统计性时域分析
统计性时域分析主要是横向挖掘时序的内生相关关系,其中,描述时序内生相关关系的两个重要统计指标是:
- 自协方差函数:就是协方差,只不过
$X_{1}$和$X_{2}$对应的是时间序列$X_{t_{1}}$和$X_{t_{2}}$。 之所以前面有个“自”,是因为时间序列$X_{t_{1}}$和$X_{t_{2}}$是时间序列$T$下的子序列, 只不过存在 lag(平移系数)的区别,因此是自己比较自己,形象地讲就是度量自己过去的行为对自己的影响
$$cov(X_{t_{1}}, X_{t_{2}}) = E\Big[(X_{t_{1}} - \mu_{t_{1}})(X_{t_{2}} - \mu_{t_{2}})\Big]$$
- 自相关系数:就是相关系数。分母为两个时间序列的标准差的乘积
$$\begin{align} \rho(X_{t_{1}}, X_{t_{2}}) &= \frac{cov(X_{t_{1}}, X_{t_{2}})}{\sigma_{t_{1}}\sigma_{t_{2}}} \\ &=\frac{E\Big[(X_{t_{1}} - \mu_{t_{1}})(X_{t_{2}} - \mu_{t_{2}})\Big]}{\sqrt{(X_{t_{1}} - \mu_{t_{1}})^{2}}\sqrt{(X_{t_{2}} - \mu_{t_{2}})^{2}}} \end{align}$$
时间序列自回归
统计性时域时间序列回归的问题,并不是普通的回归问题,而是自回归。
一般回归
一般的回归问题,比如最简单的线性回归模型:
$$Y=a X_{1} + b X_{2} + \varepsilon$$
讨论的是因变量 $Y$ 关于两个自变量 $X_1$ 和 $X_2$ 的线性关系,
目的是找出最优系数 $a^{*}$ 和 $b^{*}$,
使得预测值 $y=a^{*} X_{1} + b^{*} X_{2}$ 逼近真实值 $Y$。
自回归
自回归模型中,自变量 $X_1$ 和 $X_2$ 都为 $Y$ 本身,也就是说,
现在的 $Y$ 值由过去的 $Y$ 值决定,自变量和因变量都为自身,因此这种回归叫自回归。
$$Y_{t}=a Y_{t-1}+ b Y_{t-2} + \varepsilon$$
其中:
$Y_{t-1}$为$Y$在$t-1$时刻的值$Y_{t-2}$为$Y$在$t-2$时刻的值
自回归模型都有着严格理论基础,讲究时间的平稳性,需要对时间序列进行分析才能判断是否能使用此类模型。 这些模型对质量良好的时间序列有比较高的精度。传统的自回归模型有:
- 自回归模型(AR, Auto Regressive)
- 移动平均模型(MA, Moving Average)
- 自回归移动平均模型(ARMA, Auto-Regressive Moving Average)
- 差分自回归移动平均模型(ARIMA)
- 指数平滑(Exponential Smoothing)
时间序列统计模型
统计模型
传统时间序列预测模型,通常指用于时间序列分析/预测的统计学模型, 比如常用的有 AR、MA、ARMA、ARIMA、指数平滑预测法(ES)等。 传统的参数预测方法可以分为两种:
- 一种拟合标准时间序列的参数方法,包括移动平均(MA)、指数平滑(ES) 等
- 另一种是考虑多因素组合的参数方法,即 AR、MA、ARMA、ARIMA 等模型
这类方法比较适用于小规模,单变量的预测,比如某门店的销量预测等。 这类方法一般是统计或者金融出身的人用的比较多,对统计学或者随机过程知识的要求比较高。 而在数据挖掘的场景中比较难适用,因为需要大量的参数化建模。 比如有一个连锁门店的销售数据,要预测每个门店的未来销量, 用这类方法的话就需要对每个门店都建立模型,这样就很难操作了。
建模方法
总的来说,基于此类方法的建模步骤是:
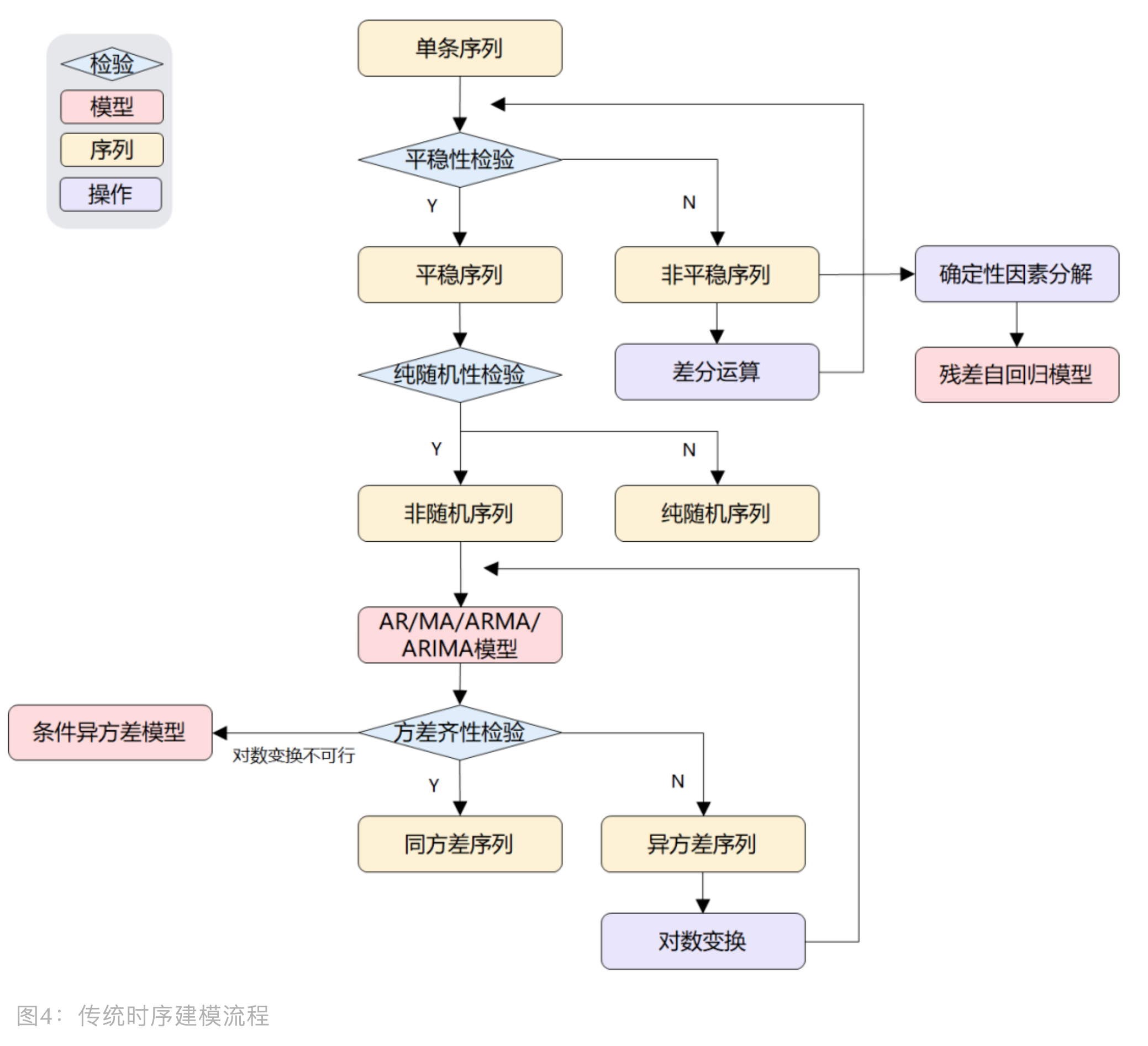
优缺点及意义
优点:
- 复杂度低、计算速度快
缺点:
- 由于真实应用场景的复杂多样性(现实世界的时间序列往往受到各种不同因素的限制与影响,而难以预测), 比如受到营销计划、自然灾害等的影响
- 传统的单一统计学模型的准确率相对来说会比机器学习差一些,而机器学习模型或者更复杂的集成模型会有更好的效果
传统时间序列预测模型也有其重要的意义,比如:
- 可以作为预测的 baseline model,为项目提供一个准确率的基准线,来帮助评估其他模型的提升
- 由于其较好的可解释性,可以用来对数据进行前置清洗,可以帮助剔除一些异常值, 比如因服务器故障或者业务线逻辑调整产生的异常值
- 可以作为集成模型中的一块,参与时序集成模型的训练
- 可以提供一个预测结果的合理的范围,使用这个合理的范围, 在黑盒模型最后输出结果时,帮忙进行后置校准,从而使预测系统更加稳定
时间序列分析总结
传统统计时域分析是围绕着 ARMA 模型不断调整。因为 ARMA 模型的使用前提是平稳非随机序列, 因此传统时序要做三点检验:
- 平稳性
- 非随机性
- 方差齐性
- 感觉方差齐性检验可以纳入平稳性检验里面
如果序列非平稳(包括非方差齐性),可以透过对时序自身的转换
- 差分运算
- 对数变换
- …
或改进 ARMA 模型,例如:
- 差分自回归移动平均(Auto-Regressive Integrated Moving Average, ARIMA)
- 残差自回归模型(Residual Auto-Regressive, RAR)
- 自回归条件异方差模型(Auto-Regressive Conditional Heteroscedastic, ARCH)
- …
而无论是残差序列还是方差序列,本质上也是时间序列,只要存在自相关性, 那么 ARMA 模型就可以用,于是出现了残差自回归模型和自回归条件异方差模型。
ARMA 模型适用于单条时序自身训练和预测的任务,人工成本是必要的。 虽然只有一条序列,但恰恰因为只有单条序列,想要挖掘出内部有价值的信息是令人头疼的, ARMA 从时序内生关系出发,对序列进行统计学上的建模,在今天也是具有参考意义的。