DTW 介绍
DTW,Dynamic time warping,动态时间归整(扭曲)
- warping 指对序列进行压缩或扩展
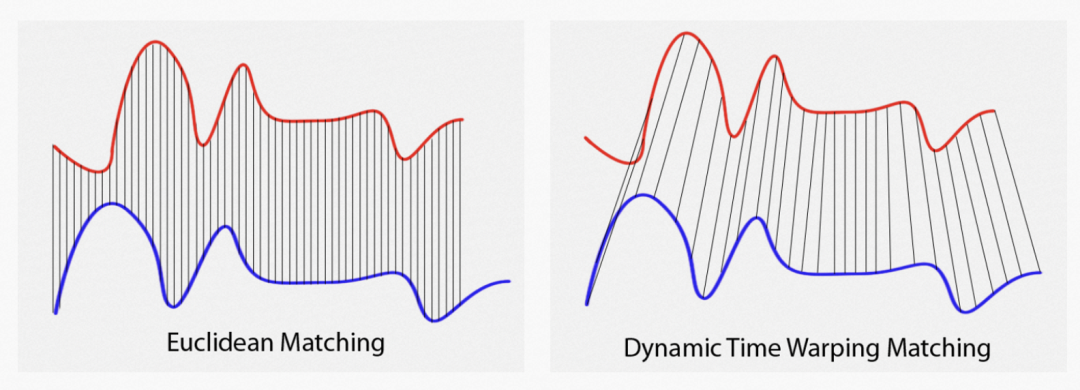
动态时间归整,简称 DTW,该算法在 1970 年左右被提出来,最早用于处理语音识别分类的问题, 是一种计算两个数据序列之间的最佳匹配的技术。
DTW 的核心思路是,利用动态规划方法,对两个序列的点之间进行匹配,找到让两个序列相似度最高的匹配方式。 DTW 充分考虑了两个序列各个点之间的关系,通过扭曲重整序列进行对齐,计算最短距离,实现形状上的匹配。 在这种最相似的匹配结果下,两个时间序列的距离就是最终真正的差异,也就可以转换成损失函数。
简单来说,给定两个离散的序列(实际上不一定要与时间有关),DTW 能够衡量这两个序列的相似程度,或者说两个序列的距离。 同时 DTW 能够对两个序列的延展或者压缩能够有一定的适应性。
举个例子,不同人对同一个词语的发音会有细微的差别,特别在时长上,有些人的发音会比标准的发音或长或短, DTW 对这种序列的延展和压缩不敏感,所以给定标准语音库,DTW 能够很好得识别单个字词, 这也是为什么 DTW 一直被认为是语音处理方面的专门算法。实际上,DTW 虽然老,但简单且灵活地实现模板匹配, 能解决很多离散时间序列匹配的问题,视频动作识别,生物信息比对等等诸多领域都有应用。
再比如下图中黑色与红色曲线中的虚线就是表示点点之间的一个对应关系。也就是说, 两个比对序列之间的特征是相似的,只是在时间上有不对齐的可能,这个算法名中的 Time Warping, 指的就是对时间序列进行的压缩或者延展以达到一个更好的匹对。
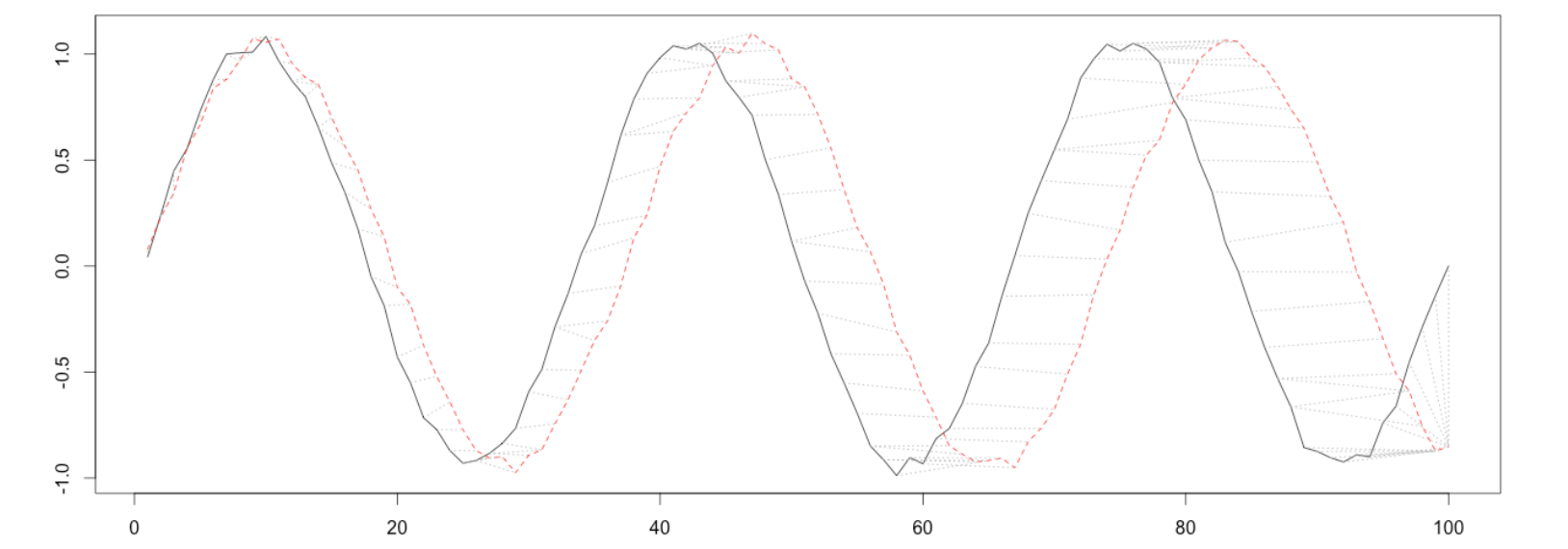
DTW 允许根据需要对数据集应用尽可能多的校正,以确保每个点都尽可能同步,甚至可以将其应用于不同长度的数据集。 DTW 可以应用于时间和非时间数据,例如财务指标、股票市场指数、计算音频等。但是要确保数据没有空值或缺失值
DTW 算法理论
算法介绍
假设给定两个序列,样本序列 $X=(x_{1}, x_{2}, \ldots, x_{N})$ 和测试序列 $Y = (y_{1}, y_{2}, \ldots, y_{M})$,
同时给定一个序列中点到点的距离函数 $d(i,j) = f(x_{i}, y_{j}) \geq 0$(一般为欧式距离,实际上也可以是别的函数)
DTW 的核心在于求解扭曲曲线(Wraping Curve)或者说扭曲路径,也就是点到点之间的对应关系,
表示为 $\phi(k) = (\phi_{X}(k), \phi_{Y}(k)),k=1, 2, \ldots, T, T=N\times M$,其中 $\phi_{X}(k)$ 的可能值为 $1, 2, \ldots, N$,
$\phi_{Y}(k)$ 的可能值为 $1, 2, \ldots, M$。
也就是说,求出 $T$ 个从 $X$ 序列中点到 $Y$ 序列中点的对应关系,例如若 $\phi(k) = (1, 1)$,
那么就是说 $X$ 曲线的第一个点与 $Y$ 曲线的第一个点是一个对应
给定了 $\phi(k)$,可以求解两个序列的累积距离(Accumulated Distortion):
$$d_{\phi}(X, Y) = \sum_{k=1}^{T}d(\phi_{X}(k), \phi_{Y}(k))$$
DTW 的最后输出,就是要找到一个最合适的 $\phi(k)$ 扭曲曲线,使得累积距离最小,也就是损失矩阵的最后一行最后一列的值:
$$DTW(X, Y) = \underset{\phi}{min} d_{\phi}(X, Y)$$
换句话说,就是给定了距离矩阵,如何找到一条从左上角到右下角的路径,使得路径经过的元素值之和最小。
这个问题可以由动态规划(Dynamic Programming)解决(时间复杂度 $O(N+M)$),也就是上面例子中,
计算损失矩阵的过程,实际上不需要把整个矩阵都求解出来,大致将对角线上的元素求解出来即可
算法讨论
实际上,虽然 DTW 算法简单,但是有很多值得讨论的细节
约束条件
首先,路径的寻找不是任意的,一般来说有三个约束条件:
- 单调性:也就是说扭曲曲线不能往左或者往上后退,否则会出现无意义的循环
$$\phi_{X}(k+1) \geq \phi_{X}(k)$$
$$\phi_{Y}(k+1) \geq \phi_{Y}(k)$$
- 连续性:扭曲曲线不能跳跃,必须是连续的,保证两个序列里的所有点都被匹配到,但这个条件可以一定程度上被放松
$$\phi_{X}(k+1)-\phi_{X}(k) \leq 1$$
- 边界条件确定性:路径一定从左上开始,结束于右下,这个条件也可以被放松,以实现局部匹配
$$\phi_{X}(1) = \phi_{Y}(1)$$
$$\phi_{X}(T) = N$$
$$\phi_{Y}(T) = M$$
除此之外,还可以增加别的约束:
- 全局路径窗口(Warping Window):比较好的匹配路径往往在对角线附近, 所以我们可以只考虑在对角线附近的一个区域寻找合适路径(r 就是这个区域的宽度)
$$|\phi_{X}(S) - \phi_{Y}(S)| \leq r$$
- 斜率约束(Slope Constrain): 这个可以看做是局部的 Warping Window,用于避免路径太过平缓或陡峭, 导致短的序列匹配到太长的序列或者太长的序列匹配到太短的序列
$$\frac{\phi_{X}(m) - \phi_{X}(n)}{\phi_{Y}(m) - \phi_{Y}(n)} \leq p$$
$$\frac{\phi_{Y}(m) - \phi_{Y}(n)}{\phi_{X}(m) - \phi_{X}(n)} \leq q$$
步模式
实际上,这些步模式(Step Pattern)一定程度上涵盖了不同的约束,步模式指的是生成损失矩阵时的具体算法, 例如在例子中使用的是:
$$M_{c}(i, j) = min\Big(M_{c}(i-1, j-1), M_{c}(i-1, j), M_{c}(i, j-1)\Big) + M(i,j)$$
很多其他步模式,不同的步模式会影响最终匹配的结果。关于不同的步模式,常用的有对称,准对称和非对称三种
标准化
序列的累积距离,可以被标准化,因为长的测试序列累积距离很容易比短的测试序列累积距离更大, 但这不一定说明后者比前者与样本序列更相似,可以通过标准化累积距离再进行比较。 不同的步模式会需要的不同的标准化参数
点与点的距离函数
除了测试序列以外,DTW 唯一需要的输入,就是距离函数 $d(x, y)$(除了欧氏距离,也可以选择 Mahalanobis 距离等),
所以不需要考虑输入的具体形式(一维或多维,离散或连续),只要能够给定合适的距离函数,就可以 DTW 比对。
前面说到,DTW 是对时间上的压缩和延展不敏感,但是对值的大小是敏感的,可以通过合理选取距离函数来让 DTW 适应值大小的差异
算法应用场景
分类
气象指数在旱季和雨季的样本序列分别为 $X_{1}$ 和 $X_{2}$,现有一段新的气象指数 $Y$,
要判断该气象指数测得时,是雨季还旱季?
算出 $DTW(X_{1}, Y)$ 和 $DTW(X_{2}, Y)$,小者即为与新测得气象指数更贴近,根据此作判断
DTW 就是一个很好的差异比较的工具,给出的距离(或标准化距离)能够进一步输入到 KNN 等分类器里(KNN 就是要找最近的邻居,DTW 能够用于衡量“近”与否), 进行进一步分类,比对
点到点匹配
给定标准语句的录音 $X$,现有一段新的不标准的语句录音 $Y$,其中可能缺少或者掺入了别的字词。
如何确定哪些是缺少的或者哪些是掺入别的?
通过 DTW 的扭曲路径,我们可以大致得到结论:
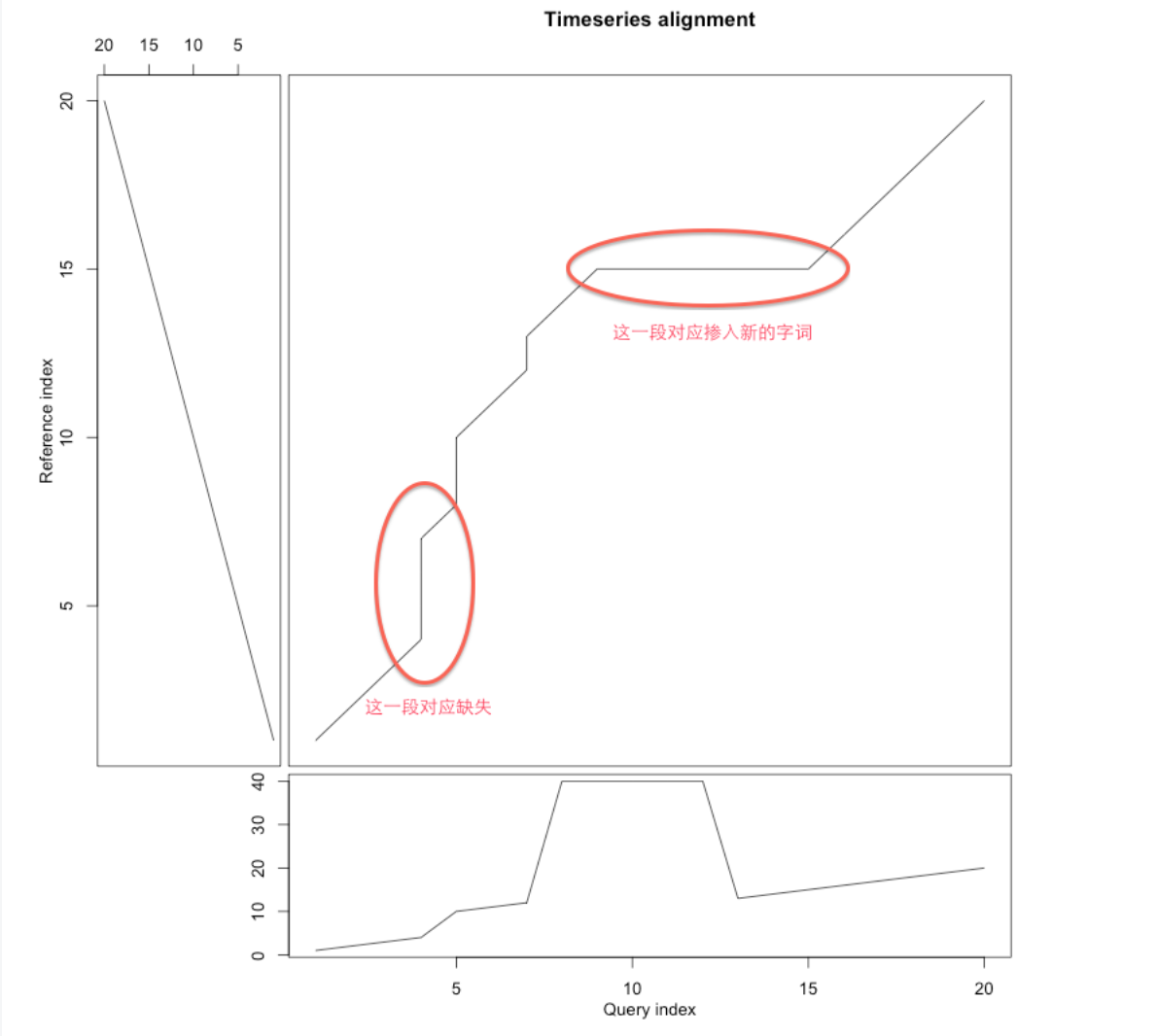
DTW 的输出是很丰富的,除了距离外,还提供了扭曲路径,可用于点到点的匹配, 这个信息是非常丰富的,能够看到序列的比对,发现异常的序列
DTW 计算示例
问题假设
给定一个样本序列 $X$ 和对比序列 $Y$、$Z$:
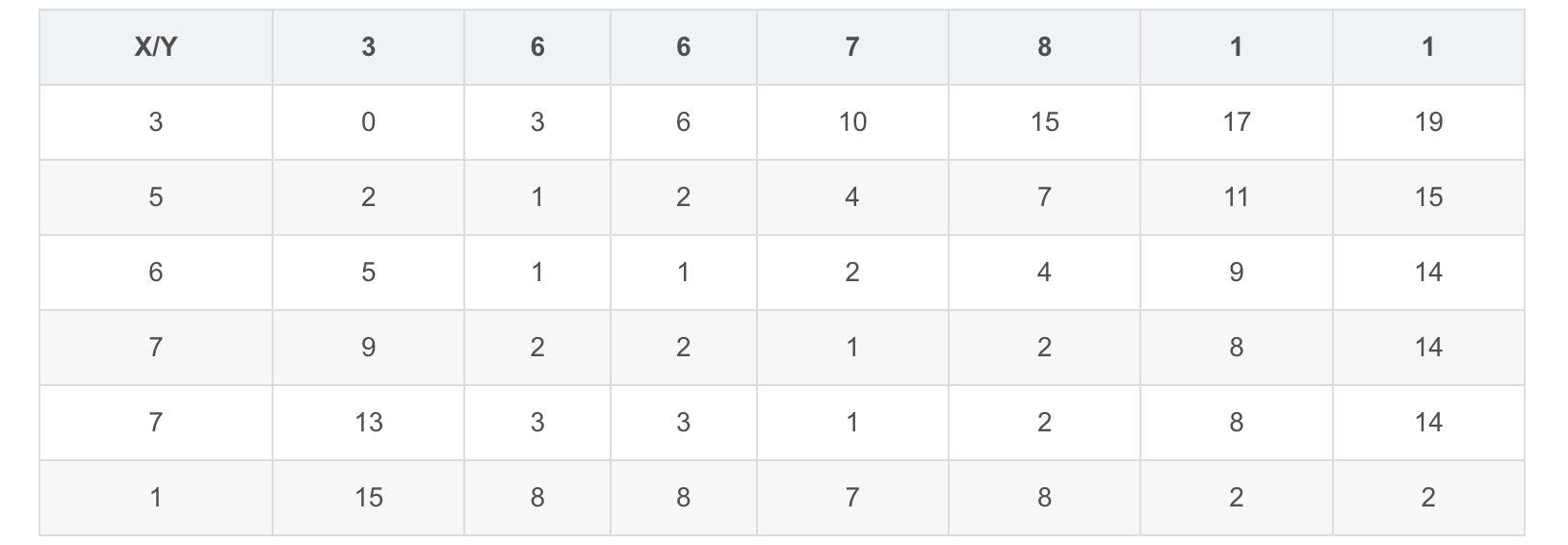
$$X = [3, 5, 6, 7, 7, 1]$$
$$Y = [3, 6, 6, 7, 8, 1, 1]$$
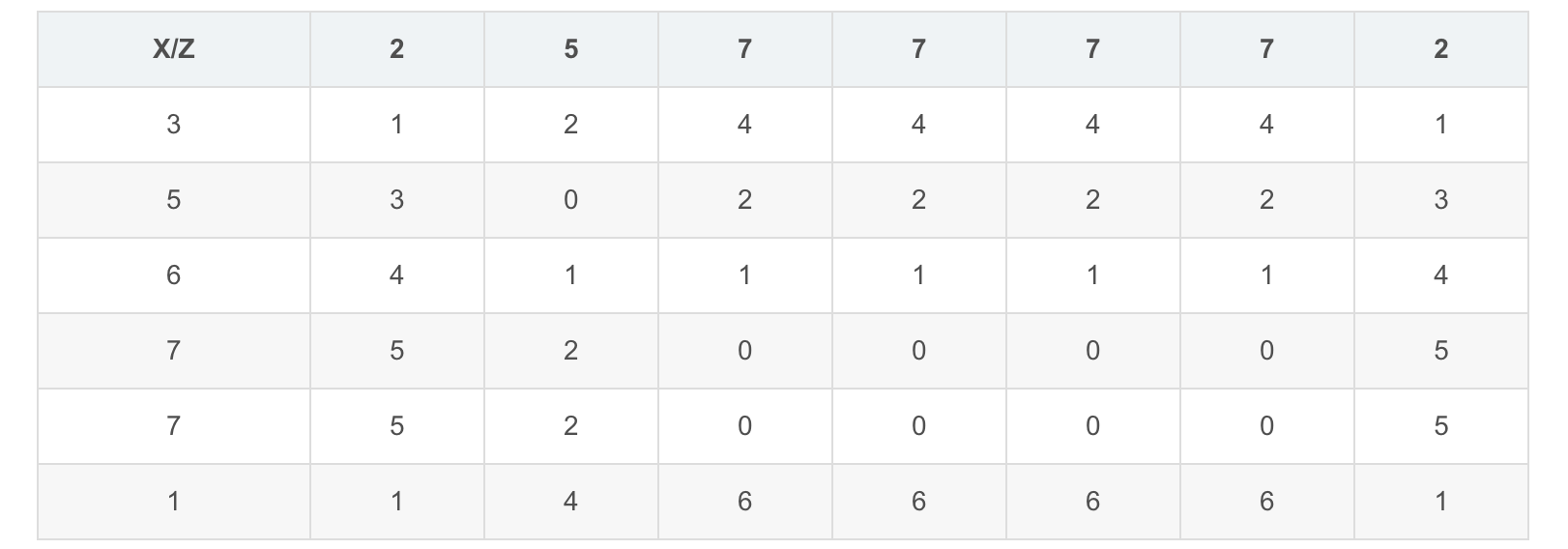
$$Z = [2, 5, 7, 7, 7, 7, 2]$$
请问 $X$ 和 $Y$ 更相似,还是 $X$ 和 $Z$ 更相似?
计算过程
距离矩阵
DTW 首先会根据两个序列点之间的距离(欧氏距离)获得一个序列距离矩阵 $M$,
其中行对应一个序列,列对应另一个序列,矩阵元素对应行列中第一个序列和第二个序列点到点的距离
$X$和$Y$的距离矩阵为:
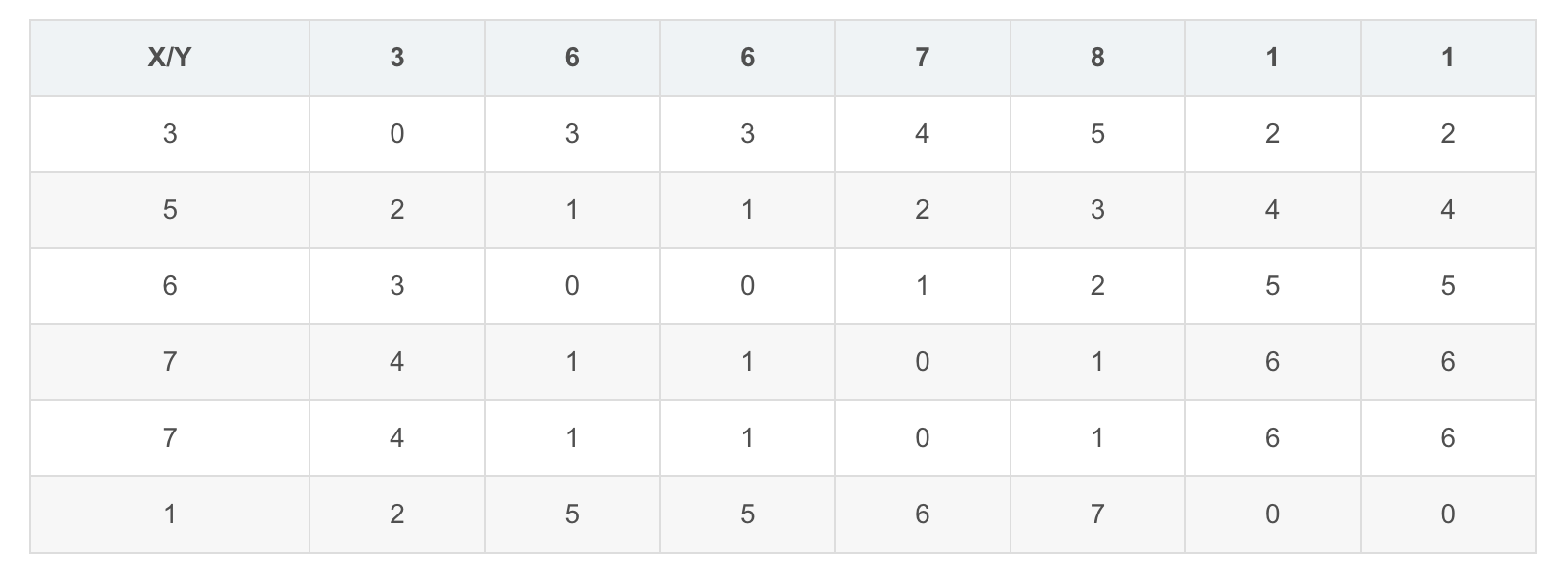
$X$和$Z$的距离矩阵为:
损失矩阵
然后根据距离矩阵生成损失矩阵(Cost Matrix),或者叫做累积距离矩阵(Accumulated Distortion Matrix),表示为 $M_{c}$。
其计算方法如下:
- 第一行第一列元素为
$M_{c}$的第一行第一列元素,在这里就是 0 - 其他位置的元素
$M_{c}(i,j)$的值则需要逐步计算,具体值的额计算方法为:
$$M_{c}(i, j) = min\Big(M_{c}(i-1, j-1), M_{c}(i-1, j), M_{c}(i, j-1)\Big) + M(i,j)$$
$X$和$Y$的损失矩阵如下。两个序列的距离,由损失矩阵最后一行最后一列给出,在这里也就是 2:
$X$和$Y$的损失矩阵如下。两个序列的距离,由损失矩阵最后一行最后一列给出,在这里也就是 2:
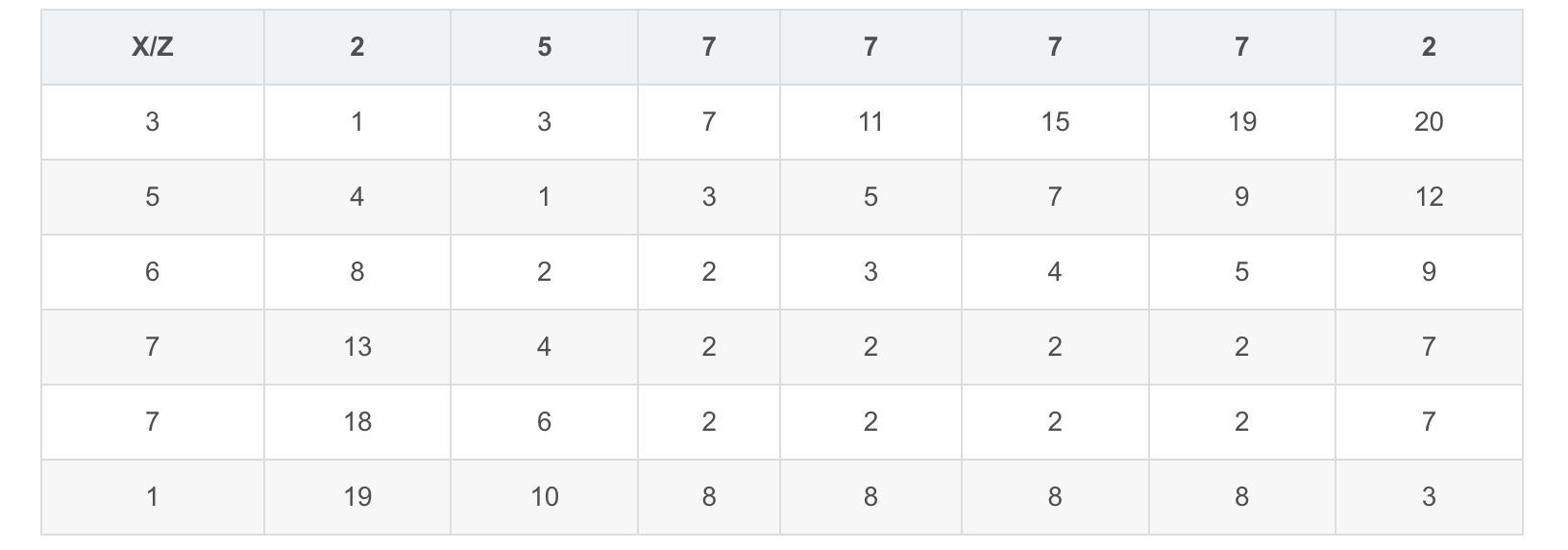
所以,$X$ 和 $Y$ 的距离为 2,$X$ 和 $Z$ 的距离为 3,$X$ 和 $Y$ 更相似
DTW 应用
- 动态归整同步时间序列数据
fastdtw 库
$ pip install fastdtw
dtaidistance 库
$ pip install dtaidistance
from dtaidistance import dtw
from dtaidistance import dtw_visualisation as dtwvis
import numpy as np
s1 = np.array([0., 0, 1, 2, 1, 0, 1, 0, 0, 2, 1, 0, 0])
s2 = np.array([0., 1, 2, 3, 1, 0, 0, 0, 2, 1, 0, 0, 0])
path = dtw.warping_path(s1, s2)
dtwvis.plot_warping(s1, s2, path, filename="warp.png")
两个时间序列之间的 DTW 距离度量
from dtaidistance import dtw
s1 = [0, 0, 1, 2, 1, 0, 1, 0, 0]
s2 = [0, 1, 2, 0, 0, 0, 0, 0, 0]
distance = dtw.distance(s1, s2)
print(distance)
计算更快的方法:
from dtaidistance import dtw
import array
s1 = array.array('d', [0, 0, 1, 2, 1, 0, 1, 0, 0])
s2 = array.array('d', [0, 1, 2, 0, 0, 0, 0, 0, 0])
distance = dtw.distance_fast(s1, s2, use_pruning = True) # prunes computations by setting max_dist to the Euclidean upper bound:
Numpy array 作为输入:
from dtaidistance import dtw
import numpy as np
s1 = np.array([0, 0, 1, 2, 1, 0, 1, 0, 0], dtype = np.double)
s2 = np.array([0.0, 1, 2, 0, 0, 0, 0, 0, 0], dtype = np.double)
distance = dtw.distance_fast(s1, s2, use_pruning = True)
print(distance)
计算 DTW 保留所有扭曲的路径
from dtaidistance import dtw
s1 = [0, 0, 1, 2, 1, 0, 1, 0, 0]
s2 = [0, 1, 2, 0, 0, 0, 0, 0, 0]
distance, paths = dtw.warping_paths(s1, s2)
print(distance)
print(paths)
from dtaidistance import dtw
from dtaidistance import dtw_visualisation as dtwvis
import random
import numpy as np
random.seed(1)
# series
x = np.arange(0, 20, .5)
s1 = np.sin(x)
s2 = np.sin(x - 1)
for idx in range(len(s2)):
if random.random() < 0.05:
s2[idx] += (random.random() - 0.5) / 2
# dtw
d, paths = dtw.warping_paths(s1, s2, window=25, psi=2)
best_path = dtw.best_path(paths)
dtwvis.plot_warpingpaths(s1, s2, paths, best_path)
多个时间序列之间的 DTW
输入时间序列位数组的列表:
from dtaidistance import dtw
import numpy as np
timeseries = [
np.array([0, 0, 1, 2, 1, 0, 1, 0, 0], dtype = np.double),
np.array([0.0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0]),
np.array([0.0, 0, 1, 2, 1, 0, 0, 0])
]
ds = dtw.distance_matrix_fast(timeseries)
print(ds)
矩阵形式(列表的列表),需要所有时间序列的长度相同:
from dtaidistance import dtw
import numpy as np
timeseries = np.array([
[0.0, 0, 1, 2, 1, 0, 1, 0, 0],
[0.0, 1, 2, 0, 0, 0, 0, 0, 0],
[0.0, 0, 1, 2, 1, 0, 0, 0, 0]])
ds = dtw.distance_matrix_fast(timeseries)
限制块的多个时间序列之间的 DTW
from dtaidistance import dtw
import numpy as np
timeseries = np.array([
[0., 0, 1, 2, 1, 0, 1, 0, 0],
[0., 1, 2, 0, 0, 0, 0, 0, 0],
[1., 2, 0, 0, 0, 0, 0, 1, 1],
[0., 0, 1, 2, 1, 0, 1, 0, 0],
[0., 1, 2, 0, 0, 0, 0, 0, 0],
[1., 2, 0, 0, 0, 0, 0, 1, 1]])
ds = dtw.distance_matrix_fast(timeseries, block=((1, 4), (3, 5)))
from dtaidistance import dtw
import numpy as np
timeseries = np.array([
[0., 0, 1, 2, 1, 0, 1, 0, 0],
[0., 1, 2, 0, 0, 0, 0, 0, 0],
[1., 2, 0, 0, 0, 0, 0, 1, 1],
[0., 0, 1, 2, 1, 0, 1, 0, 0],
[0., 1, 2, 0, 0, 0, 0, 0, 0],
[1., 2, 0, 0, 0, 0, 0, 1, 1]])
ds = dtw.distance_matrix_fast(timeseries, block=((1, 4), (3, 5)), compact=True)
基于形状的 DTW
如果只想比较形状,而不是绝对差异和偏移量,则需要先转换数据
Z-score normalize:
import numpy as np
from scipy import stats
a = np.array([0.1, 0.3, 0.2, 0.1])
az = stats.zscore(a)
# az = array([-0.90453403, 1.50755672, 0.30151134, -0.90453403])
Differencing:
series = dtaidistance.preprocessing.differencing(series, smooth = 0.1)
多维 DTW
from dtaidistance import dtw_ndim
series1 = np.array([[0, 0], # first 2-dim point at t=0
[0, 1], # second 2-dim point at t=1
[2, 1],
[0, 1],
[0, 0]], dtype=np.double)
series2 = np.array([[0, 0],
[2, 1],
[0, 1],
[0, .5],
[0, 0]], dtype=np.double)
d = dtw_ndim.distance(series1, series2)