语言模型训练
wangzf / 2024-10-26
目录
目标函数
下面研究下面三类语言模型的目标函数:
- Encoder-only 模型:计算双向上下文嵌入(contextual embeddings)
- 例如,BERT
- Decoder-only 模型:计算单向上下文嵌入(contextual embeddings),一次生成一个 token
- 例如,GPT-3
- Encoder-Decoder 模型:编码输入,解码输出
- 例如,T5
可以使用任何模型(例如,LSTM、Transformers)将 token 序列映射到上下文嵌入(contextual embeddings)中:
ϕ:VL→Rd×Lϕ:VL→Rd×L
其中:
- VV 为词元集的词汇表;
- dd 为上下文嵌入(Contextual Embedding)的维度
- LL 为词元集的词汇表的 维度
例如:
[the, mouse, ate, the, cheese]5ϕ⇒[(10.1),(01),(11),(1−0.1),(0−1)]2×5[the, mouse, ate, the, cheese]5ϕ⇒[(10.1),(01),(11),(1−0.1),(0−1)]2×5
Decoder-only 模型
自回归语言模型定义了一个条件分布:
p(xi|x1:i−1)p(xi|x1:i−1)
将其定义如下:
-
将 x1:i−1x1:i−1 映射到上下文嵌入 ϕ(x1:i−1)ϕ(x1:i−1);
-
应用嵌入矩阵 E∈RV×dE∈RV×d 来获得每个 token 的得分 E⋅ϕ(x1:i−1)i−1E⋅ϕ(x1:i−1)i−1;
-
对其进行指数化和归一化,得到预测 xixi 的分布。简洁地:
p(xi+1|x1:i)=Softmax(E⋅ϕ(x1:i)i)p(xi+1|x1:i)=Softmax(E⋅ϕ(x1:i)i)
最大似然函数:
设 θθ 是大语言模型的所有参数,设 DD 是由一组序列组成的训练数据。 可以根据最大似然原理,定义以下负对数似然目标函数:
O(θ)=−∑x∈Dlogpθ(x)=−∑x∈DL∑i=1logpθ(xi|x1:i−1)O(θ)=−∑x∈Dlogpθ(x)=−∑x∈DL∑i=1logpθ(xi|x1:i−1)
有很多的方法可以有效地优化这个目标函数。
Encoder-only 模型
单向到双向
使用上述最大似然可以训练得到 Decoder-only 模型,它会产生(单向)上下文嵌入。 但如果不需要生成,可以提供更强的双向上下文嵌入。
BERT
BERT 的目标函数 包含以下两个部分:
- 掩码语言模型(Masked language modeling)
- 下一句预测(Next sentence prediction)
以自然语言推理(预测隐含、矛盾或中性)任务中的序列为例:
x1:L=[[CLS],all, animals, breathe,[SEP],cats, breathe]x1:L=[[CLS],all, animals, breathe,[SEP],cats, breathe]
其中有两个特殊的 token:
[CLS]:包含用于驱动分类任务的嵌入;[SEP]:用于告诉模型第一个序列(例如,前提)与第二个序列(例如,假设)的位置。
BERT 模型定义为:
BERT(x1:L)=TransformerBlock24(EmbedTokenWithPosition(x1:L)+SentenceEmbedding(x1:L))∈Rd×LBERT(x1:L)=TransformerBlock24(EmbedTokenWithPosition(x1:L)+SentenceEmbedding(x1:L))∈Rd×L
其中,SentenceEmbedding(x1:L)SentenceEmbedding(x1:L) 根据序列返回以下两个矢量之一:
- 对于 [SEP][SEP] 左边的,返回 eA∈RdeA∈Rd
- 对于 [SEP][SEP] 右边的,返回 eB∈RdeB∈Rd
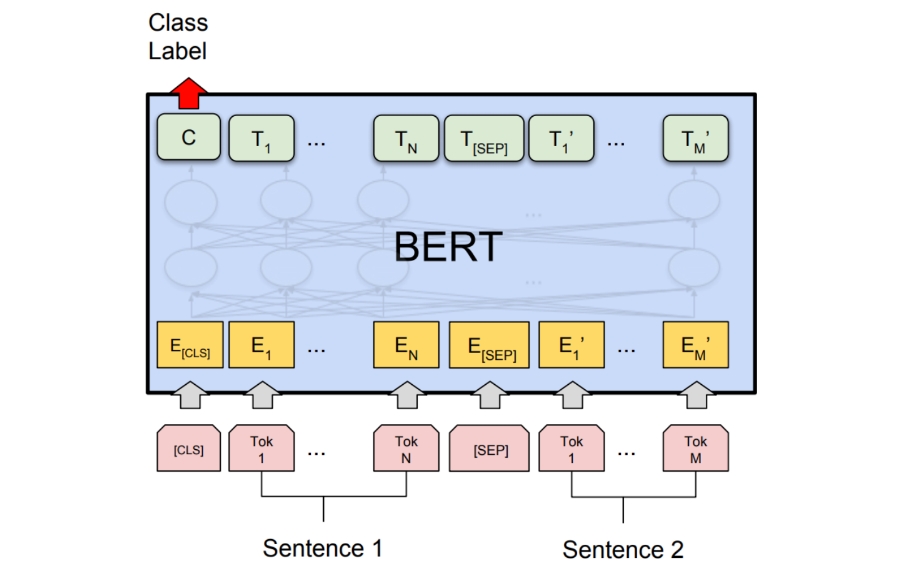
BERT-large 有 nheads=16nheads=16 个 Attention 头, 并且 dmodel=1024dmodel=1024,总共 355M 个参数。
掩码语言模型:
掩码语言模型的基本思想是通过加噪然后预测来进行训练:
[the, [MASK], ate, [MASK], cheese] => [the, mouse, ate, the, cheese]
更普遍地说,可以将其视为类似于去噪自动编码器, 其中映射有噪声/不完整版本 ˜x1:L~x1:L,并尝试重建原始 x1:Lx1:L。
˜x1:L⇒x1:L~x1:L⇒x1:L
-
建模:首先定义模型分布。给定输入 ˜x1:L~x1:L 及其上下文嵌入,模型独立地预测每个 token:
P(xi|˜x1:L)=Softmax(E⋅ϕ(˜x1:L)i)P(xi|~x1:L)=Softmax(E⋅ϕ(~x1:L)i)
-
掩码:定义了一个(随机)噪声函数 A(˜x1:L|x1:L)A(~x1:L|x1:L):
x1:L⏟originalA⇒˜x1:L⏟noisedx1:LoriginalA⇒~x1:Lnoised
以下是 AA 的定义:
- 假设 I⊂{1,⋯,L}I⊂{1,⋯,L} 代表所有位置中随机的 15%;
- 对于每个 i∈Ii∈I:
- 以 0.8 的概率,˜xi←[MASK]~xi←[MASK]
- 以 0.1 的概率,˜xi←xi~xi←xi
- 以 0.1 的概率,˜xi←random word fromV~xi←random word fromV
-
减少分布偏移:如果总是使用
[MASK]来替换 II 中选定的 token,则:- 在训练期间,输入到 BERT 的都是带
[MASK]的序列。 - 而在测试时,我们会输入没有
[MASK]的句子,这将导致分布发生变化。 一种启发式的解决方法是在 20% 的时间内(此处指训练的时间)用真实单词替换。
- 在训练期间,输入到 BERT 的都是带
下一句预测:
回想一下,BERT 是在拼接好的成对句子上训练的。下一句预测的目标是预测第二句是否跟随第一句。
[[CLS], the, mouse, ate, the, cheese, [SEP], it, was, full] => 1
[[CLS], the, mouse, ate, the, cheese, [SEP], hello, world] => 0
然后使用 [CLS] 的嵌入来做二分类。
数据集:
DD 是按如下方式构造的一组样本 (x1:L,c)(x1:L,c):
- 令 AA 是语料库中的一个句子;
- 以 0.5 的概率,BB 是下一句话;
- 以 0.5 的概率,BB 是语料库中的一个随机句子;
- 令 x1:L=[[CLS],A,[SEP],B]x1:L=[[CLS],A,[SEP],B];
- 令 cc 表示 BB 是否是下一句。
训练目标:
BERT 的训练目标是:
O(θ)=∑(x1:Lc)∈DEI,˜x1:L∼A(⋅|x1:LI)[−∑i∈Ilogpθ(˜xi|x1:L)]⏟masked language modeling+−logp(c|ϕ(x1:L)1)⏟next sentence predictionO(θ)=∑(x1:Lc)∈DEI,~x1:L∼A(⋅|x1:LI)[−∑i∈Ilogpθ(~xi|x1:L)]masked language modeling+−logp(c|ϕ(x1:L)1)next sentence prediction
稍后将讨论训练,这里简要总结一下 BERT:
- BERT(以及 ELMo 和 ULMFiT)表明,一个统一的体系结构(Transformer)可以用于多个分类任务;
- BERT 真正将 NLP 社区转变为 预训练+微调 的范式;
- BERT 显示了深度双向上下文嵌入的重要性,尽管通过模型大小和微调策略可能会弥补这一点, 比如:p-tuning。
RoBERTa
RoBERTa 对 BERT 进行了以下改进:
- 删除了下一句预测这一目标函数(发现它没有帮助);
- 使用更多数据训练(16GB 文本 ⇒⇒ 160GB 文本);
- 训练时间更长;
- RoBERTa 在各种基准上显著提高了 BERT 的准确性(例如,在 SQuAD 上由 81.8 到 89.4)。
Encoder-Decoder 模型
回想一下编码器-解码器模型(例如,BART、T5):
- 首先像 BERT 一样对输入进行双向编码;
- 然后像 GPT-2 一样对输出进行自回归解码。
BART
Bidirectional Auto-Regressive Transformers
BART 是基于 Transformer 的 Encoder-Decoder 模型。
- 使用与 RoBERTa 相同的 Encoder 架构(12 层,隐藏维度 1024)
- 使用与 RoBERTa 相同的数据进行训练(160GB 文本)
BART 使用了以下变换 A(˜x1:L|x1:L)A(~x1:L|x1:L):
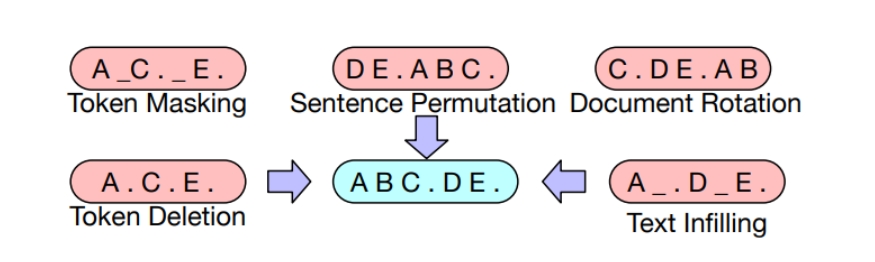
基于 BERT 的实验,最终模型进行以下了变换:
- 掩码文档中 30% 的 token
- 将所有子句打乱
最后,通过微调,BART 在分类和生成任务上都展示了强大的效果。
T5
Text-to-Text Transfer Transformer
T5 是另一种基于 Transformer 的 Encoder-Decoder 模型。
预训练任务:给定一段文本,在随机位置将其分割为输入和输出:
[the, mouse] => [ate the cheese]
论文尝试了许多不同的无监督目标:

并发现 “i.i.d. noise, replace spans” 效果最好(尽管许多目标相似)。
论文还将所有经典的 NLP 任务放在一个统一的框架中,称为 “Text-to-Text” 任务:
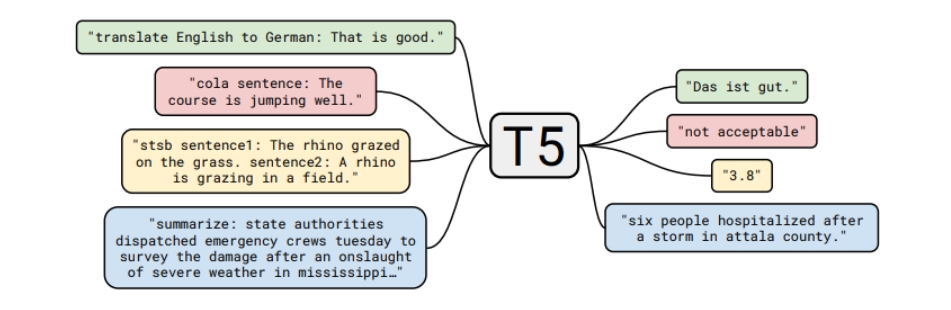
以分类任务任务为例,不同模型的差异如下:
- BERT 使用
[CLS]的嵌入来预测。 - T5、GPT-2、GPT-3 等(生成模型)将分类任务转换成自然语言生成。
注意:
- 论文对整个 pipline 的许多方面(数据集、模型大小、训练目标等)进行了深入研究。
- 基于这些见解,他们训练了一个 11B 的模型。
优化算法
为了简单起见,以自回归语言模型为例:
O(θ)=−∑x∈Dlogpθ(x)O(θ)=−∑x∈Dlogpθ(x)
SGD
随机梯度下降
最简单的优化算法是用小批量进行随机梯度下降,该算法的步骤如下:
- 初始化参数 θθ;
- 重复以下步骤:
- 采样小批量 Bt∈DBt∈D
- 根据梯度更新参数:
θt←θt−1−η1|Bt|∑x∈Bt∇θ(−logpθ(x))θt←θt−1−η1|Bt|∑x∈Bt∇θ(−logpθ(x))
优化的关键点包括:
- 希望参数 θθ 可以快速收敛;
- 希望优化在数值上是稳定的;
- 希望内存高效(尤其是对于大模型);
这些点往往相互矛盾(例如,通过低精度训练,可以实现快速收敛、减少内存占用,但是会导致训练不稳定)。
因此,可以从几个层次来进行优化:
- 针对经典优化:二阶方法、约束优化等;
- 针对机器学习:随机方法、隐式正则化 + 早停法;
- 针对深度学习:初始化、归一化(更改模型架构);
- 针对大语言模型:由于稳定性问题,学习率和一些直觉(例如,二阶方法)仍然有用, 但要使大语言模型有效训练,还需要克服许多其他独特的挑战。 不幸的是,其中大部分内容都是特别的,人们对此了解甚少。
Adam
Adaptive Moment Estimation
Adam 算法拥有以下两个创新:
- 引入动量(继续朝同一方向移动);
- 参数 θ0θ0 的每个维度都有一个自适应(不同)的步长(受二阶方法启发)。
它的步骤如下:
- 初始化参数 θ0θ0
- 初始化动量 m0,v0←0m0,v0←0
- 重复以下步骤:
-
采样小批量 Bt⊂DBt⊂D
-
按照如下步骤更新参数:
- 计算梯度
gt←1|Bt|∑x∈Bt∇θ(−logpθ(x))gt←1|Bt|∑x∈Bt∇θ(−logpθ(x))
- 更新一阶/二阶动量
mt←β1mt−1+(1−β1)gtmt←β1mt−1+(1−β1)gt bt←β2vt−1+(1−β2)g2tbt←β2vt−1+(1−β2)g2t
- 对偏差进行修正
ˆmt←mt/(1−βt1)^mt←mt/(1−βt1) ˆvt←vt/(1−βt2)^vt←vt/(1−βt2)
- 更新参数
θt←θt−1−ηˆmt/(√ˆvt+ϵ)θt←θt−1−η^mt/(√^vt+ϵ)
-
存储占用分析:Adam 将存储从 2 倍的模型参数 (θt,gt)(θt,gt) 增加到了 4 倍 (θt,gt,mt,vt)(θt,gt,mt,vt)。
AdaFactor
AdaFactor 是一种为减少存储占用的优化算法。它有如下特点:
- 它不储存 mt,vtmt,vt 这样的 O(m×n)O(m×n) 矩阵, 而是存储行和列的和 O(m+n)O(m+n) 并重构矩阵
- 去除动量
- 被用来训练 T5
- AdaFactor 可能使训练变得困难(见 Twitter thread 和 blog post)
混合精度训练
混合精度训练是另一种减少存储的方法。
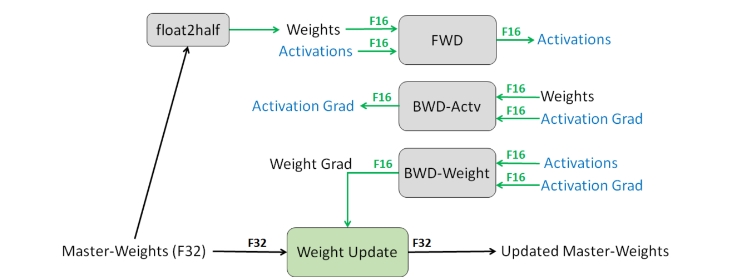
通常来说,默认的精度是:FP32(32 位浮点),其他可选精度为 FP16(16 位浮点), 但问题是任何小于 2−242−24 的值都会变为 0。
- 解决方案:将主权重存储在 FP32 中,并在 FP16 中执行其他所有操作。
- 损失缩放:按比例放大损失,以避免梯度数值太小。
- 结果:存储减少了一半。
学习率
通常情况下,学习率会随着时间的推移而衰减。对于 Transformer 模型, 实际上需要通过预热(warmup)提高学习率。 Huang 等 2020 表明, 一个潜在的原因是防止层归一化的梯度消失,导致使用 Adam 优化器训练时不稳定。
初始化
给定矩阵 W∈Rm×nW∈Rm×n,标准初始化(即,xavier 初始化)为 Wij∼N(0,1/n)Wij∼N(0,1/n);
GPT-2 和 GPT-3 通过额外的 1/√N1/√N 缩放权重,其中 NN 是残差层的数量。 T5 将注意力矩阵增加一个 1/√d1/√d(代码)。
以 GPT-3 为例,使用的参数如下:
- Adam 参数:β1=0.9,β2=0.95,ϵ=10−8β1=0.9,β2=0.95,ϵ=10−8;
- 批量小:320 万个 token(约 1500 个序列);
- 使用梯度剪裁 gt←gt/min(1,|g2|)gt←gt/min(1,|g2|);
- 线性学习率预热(前 3.75 亿个 token);
- 余弦学习率衰减到 10%;
- 逐渐增加批大小;
- 权重衰减设为 0.1。
分布式训练
为什么分布式训练越来越流行
近年来,深度学习被广泛应用到各个领域,包括计算机视觉、语言理解、语音识别、广告推荐等。 在这些不同的领域中,一个共同的特点就是模型规模越来越大,比如 GPT-3 模型的参数量达到 1750 亿(175B)。 即使用 1024 张 80 GB 的 A100,那么完整训练 GPT-3 的时长都需要 1 个月。
模型规模的扩大,对硬件(算力、内存)的发展提出要求。 然而,因为内存墙的存在, 单一设备的算力及容量,受限于物理定律,持续提高芯片的集成越来越困难,难以跟上模型扩大的需求。
为了解决算力增速不足的问题,人们考虑用多节点集群进行分布式训练,以提升算力,分布式训练势在必行。
常见的并行策略
简单的机器堆叠并不一定会带来算力的增长。 因为神经网络的训练并不是单纯的 “把原来一个设备做的事情,现在分给多个设备各自做”, 它不仅需要多个设备进行计算,还涉及到设备之间的数据传输,只有协调好集群中的计算与通信, 才能做高效的分布式训练。
以矩阵乘法的例子,解释 数据并行、模型并行 的区别。先了解以下逻辑上的矩阵乘法例子: 假设神经网络中某一层是做矩阵乘法,其中的输入 x 的形状为 4×5, 模型参数 w 的形状为 5×8,那么,矩阵乘法输出形状为 4×8。 示意图如下:
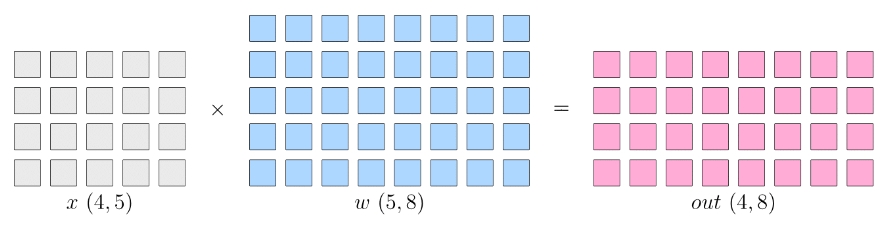
- 单机单卡的训练中,以上矩阵乘法,先计算得到 out,并将 out 传递给下一层, 并最终计算得到 loss,然后在反向传播过程中, 得到 ∂loss∂w,用于更新 w;
- 分布式训练中,依据是切分 x 还是 w 的不同,分为“数据并行”和“模型并行”策略。
数据并行
所谓的数据并行,就是将数据 x 进行切分,而每个设备上的模型 w 是完整的、一致的。 如下图所示,x 被按照第 0 维度平均切分到 2 个设备上,两个设备上都有完整的 w。 这样,在两台设备上,分别得到的输出,都只是逻辑上输出的一半(形状为 2×8), 将两个设备上的输出拼接到一起,才能得到逻辑上完整的输出。
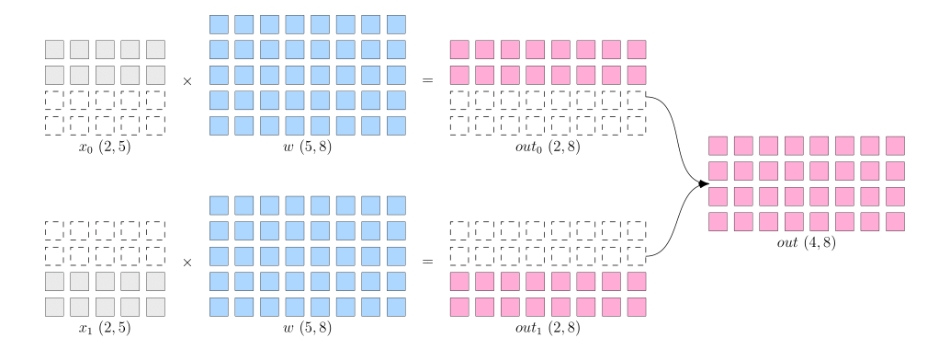
注意,因为数据被分发到了 2 个设备上,因此反向传播过程, 各自设备上得到的 ∂loss∂w 会不一样, 如果直接使用各个设备上的梯度更新各自的模型,会造成 2 个设备上的模型不一致, 训练就失去了意义(到底用哪个模型好呢?)。
因此,数据并行策略下,在反向传播过程中, 需要对各个设备上的梯度进行 AllReduce, 以确保各个设备上的模型始终保持一致。
当数据集较大,模型较小时,由于反向过程中为同步梯度产生的通信代价较小, 此时选择数据并行一般比较有优势,常见的视觉分类模型,如 ResNet50,比较适合采用数据并行。
模型并行
当神经网络非常巨大,数据并行同步梯度的代价就会很大, 甚至网络可能巨大到无法存放到单一计算设备中,这时候, 可以采用模型并行策略解决问题。
所谓的模型并行,就是每个设备上的数据是完整的、一致的,而模型 w 被切分到了各个设备上, 每个设备只拥有模型的一部分,所有计算设备上的模型拼在一起,才是完整的模型。
如下图所示,w 被按照第 1 维度平均切分到 2 个设备上,两个设备上都有完整的 x。 两个设备上的输出也需要通过拼接才能得到逻辑上的输出。
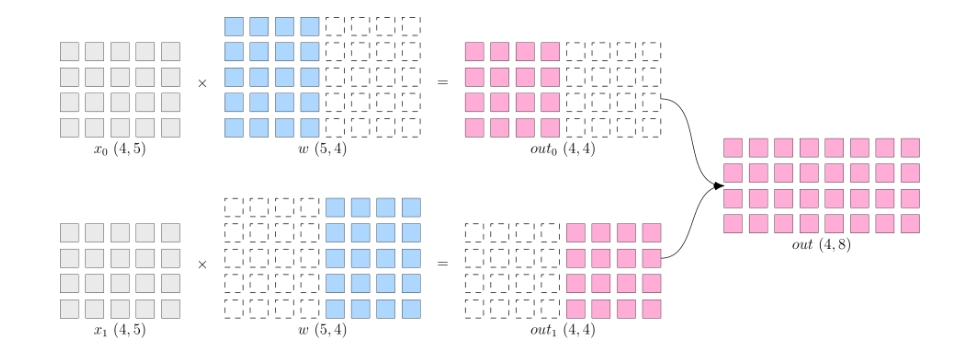
模型并行的好处是,省去了多个设备之间的梯度 AllReduce;但是,由于每个设备都需要完整的数据输入, 因此,数据会在多个设备之间进行广播,产生通信代价。比如,上图中的最终得到的 out(4×8), 如果它作为下一层网络的输入,那么它就需要被广播发送到两个设备上。
语言模型,如 BERT,常采用模型并行。
流水并行
当神经网络过于巨大,无法在一个设备上存放时,除了上述的模型并行的策略外,还可以选择流水并行。 流水并行指将网络切为多个阶段,并分发到不同的计算设备上,各个计算设备之间以“接力”的方式完成训练。
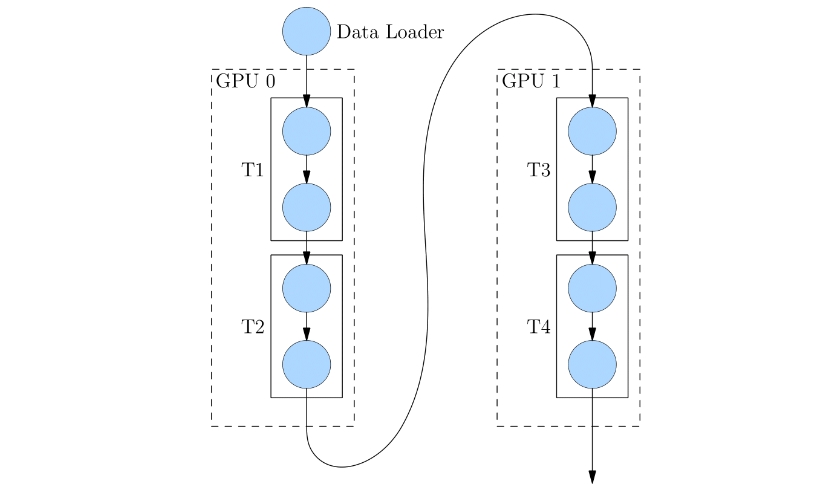
如下图,展示了一个逻辑上的 4 层网络(T1 至 T4)是如何做流水并行的:
4 层网络被切分到 2 个计算设备上,其中 GPU0 上进行 T1 与 T2 的运算,
GPU1 上进行 T3 与 T4 的计算。GPU0 上完成前两层的计算后,
它的输出被当作 GPU1 的输入,继续进行后两层的计算。
混合并行
网络的训练中,也可以将多种并行策略混用,以 GPT-3 为例,以下是它训练时的设备并行方案:
它首先被分为 64 个阶段,进行流水并行。每个阶段都运行在 6 台 DGX-A100 主机上。 在 6 台主机之间,进行的是数据并行训练;每台主机有 8 张 GPU 显卡, 同一台机器上的 8 张 GPU 显卡之间是进行模型并行训练。
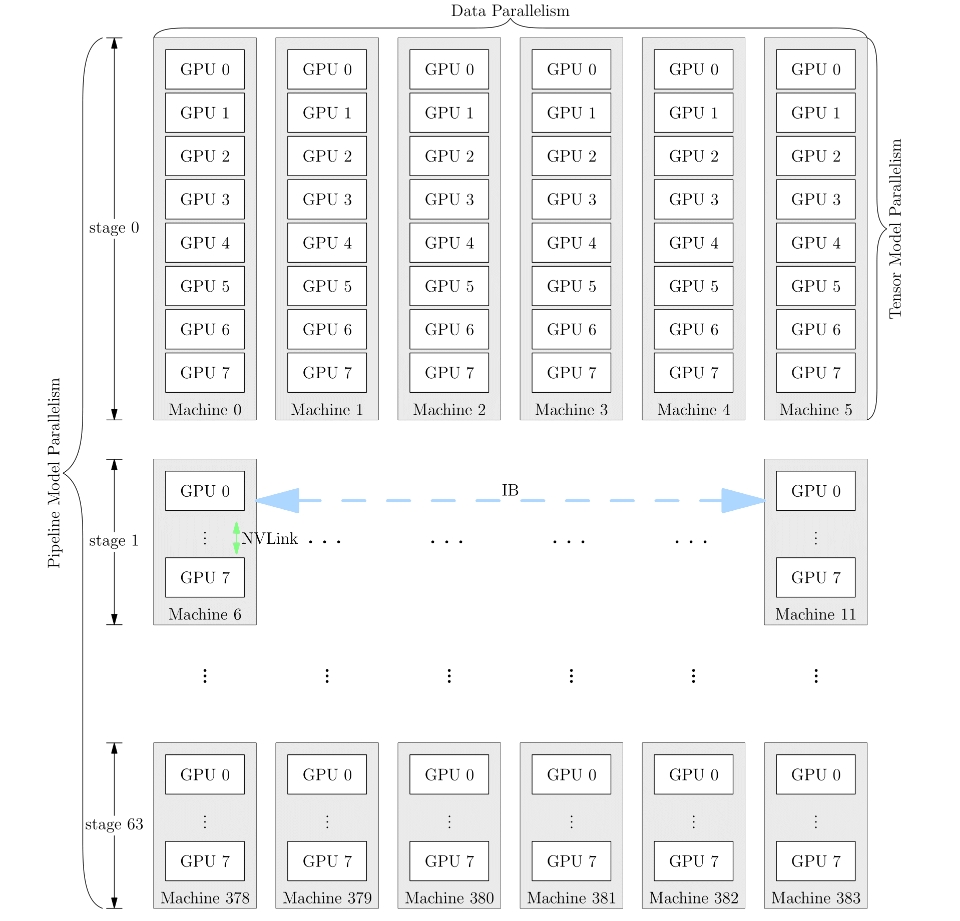
并行策略的选择影响着训练效率,框架对并行训练的接口支持程度,决定了算法工程师的开发效率。 OneFlow 针对分布式训练所做的系统级设计和创新,为用户轻松上手分布式训练做足了铺垫。