情感分析简介
情感分析介绍
随着互联网的飞速发展, 越来越多的互联网用户从单纯的信息受众, 变为互联网信息制造的参与者。互联网中的博客、微博、论坛、 评论等这些主观性文本可以是用户对某个产品或服务的评价, 或者是公众对某个新闻事件或者政策的观点。
潜在的消费者在购买某个产品或者服务时获取相关的评论可以作为决策参考, 政府部门也可以浏览公众对新闻事件或政策的看法了解舆情。 这些主观性的文本对于决策者制定商业策略或者决策都非常重要, 而以往仅靠人工监控分析的方式不仅耗费大量人工成本, 而且有很强的滞后性。 因此采用计算机自动化情感分析称为目前学术界和工业界的大趋势。 目前, 情感分析在实际生产场景中得到越来越多的应用。
情感分析技术要点
- 舆情数据舆情分析
- 分类算法
- RNN
- LSTM
情感分析应用
- (1)电子商务
- 情感分析最常用的领域就是电子商务。例如淘宝、京东, 用户在购买一件商品以后可以发表他们关于该商品的体验。 通过分配登记或者分数, 这些网站能够为产品和产品的不同功能提供简要的描述。 客户可以很容易产生关于整个产品的一些建议和反馈。通过分析用户的评价, 可以帮助这些网站提高用户满意度, 完善不到位的地方。
- (2)舆情分析
- 无论是政府还是公司, 都需要不断监控社会对于自身的舆论态度。来自消费者或者任何第三方机构的正面或者负面的新闻报道, 都会影响到公司的发展。相对于消费者, 公司更看重品牌声誉管理(BRM)。如今, 由于互联网的放大效应, 任何一件小的事情都可能发酵为大的舆论风暴, 及时感知舆情, 进行情感分析有助于及时公关, 正确维护好公司的品牌, 以及产品和服务评价。
- (3)市场呼声
- 市场呼声是指消费者使用竞争对手提供的产品与服务的感受。及时准确的市场呼声有助于取得竞争优势, 并促进新产品的开发。尽早检测这类信息有助于进行直接、关键的营销活动。 情感分析能够为企业实时获取消费者的意见。这种实时的信息有助于企业制定新的营销策略, 改进产品功能, 并预测产品故障的可能。
- (4)消费者呼声
- 消费者呼声是指个体消费者对产品或服务的评价。这就需要对消费者的评价和反馈进行分析。 VOC是指客户体验管理中的关键要素。VOC 有助于企业抓住产品开发的新机会。 提取客户意见同样也能帮助企业确定产品的功能需求和一些关于性能、成本的肺功能需求。
情感分析的基本方法
根据分析载体的不同, 情感分析会涉及到很多主题, 包括电影评论、商品评论, 以及新闻和博客等的情感分析。 大多数情感分析研究都使用机器学习方法。
- 对情感分析的研究到目前为止主要集中在两个方面:
- 识别给定的文本实体是主观的还是客观的
- 识别主观的文本的极性
- 文本可以划分为积极和消极两类,
- 或者积极、消极、中性(或者不相关)的多类
- 情感分析的方法主要分为:
- 词法分析
- 基于机器学习的分析
- 混合分析
词法分析
词法分析运用了由预标记词汇组成的字典, 使用词法分析器将输入文本转换为单词序列。 将每一个新的单词与字典中的词汇进行匹配。如果有一个积极的匹配, 分数加到输入文本的分数总池中。 相反, 如果有一个消极的匹配, 输入文本的总分会减少。虽然这项技术感觉有些业余, 但已被证明是有价值的。 词法分析技术的工作方式如下图:
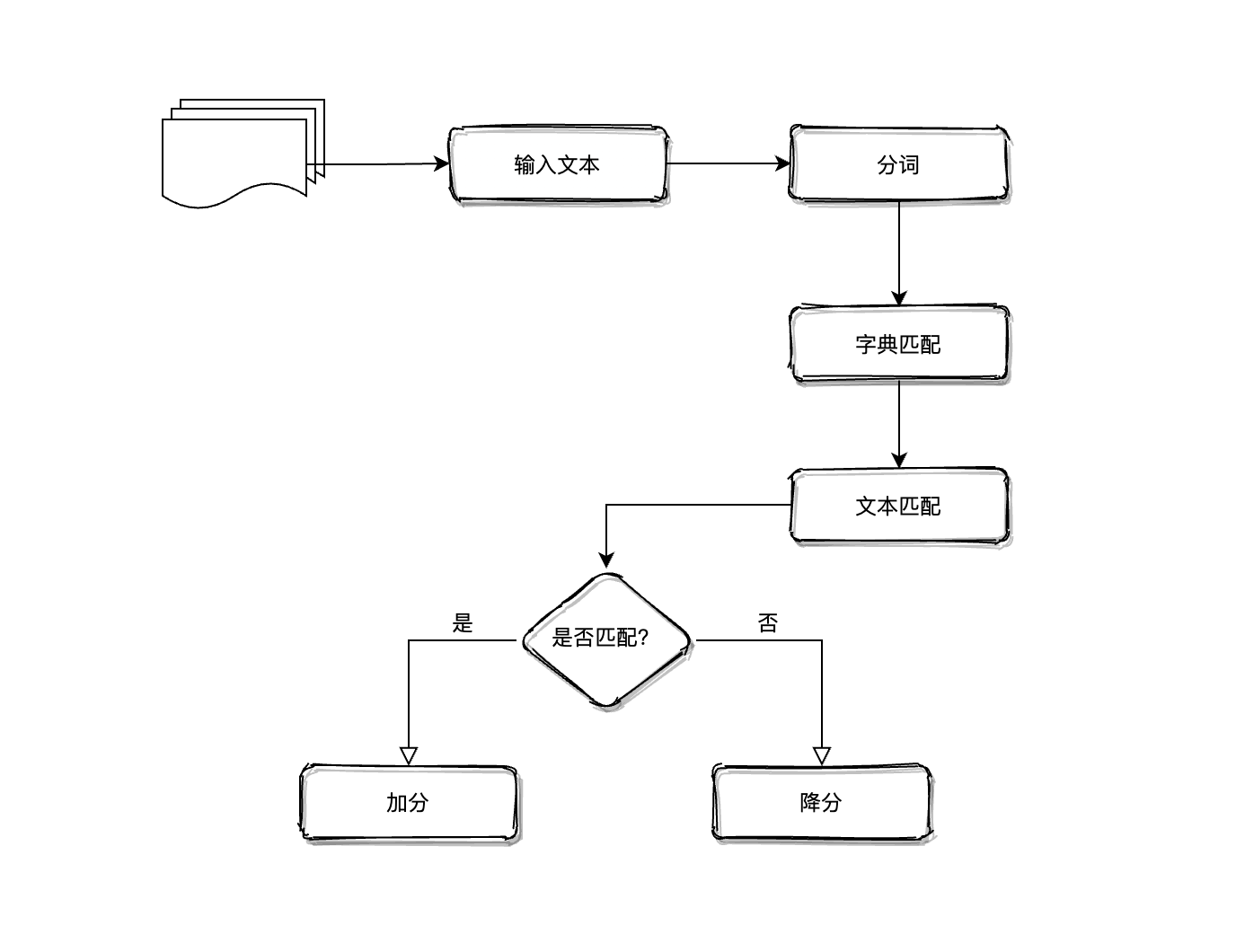
文本的分类取决于文本的总得分。目前有大量的工作致力于度量词法信息的有效性。对于单个短语, 通过手动标记词汇(仅包含形容词)的方式, 大概能达到 85% 的准确性。这是由评价文本的主观性所决定的。
词法分析也存在一个不足:其性能(时间复杂度和准确率)会随着字典大小(词汇的数量)的增加而迅速下降。
机器学习方法
在情感分析中, 主要使用的是监督学习方法。在训练过程中, 需要提供一个标记语料库作为训练数据。 分类器使用一系列特征向量对目标数据进行分类。
通常来说, unigram(单个短语)、bigrams(两个连续的短语)、trigrams(三个连续的短语)都可以被选为特征向量。 当然还有其他一些特征, 如积极词汇的数量、消极词汇的数量、文档的长度等。
支持向量机(SVM)、朴素贝叶斯(NB)算法、卷积神经网络(CNN)等都可以作为分类器使用。
机器学习技术面临很多挑战:分类器的设计、训练数据的获取、对一些未见过的短语的正确解释。 相比词汇分析方法, 它在字典大小呈指数增长的时候依然工作得很好。
混合分析
情感分析研究的进步吸引大量研究者开始探讨将两中方法进行组合的可能性, 即可以利用机器学习方法的高准确性, 又可以利用词法分析快速的特点。
- 有研究者利用由两个词组成的词汇和一个未标记的数据, 将这些由两个词组成的词汇划分为积极的类和消极的类。 利用被选择的词汇集合中的所有单词产生一些伪文件。然后计算伪文件与未标记文件之间的余弦相似度。 根据相似度将该文件划分为积极的或消极的情感。之后这些训练数据集被送入朴素贝叶斯分类器进行训练。
- 有研究者使用背景词法信息作为单词类关联, 提出了一种统一的框架, 设计了一个 Polling 多项式分类器(PMC, 多项式朴素贝叶斯), 在训练中融入了手动标记数据, 利用词法之后后性能得到了提高。
情感分析示例
- 在 NLP 中, 情感分析是 一段文字 表达的 情绪状态
- 一段文本[输入]:可以是一个句子、一个段落、一个文档
- 情感状态[输出]:可以是两类, 也可以是多类
- 在 NLP 问题中, 情感分析可以被归类为文本分类问题, 主要涉及两个问题:
- 文本表达(特征提取)
- BOW (词袋模型)
- topic model(主题模型)
- word2vec
- 文本分类
- SVM
- NB
- LR
- CNN
- RNN
- LSTM
- 文本表达(特征提取)
- 情感分析的任务是分析一句话是积极、消极还是中性的, 可以把任务分为 5 个部分:
- (1)训练或者载入一个词向量生成模型
- (2)创建一个用于训练集的 ID 矩阵
- (3)创建 LSTM 计算单元
- (4)训练分类模型
- (5)测试分类模型
载入数据
IMDB 情感分析数据
- 25000 条已标注的电影评价, 满分 10 分
- 25000 条已标注的电影评分, 满分 10 分
评价标签阈值表
| 标签 | 分数 |
|---|---|
| 负面评价 | $\leq 4 |
| 正面评价 | $\geq 7 |
示例:
- 数据加载
import os
from os.path import isfile, join
import re
import numpy as np
from random import randint
import tensorflow as tf
import config
batch_size = 24
lstm_units = 64
num_labels = 2
iterations = 100
lr = 0.001
def load_wordsList():
"""
载入词典, 该词典包含 400000 个词汇
"""
wordsList = np.load(os.path.join(config.root_dir, 'wordsList.npy'))
print("-" * 20)
print('载入word列表...')
print("-" * 20)
wordsList = wordsList.tolist()
wordsList = [word.decode('UTF-8') for word in wordsList]
return wordsList
def load_wordVectors():
"""
载入已经训练好的词典向量模型, 该矩阵包含了的文本向量, 维度: (400000, 50)
"""
wordVectors = np.load(os.path.join(config.root_dir, 'wordVectors.npy'))
print("-" * 20)
print('载入文本向量...')
print("-" * 20)
return wordVectors
def load_idsMatrix():
"""
"""
ids = np.load(os.path.join(config.root_dir, 'idsMatrix.npy'))
return ids
def postive_analysis():
"""
载入正面数据集
"""
pos_files = [config.pos_data_dir + f for f in os.listdir(config.pos_data_dir) if isfile(join(config.pos_data_dir, f))]
num_words = []
for pf in pos_files:
with open(pf, "r", encoding='utf-8') as f:
line = f.readline()
counter = len(line.split())
num_words.append(counter)
print("-" * 20)
print('正面评价数据加载完结...')
print("-" * 20)
num_files = len(num_words)
print('正面评价数据文件总数', num_files)
print('正面评价数据所有的词的数量', sum(num_words))
print('正面评价数据平均文件词的长度', sum(num_words) / len(num_words))
return pos_files
def negtive_analysis():
"""
载入负面数据集
"""
neg_files = [config.neg_data_dir + f for f in os.listdir(config.neg_data_dir) if isfile(join(config.neg_data_dir, f))]
num_words = []
for nf in neg_files:
with open(nf, "r", encoding='utf-8') as f:
line = f.readline()
counter = len(line.split())
num_words.append(counter)
print("-" * 20)
print('负面评价数据加载完结...')
print("-" * 20)
num_files = len(num_words)
print('负面评价数据文件总数', num_files)
print('负面评价数据所有的词的数量', sum(num_words))
print('负面评价数据平均文件词的长度', sum(num_words) / len(num_words))
return neg_files
if __name__ == "__main__":
# 词典
wordsList = load_wordsList()
print("词典中词汇数量:", len(wordsList))
home_index = wordsList.index("home")
print("'home' 单词在词典中的索引:", home_index)
# 词典向量模型矩阵
wordVectors = load_wordVectors()
print("词典向量模型矩阵:", wordVectors.shape)
print("'home' 在词典向量模型矩阵中的向量表示:", wordVectors[home_index])
# 正面、负面文本数据
pos_files = postive_analysis()
neg_files = negtive_analysis()
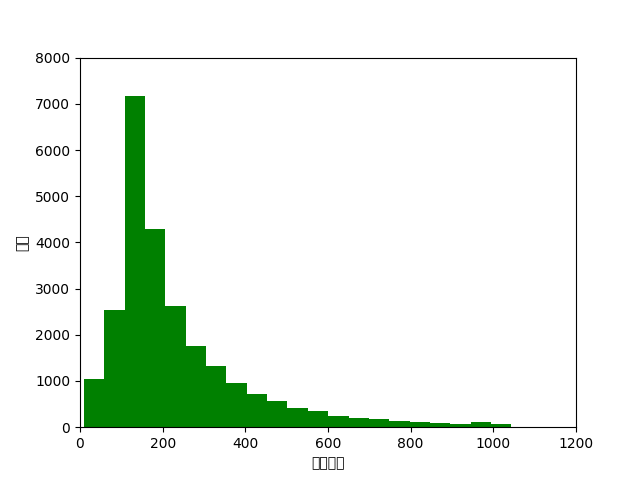
- 数据可视化
def data_visual(num_words):
import matplotlib as mpl
import matplotlib.pyplot as plt
# mpl.use("qt4agg")
# 指定默认字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
mpl.rcParams["font.family"] = "sans-serif"
# %matplotlib inline
plt.hist(num_words, 50, facecolor = "g")
plt.xlabel("文本长度")
plt.ylabel("频次")
plt.axis([0, 1200, 0, 8000])
plt.show()
if __name__ == "__main__":
# 正面、负面文本数据
pos_files, pos_num_words = postive_analysis()
neg_files, neg_num_words = negtive_analysis()
# 文本数据可视化
num_total_words = pos_num_words + neg_num_words
data_visual(num_total_words)
辅助函数
模型设置
调参配置
- 学习率
- RNN 网络最困难的部分就是它的训练速度慢, 耗时非常久, 所以学习率至关重要。如果学习率设置过大, 则学习曲线会有很大的波动性, 如果设置过小, 则收敛得非常慢。根据经验设置 0.001 比较好。 如果训练得非常慢, 可以适当增大这个值。
- 优化器
- Adam 广泛被使用
- LSTM 单元数量
- 取决于输入文本的平均长度, 单元数量过多会导致速度非常慢
- 词向量维度
- 词向量一般设置在 50~300 之间, 维度越多可以存放越多的单词信息, 但是也意味着更高的计算成本
训练模型
$ tensorflow --logdir=tensorboard