language models
- Using
PromptTemplatesandOutputParsers - Using LangChain Expression Language (LCEL) to chain components together
- Debugging and tracing your application using LangSmith
- Deploying your application with LangServe
环境配置
LangChain:
$ pip install langchain
LangSmith:
$ export LANGCHAIN_TRACING_V2="true"
$ export LANGCHAIN_API_KEY="..."
# notebook
import os
import getpass
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
构建语言模型应用
依赖安装
$ pip install -qU langchain-openai # OpenAI/Azure/TogetherAI
$ pip install -qU langchain-anthropic # Anthropic
$ pip install -qU langchain-google-vertexai # Google
$ pip install -qU langchain-cohere # Cohere
$ pip install -qU langchain-nvidia-ai-endpoints # NVIDIA
$ pip install -qU langchain-fireworks # FireworksAI
$ pip install -qU langchain-groq # Groq
$ pip install -qU langchain-mistralai # MistralAI
构建应用
#!/usr/bin/env python
# app.py
import os
import getpass
# models
from langchain_open_ai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
from langchain_openai import AzureChatOpenAI
from langchain_google_vertexai import ChatVertexAI
from langchain_cohere import ChatCohere
from langchain import ChatNVIDIA
from langchain_fireworks import ChatFireworks
from langchain_groq import ChatGroq
from langchain_mistralai import ChatMistralAI
# langchain core
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
os.environ["OPENAI_API_KEY"] = getpass.getpass()
os.environ["ANTHROPIC_API_KEY"] = getpass.getpass()
os.environ["AZURE_OPENAI_API_KEY"] = getpass.getpass()
os.environ["GOOGLE_API_KEY"] = getpass.getpass()
os.environ["COHERE_API_KEY"] = getpass.getpass()
os.environ["NVIDIA_API_KEY"] = getpass.getpass()
os.environ["FIREWORKS_API_KEY"] = getpass.getpass()
os.environ["GROQ_API_KEY"] = getpass.getpass()
os.environ["MISTRAL_API_KEY"] = getpass.getpass()
os.environ["TOGETHER_API_KEY"] = getpass.getpass()
__all__ = [
"model",
"prompt_template",
"parser",
"chain",
]
# model
model = ChatOpenAI(model = "gpt-4")
model = ChatAnthropic(model = "claude-3-5-sonnet-20240620")
model = AzureChatOpenAI(
azure_endpoint = os.environ["AZURE_OPENAI_ENDPOINT"],
azure_deployment = os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],
openai_api_version = os.environ["AZURE_OPENAI_API_VERSION"],
)
model = ChatVertexAI(model="gemini-1.5-flash")
model = ChatCohere(model="command-r-plus")
model = ChatNVIDIA(model="meta/llama3-70b-instruct")
model = ChatFireworks(model="accounts/fireworks/models/llama-v3p1-70b-instruct")
model = ChatGroq(model="llama3-8b-8192")
model = ChatMistralAI(model="mistral-large-latest")
model = ChatOpenAI(
base_url = "https://api.together.xyz/v1",
api_key = os.environ["TOGETHER_API_KEY"],
model = "mistralai/Mixtral-8x7B-Instruct-v0.1",
)
# prompt
system_template = "Translate the following into {language}."
prompt_template = ChatPromptTemplate.from_messages(
[
("system", system_template),
("user", "{text}")
]
)
# output parser
parser = StrOutputParser()
# chain
chain = prompt_template | model | parser
def main():
# model
messages = [
SystemMessage(content = "Translate the following from English into Italian"),
HumanMessage(content = "hi!"),
]
model.invoke(messages)
# prompt
result = prompt_template.invoke({
"language": "italian",
"text": "hi",
})
print(result.to_message())
# output parser
result = model.invoke(message)
parser.invoke(result)
# chain
chain.invoke({
"language": "italian",
"text": "hi",
})
if __name__ == "__main__":
main()
部署语言模型应用
安装依赖
$ pip install "langserve[all]"
Server
#!/usr/bin/env python
# serve.py
from fastapi import FastAPI
from langserve import add_routes
from app import model, prompt_template, parser, chain
# app
ap = FastAPI(
title = "LangChain Server",
version = "1.0",
description = "A simple API server using LangChain's Runnable interfaces",
)
# adding chain route
add_routes(
app,
chain,
path = "/chain",
)
def main():
import uvicorn
uvicorn.run(app, host = "localhost", port = 8000)
if __name__ == "__main__":
main()
Server run
$ python serve.py
Client
from langserve import RemoteRunnable
remote_chain = RemoteRunnable("http://localhost:8000/chain/")
remote_chain.invoke({
"language": "italian",
"text": "hi",
})
链的构建
链简介
在 LangChain 中,链是一系列组件的有序组合,用于执行特定任务。无论是处理简单的文本还是复杂的数据, 链都能发挥重要作用。例如,你可以构建一条链来处理用户输入,将其转换为所需格式,然后保存或进一步处理。
LangChain 提供了两种实现链的方式:传统的 Chain 编程接口和最新的 LCEL。 虽然两者可以共存,但官方推荐使用 LCEL,因为它提供了更直观的语法, 并支持流式传输、异步调用、批处理、并行化和重试等高级功能。LCEL 的主要优势在于其直观性和灵活性。 开发者可以轻松地将输入提示模板、模型接口和输出解析器等模块组合起来,构建出高度定制化地处理链。 下面降通过具体的示例来展示如何利用 LCEL 构建有效且实用的链。
Runnable 对象接口
前面提到的 提示模版组件对象 BasePromptTemplate、大模型接口对象 BaseLanguageModel 和 输出解析器对象 BaseOutputParser 都实现了关键接口:Runnable 对象接口。
这些接口的设计旨在让不同的组件能够灵活地串联起来,形成一条功能强大的处理链。
通过实现 Runnable 对象接口,组件之间能够确保兼容性,并以模块化的方式进行组合使用。
Runnable 对象接口是一个可以被调用、批量处理、流式处理、转换和组合的工作单元,
它通过 input_schema 属性、output_schema 属性和 config_schema 方法来提供关于组件输入、
输出和配置的结构化信息。这些属性和方法使得组件能够清晰地定义它们所需的输入格式、
期望的输出格式以及配置选项,从而简化组件间的集成和交互。下面将介绍这些主要方法和属性,
以及如何利用它们来构建高效的处理链。
invoke/ainvoke:它接收输入并返回输出batch/abatch:这个方法允许对输入列表进行批量处理,返回一个输出列表stream/astream:这个方法提供了流式处理的能力,允许逐块返回响应,而不是一次性返回所有结果astream_log:这个方法用于逐块返回响应过程的中间结果和日志记录输出
带有 a 前缀的方法是异步的,默认情况下通过 asyncio 的线程池执行对应同步方法,
可以重写以实现原生异步。所有方法都接收一个可选的 config 参数,用于配置执行、
添加用于跟踪和调试的标签和元数据等。
Runnable 对象接口的声明:
class Runnable(Generic[Input, Output], ABC):
...
@property
def intput_schema(self) -> Type[BaseModel]:
...
@property
def output_schema(self) -> Type[BaseModel]:
...
def config_schema(
self, *,
include: Optional[Sequence[str]] = None
) -> Type[BaseModel]:
...
@abstractmethod
def invoke(
self,
input: Input,
config: Optional[RunnableConfig] = None,
**kwargs: Any
) -> Output:
...
async def ainvoke(
self,
input: Input,
config: Optional[RunnableConfig] = None,
**kwargs: Any
) -> Output:
...
def batch(self, ...) -> List[Output]:
...
async def abatch(self, ...) -> List[Output]:
...
def stream(self, ...) -> Iterator[Output]:
...
async def astream(self, ...) -> AsyncIterator[Output]:
...
async def astream_log(
self,
input: Any,
...
) -> Union[AsyncIterator[RunLogPatch], AsyncIterator[RunLog]]:
...
在 LangChain 中,为了有效地组合 Runnable 对象,有两个主要的工具:
RunnableSequenceRunnableSequence用于顺序调用一系列Runnable对象。 它将前一个Runnable对象的输出作为下一个的输入,从而形成一条处理链。 可以实用管道运算符|或者将Runnable对象的列表传递给RunnableSequence来构造这样的序列。
RunnableParallelRunnableParallel则用于并行调用多个Runnable对象。它会为每个Runnable对象提供相同的输入, 从而实现任务的并行处理。可以在序列中实用字典字面值或者直接传递字典给RunnableParallel来构造并行处理链。
from langchain.schema.runnable import RunnableLambda
def test():
# 使用 | 运算符构造的 RunnableSequence
sequence = RunnableLambda(lambda x: x - 1) | RunnableLambda(lambda x: x * 2)
print(sequence.invoke(3)) # 4
print(sequence.batch([1, 2, 3])) # [0, 2, 4]
# 包含使用字典字面值构造的 RunnableParallel 的序列
sequence = RunnableLambda(lambda x: x * 2) | {
'sub_1': RunnableLambda(lambda x: x - 1),
'sub_2': RunnableLambda(lambda x: x - 2),
}
print(sequence.invoke(3)) # {'sub_1': 5, 'sub_2':4}
在 LangChain 中,有六种基础组件实现了 Runnable 对象接口,下表中列出了这些组件及其输入和输出格式:
| 组件 | 输入类型 | 输出类型 |
|---|---|---|
| Prompt | 字典 | PromptValue |
| ChatModel | 单个字符串、聊天消息列表或 PromptValue | ChatMessage |
| LLM | 单个字符串、聊天消息列表或 PromptValue | 字符串 |
| OutputParser | LLM 或 ChatModel 的输出 | 取决于解析器 |
| Retriever | 单个字符串 | 文档列表 |
| Tool | 单个字符串或字典,取决于具体工具 | 取决于工具 |
schema
所有继承 Runnable 对象的组件都需要接收特定格式的输入,这被称为输入模式(input_schema)。
另外,为了帮助开发者了解每个组件所需的具体输入模式,LangChain 提供了一个基于 Pydantic 的动态生成模型, 这个模型详细描述了输入数据的结构,包括必需的字段及其数据类型。 开发者可以通过调用 Pydantic 模型的
.schema方法来获取输入模式的 JSON Schema 表示。这种表示形式为开发者提供了一个结构化的视图,使得理解和实现正确的输入格式变得简单直观。
这里以 Prompt 为例:
from langchain_community.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema import StrOutputParser
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
def test():
# 创建一个 PromptTemplate 实例,用于生成提示词
prompt = PromptTemplate("给生产{product}的公司取一个名字。")
# 创建 Runnable 序列,包括上述提示模板、聊天模型和字符串输出解析器
runnable = prompt | ChatOpenAI() | StrOutputParser()
# 打印输入模式的 JSON Schema
print(runnable.input_schema.schema())
# 打印输出模式的 JSON Schema。这说明了 Runnable 执行后的输出数据结构
print(runnable.output_schema.schema())
输入内容为一个 PromptInput 对象,属性为 product,类型为字符串:
{
'title': 'PromptInput',
'type': 'object',
'properties': {
'product': {
'title': 'Product',
'type': 'string',
}
}
}
输出内容格式化过程和输入同理,下面为一个 StrOutputParserOutput 对象,输出结果类型是字符串:
{
'title': 'StrOutputParserOutput',
'type': 'string'
}
invoke
LangChain 的 invoke 接口是一个核心功能,它是一个标准化的方法,用于与不同的语言模型进行交互。
这个接口的主要作用是向语言模型发送输入(问题或命令),并获取模型的响应(回答或输出)。
在具体的使用场景中,可以通过 invoke 方法向模型提出具体的问题或请求,该方法将返回模型生成的回答。
这个接口的统一性使得 LangChain 能够以一致的方式访问不同的语言模型,无论它们背后的具体实现如何。
ainvoke 方法是异步版本的 invoke,
它利用 asyncio 库中的 run_in_executor 方法在一个单独的线程中运行 invoke 方法,
以实现非阻塞调用。这种方法常用于将传统的同步代码(阻塞调用)转换为异步调用,
从而提高程序的响应性和并发性能。这种实现方式适用于 LangChain 中的多个组件,比如,在 Tool 类中,
ainvoke 作为默认实现,支持异步代码的使用,它通过在一个线程中调用 invoke 方法,
使得函数可以在工具被调用时运行。
以下是 ainvoke 方法声明:
async def ainvoke(self, input: Input, config: Optional[Runnable] = None, **kwargs: Any) -> Output:
"""
* 使用 asyncio.get_running_loop 获取当前运行的事件循环
* asyncio 是 Python 的内置库,用于编写单线程的并发代码
* run_in_executor 方法允许在一个单独的线程中运行一个阻塞的函数调用
"""
return await asyncio.get_running_loop().run_in_executor(
# 第一个参数 None 表示使用默认的 executor,即默认的线程池
None,
# 第二个参数是一个使用 functools.partial 创建的函数,partial 允许你预先设置函数的一些参数
partial(self.invoke, **kwargs),
# 后续的参数 input 和 config 将被传递给 partial 函数
input,
config
)
stream
LangChain 的 stream 接口提供了一种流式处理机制,它允许在处理过程中实时返回数据,
无须等待整个数据处理流程完成。这种特性在处理大量数据或需要即时反馈的应用场景中尤为关键。
from langchain_community.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
def test():
# 初始化 ChatOpenAI 模型实例
model = ChatOpenAI()
# 创建一个 PromptTemplate 实例
prompt = PromptTemplate.from_template("讲一个{story_type}的故事。")
# 创建一条处理链(Runnable),包含上述提示模板和 ChatOpenAI 聊天模型
runnable = prompt | model
# 使用流式处理生成故事
for s in runnable.stream({"story_type": "悲伤"}):
print(s.content, end = "", flush = True) # end="" 确保输出连续,无额外换行
像上面这种场景,用户期望的输出内容是篇幅较长的故事,为了不让用户等待太久,就可以利用 stream 接口实时输出。
astream 方法是异步版本的 stream,astream 的默认实现调用了 ainvoke。
astream 函数是一个异步生成器(AsyncGenerator),它使用 yield 语句产生从 ainvoke 方法返回的结果。
这种设计模式使得函数能够以流的形式逐步产生输出,而不是一次性返回所有结果。
这对于处理需要逐步获取结果的长时间运行的任务特别有用,例如,在处理大模型生成的文本时,
可以逐段获取输出,而不必等待整个文本生成完毕。
以下是 astream 方法声明:
async def astream(self,
input: Input,
config: Optional[RunnableConfig] = None,
**kwargs: Optionalp[Any]) -> AsyncIterator[Output]:
# 使用 await 关键字调用 ainvoke 方法
yield await self.ainvoke(input, config, **kwargs)
batch
LangChain 的 batch 方法是一种高效的批处理功能,它允许同时处理多个输入。
当调用 batch 方法时:
- 首先会检查输入是否存在。如果输入为空,batch 方法会直接返回一个空列表。
- 接着,根据输入的数量,
batch方法会创建一个配置列表,并定义一个局部函数invoke来处理单个输入。 - 最后,利用执行器(executor)并行处理这些输入,从而显著提高处理效率。
对于单个输入的情况,batch 方法会直接调用 invoke 函数进行处理。
这种批处理方式在处理大量请求时特别高效,因为它能够充分利用并行处理的优势,大幅提高整体性能。
abatch 方法是 batch 方法的异步版本,它同样处理多个输入,但所有的调用都是异步的,
使用 gather_with_concurrency 函数并发执行所有的异步调用,并等待它们全部完成。
# TODO
def batch():
pass
astream_log
astream_log 是 LangChain 中的一个异步方法,它支持流式处理并记录执行过程中的每一步变化。
该方法利用 LogStreamCallbackHandler 创建一个日志流,允许开发者根据特定条件包含或排除某些类型的日志。
通过异步迭代流式输出,astream_log 生成日志对象(RunLogPatch)或状态对象(RunLog),
这些对象对于跟踪和分析 Runnable 组件的行为非常有有帮助。
这种方法使得开发者能够实时监控和理解 Runnable 组件的执行情况,从而更好地调试和优化 AI 应用。
# TODO
async def astream_log():
pass
回调机制
参考和资源
- 《LangChain 编程-从入门到实践》
- crewAI
- LangChain
- LlamaIndex
- SK
- AutoGPT