LLM 架构--Eval
wangzf / 2024-06-10
LLM 应用评估方法
验证评估的一般思路
以调用大模型为核心的大模型开发相较传统的 AI 开发更注重验证迭代。 由于可以快速构建出基于 LLM 的应用程序,在几分钟内定义一个 Prompt, 并在几小时内得到反馈结果,那么停下来收集一千个测试样本就会显得极为繁琐。 因为现在可以在没有任何训练样本的情况下得到结果。
验证迭代 是构建以 LLM 为中心的应用程序所必不能少的重要步骤,通过不断寻找 Bad Case, 针对性调整 Prompt 或优化检索性能,来推动应用达到目标中的性能与精度。 因此,在使用 LLM 构建应用程序时,可能会经历以下流程:
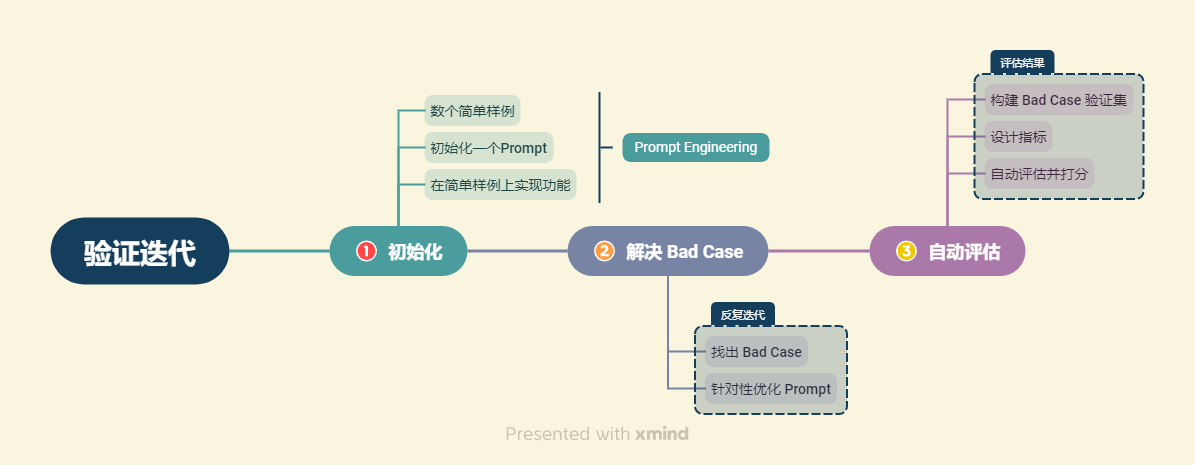
- 首先,会在 1~3 个样本的小样本中调整 Prompt ,尝试使其在这些样本上起效。
- 随后,当对系统进行进一步测试时,可能会遇到一些棘手的例子,这些例子无法通过 Prompt 或者算法解决。 这就是使用 LLM 构建应用程序的开发者所面临的挑战。在这种情况下, 可以将这些额外的几个例子添加到正在测试的集合中,有机地添加其他难以处理的例子。
- 最终,会将足够多的这些例子添加到逐步扩大的开发集中,以至于手动运行每一个例子以测试 Prompt 变得有些不便。 然后,开始开发一些用于衡量这些小样本集性能的指标,例如平均准确度。
这个过程的有趣之处在于,如果你觉得你的系统已经足够好了,你可以随时停止,不再进行改进。 实际上,很多已经部署的应用程序就在第一步或第二步就停下来了,而且它们运行得非常好。
LLM 评估方法
主要内容:
- 首先介绍大模型开发评估的几种方法。对于有简单标准答案的任务来说,评估很容易得到实现; 但大模型开发一般是需要实现复杂的生成任务,如何在没有简单答案甚至没有标准答案的情况下实现评估, 能够准确地反映应用的效果。
- 随着我们不断寻找到 Bad Case 并做出针对性优化,可以将这些 Bad Case 逐步加入到验证集, 从而形成一个有一定样例数的验证集。针对这种验证集,一个一个进行评估就是不切实际的了。 需要一种自动评估方法,实现对该验证集上性能的整体评估。
- 掌握了一般思路,会具体到基于 RAG 范式的大模型应用中来探究如何评估并优化应用性能。 由于基于 RAG 范式开发的大模型应用一般包括两个核心部分:检索和生成, 所以,评估优化也会分别聚焦到这两个部分,分别以优化系统检索精度和在确定给定材料下的生成质量。
在具体的大模型应用开发中,我们可以找到 Bad Cases,并不断针对性优化 Prompt 或检索架构来解决 Bad Cases, 从而优化系统的表现。我们会将找到的每一个 Bad Case 都加入到我们的验证集中,每一次优化之后, 我们会重新对验证集中所有验证案例进行验证,从而保证优化后的 系统不会在原有 Good Case 上失去能力或表现降级。 当验证集体量较小时,我们可以采用人工评估的方法,即对验证集中的每一个验证案例,人工评估系统输出的优劣; 但是,当验证集随着系统的优化而不断扩张,其体量会不断增大,以至于人工评估的时间和人力成本扩大到我们无法接受的程度。 因此,我们需要采用自动评估的方法,自动评估系统对每一个验证案例的输出质量,从而评估系统的整体性能。
人工评估
准则 1-量化评估
准则 2-多维评估
简单自动评估
使用大模型进行评估
混合评估
事实上,上述评估方法都不是孤立、对立的,相较于独立地使用某一种评估方法, 我们更推荐将多种评估方法混合起来,对于每一种维度选取其适合的评估方法, 兼顾评估的全面、准确和高效。
例如,可以设计以下混合评估方法:
- 客观正确性。客观正确性指对于一些有固定正确答案的问题,模型可以给出正确的回答。 可以选取部分案例,使用构造客观题的方式来进行模型评估,评估其客观正确性。
- 主观正确性。主观正确性指对于没有固定正确答案的主观问题,模型可以给出正确的、全面的回答。 可以选取部分案例,使用大模型评估的方式来评估模型回答是否正确。
- 智能性。智能性指模型的回答是否足够拟人化。由于智能性与问题本身弱相关, 与模型、Prompt 强相关,且模型判断智能性能力较弱,可以少量抽样进行人工评估其智能性。
- 知识查找正确性。知识查找正确性指对于特定问题,从知识库检索到的知识片段是否正确、是否足够回答问题。 知识查找正确性推荐使用大模型进行评估,即要求模型判别给定的知识片段是否足够回答问题。 同时,该维度评估结果结合主观正确性可以计算幻觉情况,即如果主观回答正确但知识查找不正确, 则说明产生了模型幻觉。
使用上述评估方法,基于已得到的验证集示例,可以对项目做出合理评估。