TensorFlow 和 Spark
wangzf / 2022-09-05
通过 TensorFlow for Java 在 Spark 中调用训练好的 TensorFlow 模型。利用 Spark 的分布式计算能力, 从而可以让训练好的 TensorFlow 模型在成百上千的机器上分布式并行执行模型推断, 这里的 Spark 指 Scala 版本的 Spark
Spark 调用 TensorFlow 模型简介
在 Spark 中调用 TensorFlow 模型进行预测需要完成以下几个步骤:
- 准备 protobuf 模型文件
- 创建 Spark 项目,在项目中添加 Java 版本的 TensorFlow 对应的 Jar 包依赖
- 在 Spark 项目中 driver 端加载 TensorFlow 模型,调试成功
- 在 Spark 项目中通过 RDD 在 executor 上加载 TensorFlow 模型,调试成功
- 在 Spark 项目中通过 DataFrame 在 executor 上加载 TensorFlow 模型,调试成功
准备 protobuf 文件
import tensorflow as tf
from tensorflow import keras
# 样本数量
num_samples = 800
# 数据集
X = tf.random.uniform([n, 2], minval = -10, maxval = 10)
w0 = tf.constant([[2.0], [-1.0]])
b0 = tf.constant(3.0)
Y = X@w0 + b0 + tf.random.normal([n, 1], mean = 0.0, stddev = 2.0)
# 构建模型
tf.keras.backend.clear_session()
inputs = keras.layers.Input(shape = (2,), name = "inputs")
outputs = keras.layers.Dense(1, name = "outputs")
linear = models.Model(inputs = inputs, outputs = outputs)
linear.summary()
# 训练模型
linear.compile(optimizer = "rmsprop", loss = "mse", metrics = ["mae"])
linear.fit(X, Y, batch_size = 8, epochs = 100)
tf.print(f"w = {linear.layers[1].kernel}")
tf.print(f"b = {linear.layers[1].biase}")
# 保存模型
export_path = "./data/linear_model/"
version = "1"
linear.save(export_path + version, save_format = "tf")
# 查看模型保存内容
$ !ls {export_path + verison}

# 查看模型文件相关信息
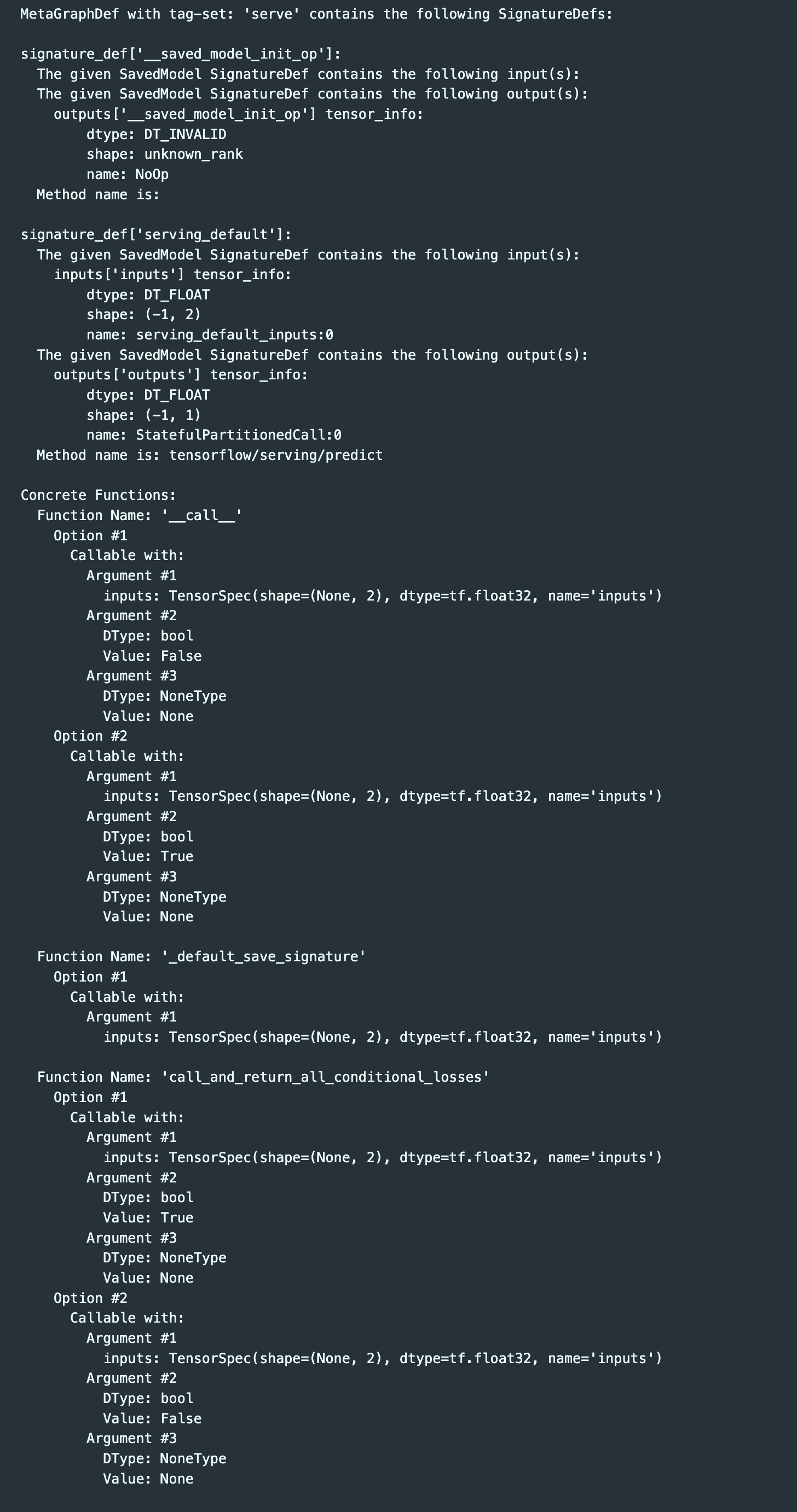
$ !saved_model_cli show --dir {export_path + str(version)} --all
创建 Spark 项目
创建 Spark 项目,在项目中添加 Java 版本的 TensorFlow 对应的 Jar 包依赖。 如果使用 Maven 管理项目,需要添加如下 jar 包依赖
<!-- https://mvnrepository.com/artifact/org.tensorflow/tensorflow -->
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow</artifactId>
<version>1.15.0</version>
</dependency>
可以从这里直接下载
org.tensorflow.tensorflow 的 jar 包依赖,
以及其依赖的 org.tensorflow.libtensorflow 和 org.tensorflowlibtensorflow_jni 的 jar 包放到项目中
在 Spark 项目中 driver 端加载调试 TensorFlow 模型
load函数的第二个参数一般都是"serve",可以从模型文件相关信息中找到- 在 Java 版本的 TensorFlow 中还是类似 TensorFlow 1.0 中静态计算图的模式,
需要建立 Session,指定
feed的数据和fetch的结果,然后run - 如果有多个数据需要
feed,可以连续使用多个feed方法 - 输入必须是
float类型
import scala.collection.mutable.WrappedArray
import org.{tensorflow=>tf}
var bundle = tf.SavedModelBundle.load(
"./models/linear_model/1",
"serve"
)
var session = bundle.session()
var x = tf.Tensor.create(
Array(
Array(1.0f, 2.0f),
Array(2.0f, 3.0f)
)
)
var y = session.runner()
.feed("serving_default_inputs:0", x)
.fetch("StatefulPartitionedCall:0")
.run()
.get(0)
var result = Array.ofDim[Float](
y.shape()(0).toInt,
y.shape()(1).toInt
)
y.copyTo(result)
if(x != null) x.close()
if(y != null) y.close()
if(session != null) session.close()
if(bundle != null) bundle.close()
result
Array(Array(3.019596), Array(3.9878292))