回归和时序评价指标
wangzf / 2022-11-22
目录
普通回归
时间序列预测
最常见的时间序列预测损失函数是 MSE、MAE 等点误差函数,这类函数关注每个点的拟合是否准确。 然而,这种损失函数完全忽略了不同点的关系,在时间序列中忽略了各个点的时序关系, 导致了预测结果的形状和真实序列不匹配的问题
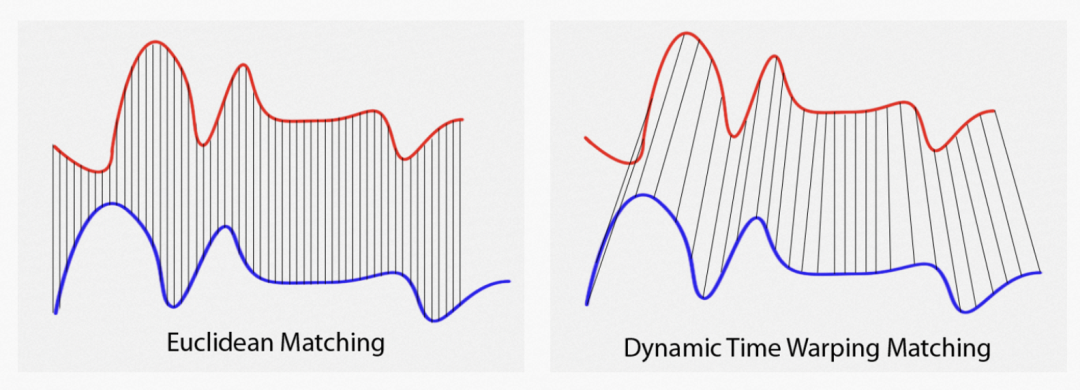
针对 MSE 等损失函数的问题,业内提出一种针对时间序列预测问题的 DTW 损失函数。DTW 损失函数的核心思路是, 利用动态规划方法,对两个序列的点之间进行匹配,找到让两个序列相似度最高的匹配方式。 在这种最相似的匹配结果下,两个时间序列的距离就是最终真正的差异,也就可以转换成损失函数。 DTW 充分考虑了两个序列各个点之间的关系,通过扭曲重整序列进行对齐,计算最短距离,实现形状上的匹配
后续也有很多工作针对 DTW 在时间序列预测中的应用进行优化。DTW 也有其缺点,对齐过程容易受到噪声影响, 且对齐过程一定程度上丢失了序列的时间位置信息,一般会影响 MSE 等评价指标
损失函数对模型在给定目标上进行良好拟合起着关键作用。对于时间序列预测等复杂目标, 不可能确定通用损失函数,有很多因素,如异常值、数据分布的偏差、ML模型要求、计算要求和性能要求等。 没有适用于所有类型数据的单一损失函数
特定损失函数可能有用的情况,例如在数据集中出现异常值的情况下,MSE 是最佳策略; 然而,如果有更少的异常值,则MAE将是比MSE更好的选择。同样,如果我们希望保持平衡, 并且目标基于百分位数损失,那么使用 LogCosh 是更好的方法
MBE
Mean Bias Error,MBE,平均偏差误差
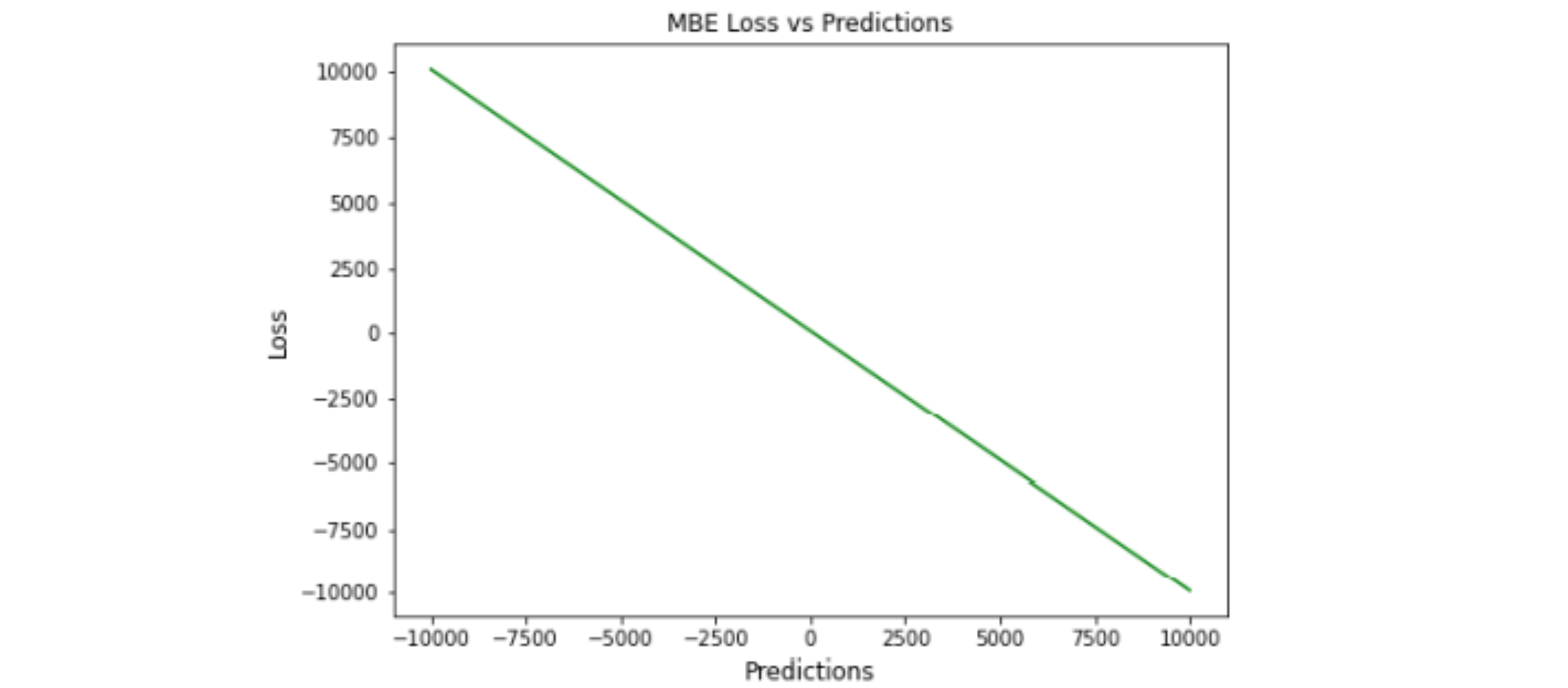
MBE 是测量过程高估或低估参数值的趋势。偏差只有一个方向,可以是正的,也可以是负的。 正偏差意味着数据的误差被高估,负偏差意味着误差被低估。MBE 是预测值与实际值之差的平均值。 该评估指标量化了总体偏差并捕获了预测中的平均偏差。它几乎与 MAE 相似, 唯一的区别是这里没有取绝对值。这个评估指标应该小心处理,因为正负误差可以相互抵消
高估或低估参数值的倾向称为偏差或平均偏差误差。偏差的唯一可能方向是正向或负向。 正偏差表示数据误差被高估,而负偏差表示误差被低估。实际值和预期值之间的差异被测量为平均偏差误差 (MBE)。 除了不考虑绝对值外,它实际上与 MAE 相同。需要注意的是,MBE 正向误差和负向误差可能会相互抵消
优点:
- 想检查模型的方向(即是否存在正偏差或负偏差)并纠正模型偏差,MBE 是一个很好的衡量标准
- 如果您希望识别和纠正模型偏差,则应使用 MBE 确定模型的方向(即它是正向还是负向)
缺点:
- 就幅度而言,这不是一个好的衡量标准,因为误差往往会相互补偿
- 它的可靠性不高,因为有时高个体错误会产生低 MBE
- 作为一种评估指标,它在一个方向上可能始终是错误的
- MBE 倾向于在一个方向上不断犯错。考虑到误差往往会相互抵消, 对于 范围的数字,不是一个合适的损失函数
MAE
Mean Absolute Error, MAE
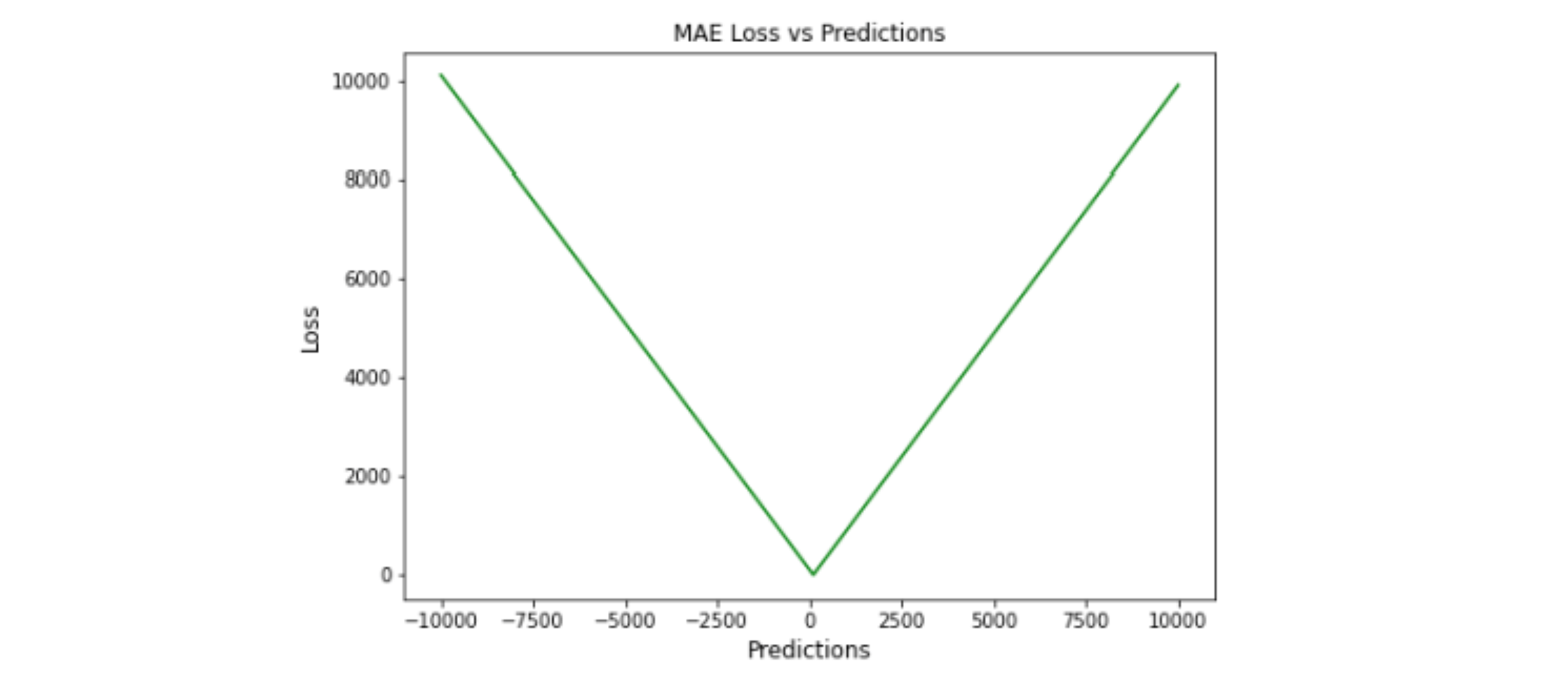
MAE(Mean Absolute Error,平均绝对误差) 也称为 L1 损失函数。是最简单的损失函数之一,也是一种易于理解的评价指标。 它是通过取预测值和实际值之间的绝对差值并在整个数据集中取平均值来计算的。 从数学上讲,它是绝对误差的算术平均值。MAE 仅测量误差的大小,不关心它们的方向。 MAE 越低,模型的准确性就越高
优点:
- 由于采用了绝对值,因此所有误差都以相同的比例加权
- 如果训练数据有异常值,MAE 不会惩罚由异常值引起的高错误
- MAE 计算简单,并提供了模型执行情况(模型性能)的平均度量
缺点:
- 有时来自异常值的大错误最终被视为与低错误相同
- 在零处不可微分。许多优化算法倾向于使用微分来找到评估指标中参数的最佳值。在 MAE 中计算梯度可能具有挑战性。
- MAE 遵循线性平分方法,意味着在计算平均值时,所有误差都被平均加权
- 由于 MAE 的陡峭性,可能会在反向传播过程中跳过最小值
MSE
Mean Square Error,MSE,均方误差或 L2 损失
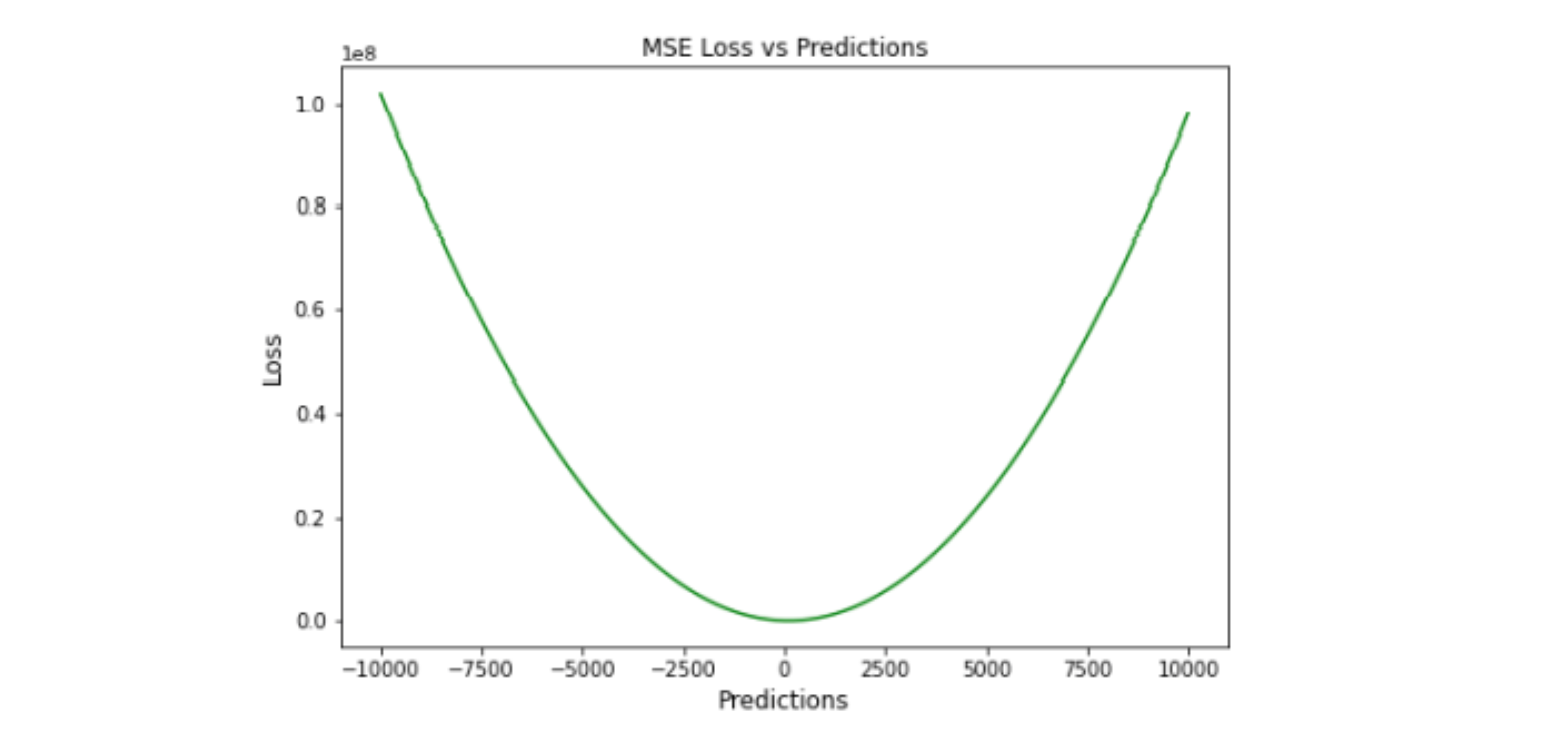
MSE 也称为 L2 损失,MSE 通过将预测值和实际值之间的差平方并在整个数据集中对其进行平均来计算误差。 MSE 也称为二次损失,因为惩罚与误差不成正比,而是与误差的平方成正比。平方误差为异常值赋予更高的权重, 从而为小误差产生平滑的梯度
MSE 永远不会是负数,因为误差是平方的。误差值范围从零到无穷大。 MSE 随着误差的增加呈指数增长。一个好的模型的 MSE 值接近于零
优点:
- MSE 会得到一个只有一个全局最小值的梯度下降
- 对于小的误差,它可以有效地收敛到最小值。没有局部最小值
- MSE 通过对模型进行平方来惩罚具有巨大错误的模型
- 当梯度逐渐减小时,MSE 有助于对微小错误进行有效的最小收敛。 MSE 值用二次方程表示,有助于在异常值的情况下调整模型参数
缺点:
- 对异常值的敏感性通过对它们进行平方来放大高误差
- MSE 会受到异常值的影响,会寻找在整体水平上表现足够好的模型
- 较高的损失值可能会导致反向传播过程中的大幅跳跃,这是不可取的。 MSE 对异常值特别敏感,这意味着数据中的显著异常值可能会影响我们的模型性能
回归问题的性能度量方法与其常用的损失函数一样,都是均方误差。 MSE 是可以直接优化的函数,所以直接默认选用平方损失函数进行优化即可, 很多工具包里面也称之为 L2 损失
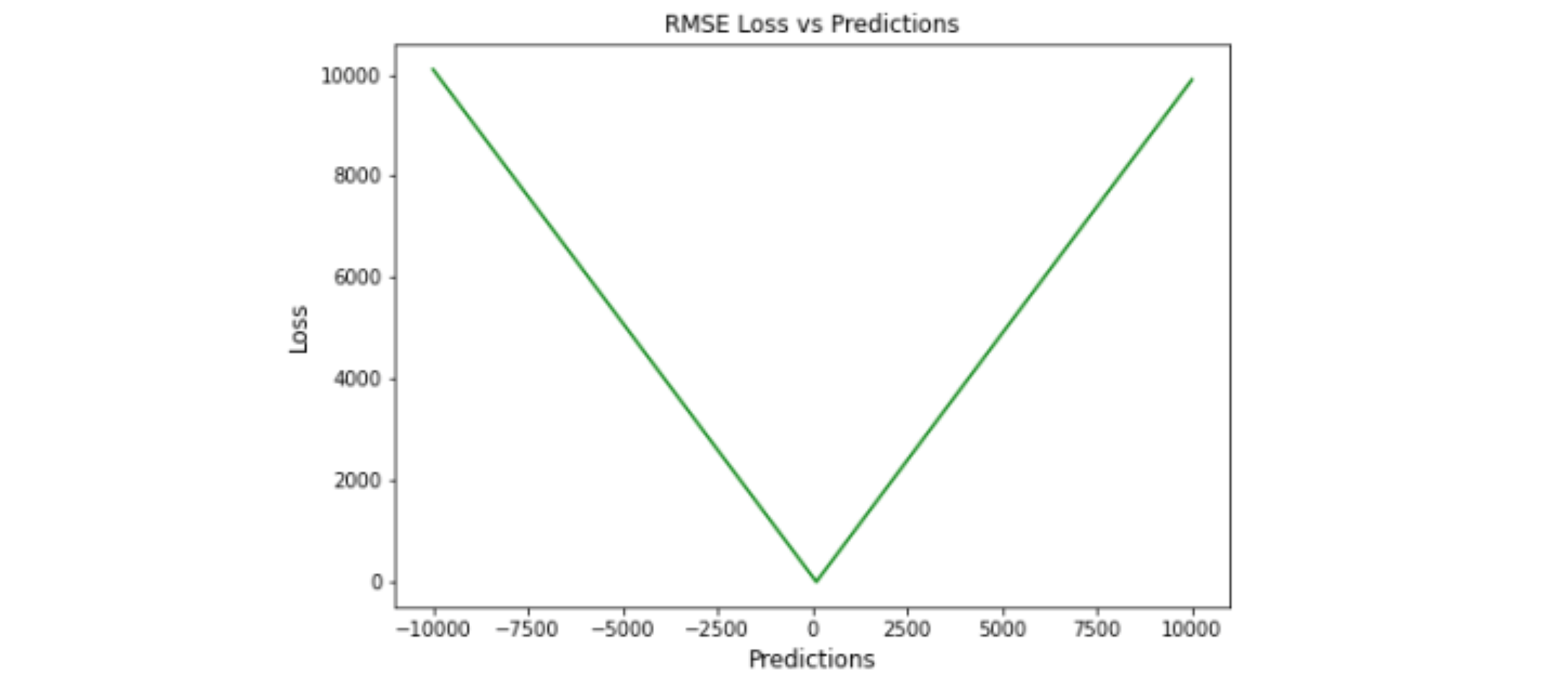
RMSE
Root Mean Square Error,RMSE,均方根误差
RMSE 是通过取 MSE 的平方根来计算的。RMSE 也称为均方根偏差。 它测量误差的平均幅度,并关注与实际值的偏差。RMSE 值为零表示模型具有完美拟合。 RMSE 越低,模型及其预测就越好
优点:
- 易于理解
- 计算方便
- 许多优化方法选择 RMSE,因为它容易区分,并且计算简单。即使值很大, 极端损失少,平方根导致 RMSE 惩罚的误差会小于 MSE
缺点:
- 建议去除异常值才能使其正常运行
- 会受到数据样本大小的影响
- 由于 RMSE 仍然是一个线性平分函数,所以梯度在最小值附近是突变的。 随着误差幅度的增加,RMSE 对异常值的敏感性也随之增加。为了收敛模型, 必须降低灵敏度,从而导致使用 RMSE 的额外开销
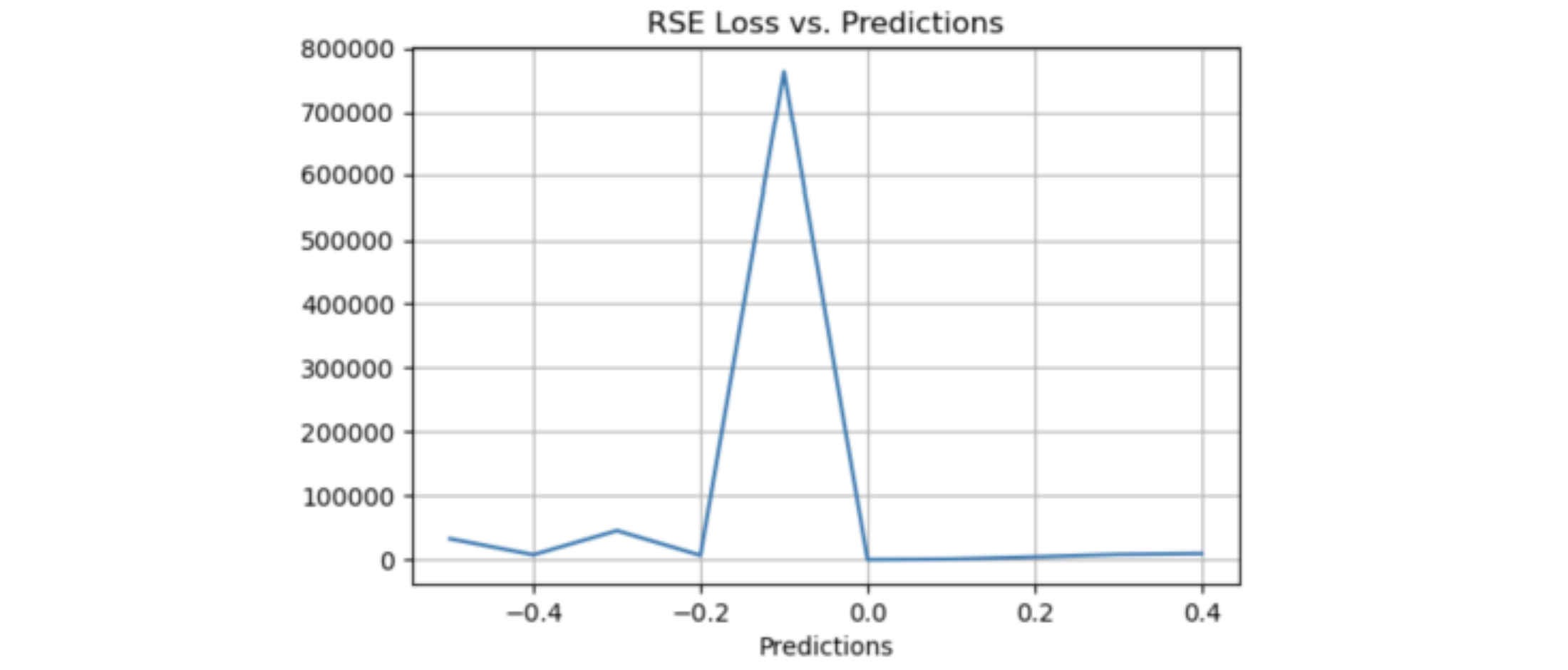
RSE
Relative Squared Error,RSE,相对平方误差
RSE 需要使用均方误差并将其除以实际数据与数据平均值之间的差异的平方。 RSE 衡量在没有简单预测器的情况下结果的不准确程度。这个简单的预测变量仅代表实际值的平均值。 RSE 通过简单预测变量的总平方误差对其进行归一化。可以在以不同单位计算误差的模型之间进行比较
其中:
优点:
- 对预测的平均值和规模不敏感
- RSE 与规模无关。当以不同单位测量误差时,它可以比较模型
缺点:
- RSE 不受预测的平均值或大小的影响
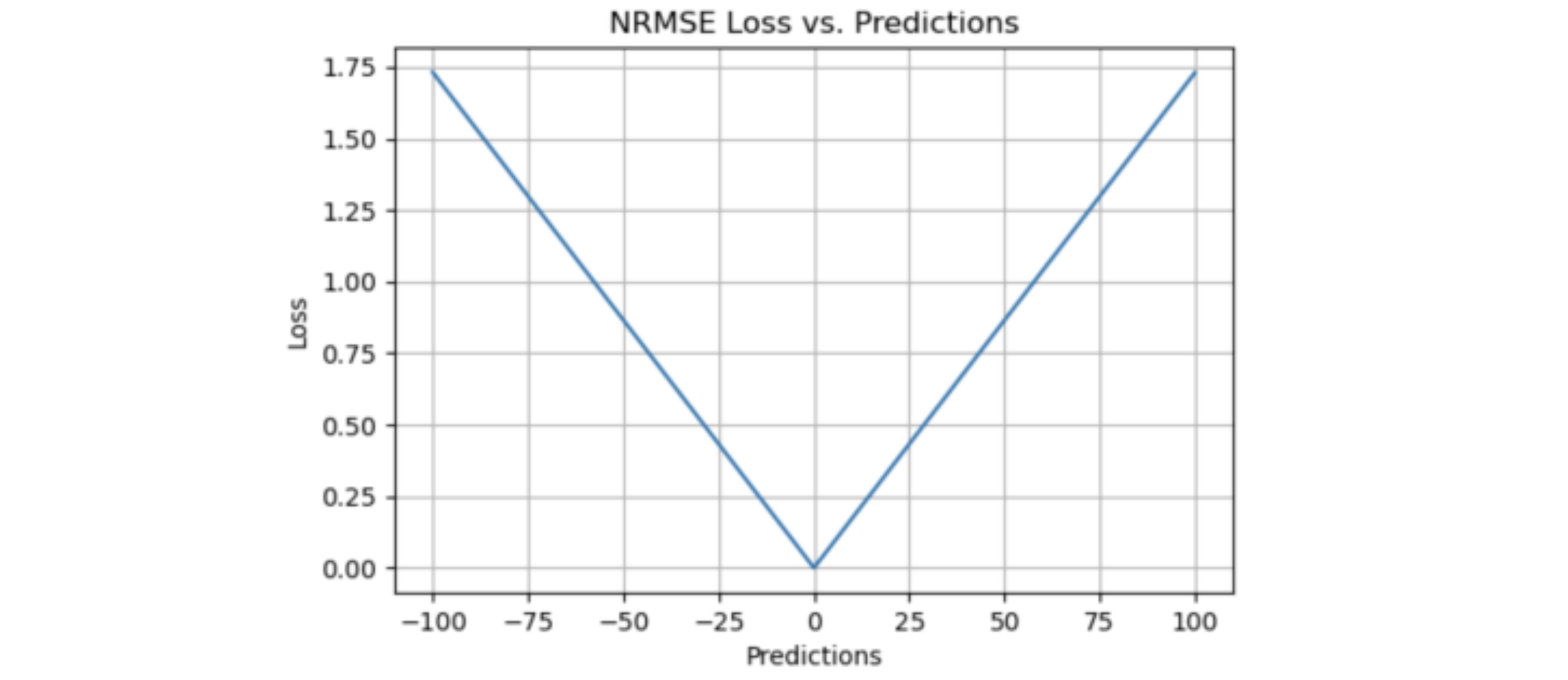
NRMSE
Normalized Root Mean Squared Error,NRMSE,归一化 RMSE
归一化 RMSE 通常通过除以一个标量值来计算,它可以有不同的方式。 有时选择四分位数范围可能是最好的选择,因为其他方法容易出现异常值。 当您想要比较不同因变量的模型或修改因变量时,NRMSE 是一个很好的度量。 它克服了尺度依赖性,简化了不同尺度模型甚至数据集之间的比较
归一化均方根误差 (NRMSE) 有助于不同尺度模型之间的比较。该变量可以将 RMSE 观测范围归一化
- RMSE / maximum value in the series
- RMSE / mean
- RMSE / difference between the maximum and the minimum values (if mean is zero)
- RMSE / standard deviation
- RMSE / interquartile range
优点:
- NRMSE 克服了尺度依赖性,简化了不同尺度或数据集模型之间的比较
缺点:
- NRMSE 失去与响应变量相关的单位
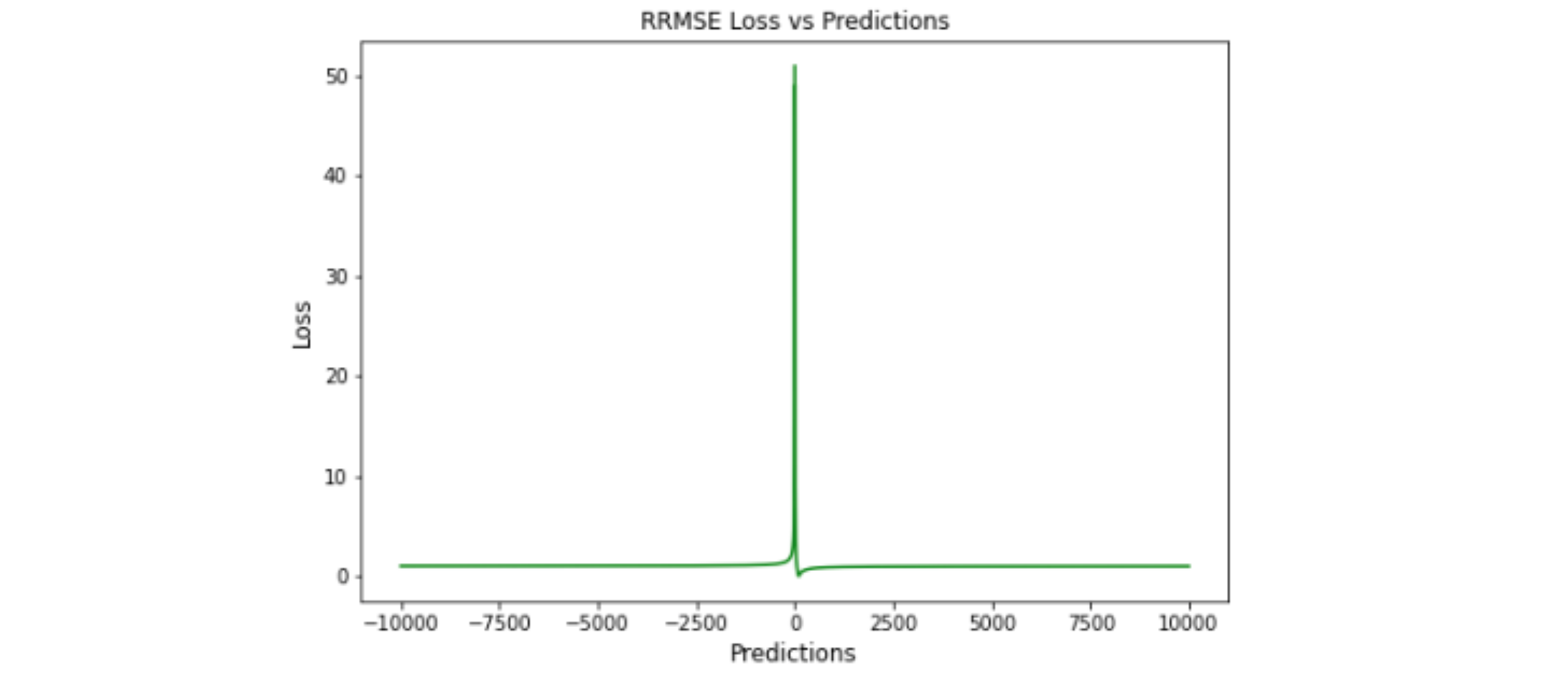
RRMSE
Relative Root Mean Squared Error,RRMSE,相对 RMSE
RRMSE 是 RMSE 的无量纲形式,是由均方根值归一化的均方根误差,其中每个残差都根据实际值进行缩放
相对均方根误差 (RRMSE) 是一种均方根误差度量,是没有维度的 RMSE 的变体。 它根据实际值进行缩放,然后由均方根值归一化。虽然原始测量的尺度限制了 RMSE, 但 RRMSE 可用于比较各种测量方法。当预测被证明是错误时,会出现增强的 RRMSE
- Excellent when RRMSE < 10%
- Good when RRMSE is between 10% and 20%
- Fair when RRMSE is between 20% and 30%
- Poor when RRMSE > 30%
优点:
- RRMSE 可用于比较不同的测量技术
缺点:
- RRMSE 隐藏实验结果中的不精确性
RAE
Relative Absolute Error,RAE,相对绝对误差
RAE 是通过将总绝对误差除以实际值与平均值之间的绝对差来计算的。 RAE 以比率表示,用于评估预测模型的有效性。范围值在 。一个好的模型将具有接近于零的值, 其中零是最佳值
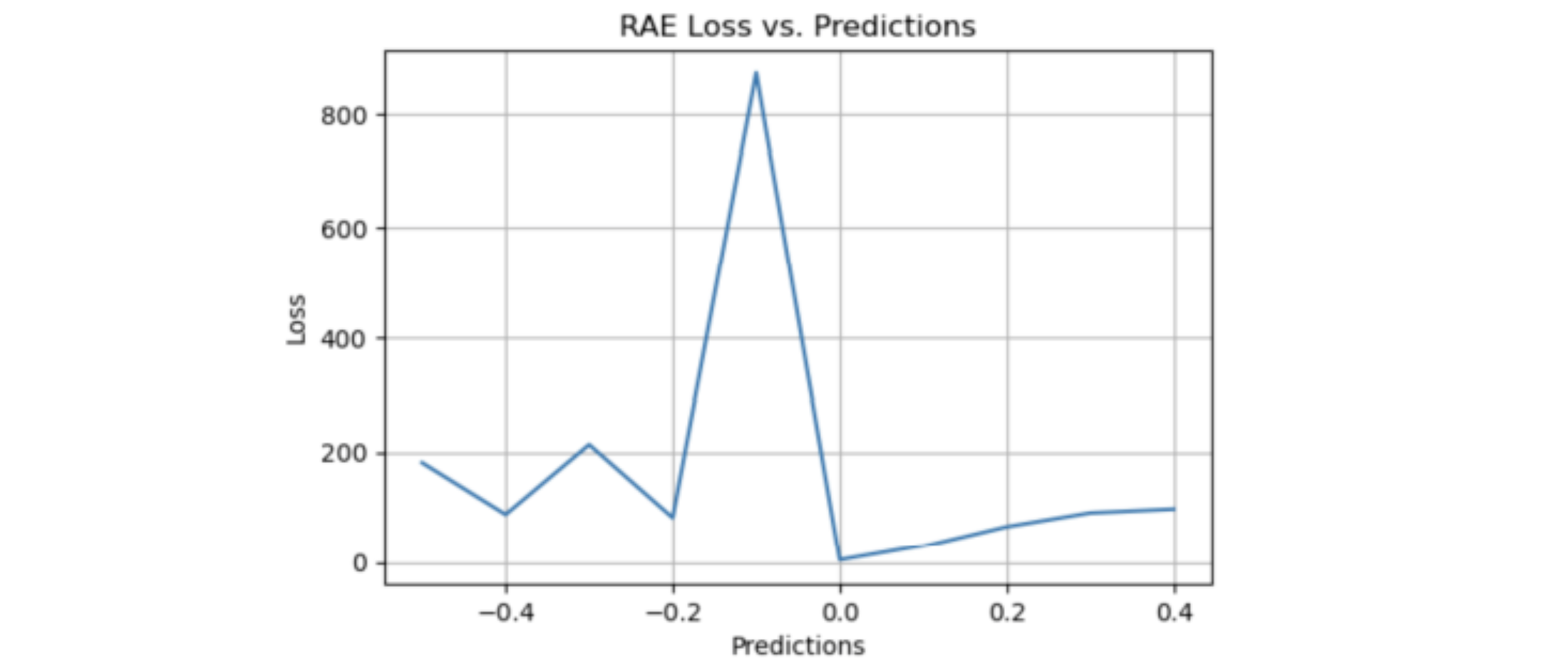
其中:
优点:
- RAE 可用于比较以不同单位测量误差的模型
- RAE 是可靠的,因为它可以防止异常值
缺点:
- 如果参考预测等于真值,RAE 可能变得不可预测
MSLE
Mean Squared Logarithmic Error,MSLE
均方对数误差 (MSLE) 衡量实际值与预期值之间的差异。 通过对数减少对实际值和预测值之间的百分比差异以及两者之间的相对差异的关注。 MSLE 将粗略地处理实际值和预期值之间的微小差异以及大的真实值和预测值之间的巨大差异
这种损失可以解释为真实值和预测值之间比率的度量:
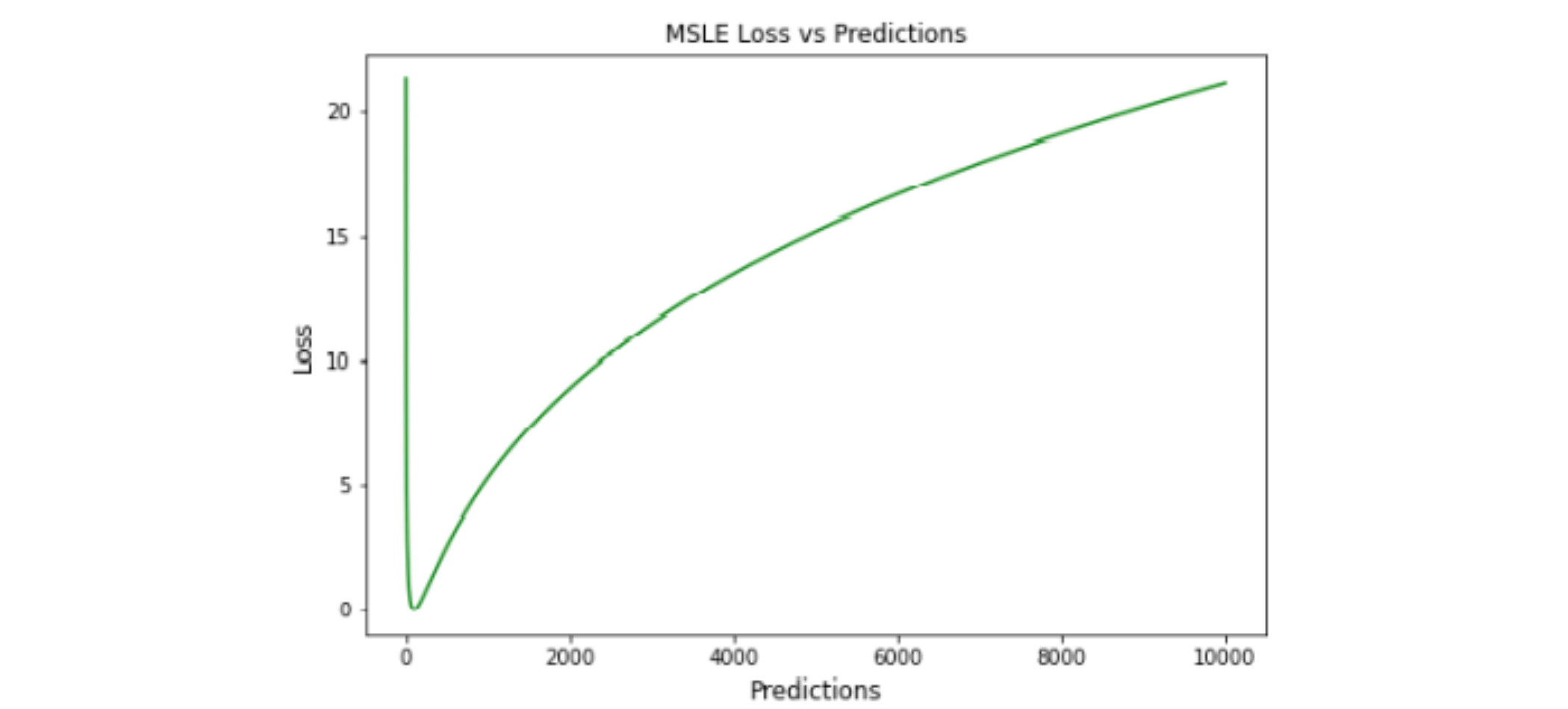
优点:
- 将实际值和预测值之间的小差异和大差异进行粗略处理
缺点:
- MSLE 对不充分的预测的惩罚比对过度预测的惩罚更多
RMSLE
Root Mean Squared Logarithmic Error,RMSLE,均方根对数误差
均方根对数误差是通过将 log 应用于实际值和预测值然后取它们的差异来计算的。 RMSLE 对于小误差和大误差被均匀处理的异常值是稳健的。如果预测值小于实际值, 则对模型进行更多的惩罚,而如果预测值大于实际值,则对模型进行较少的惩罚。 当同时考虑小误差和大误差时,RMSLE 可以避免异常值的影响
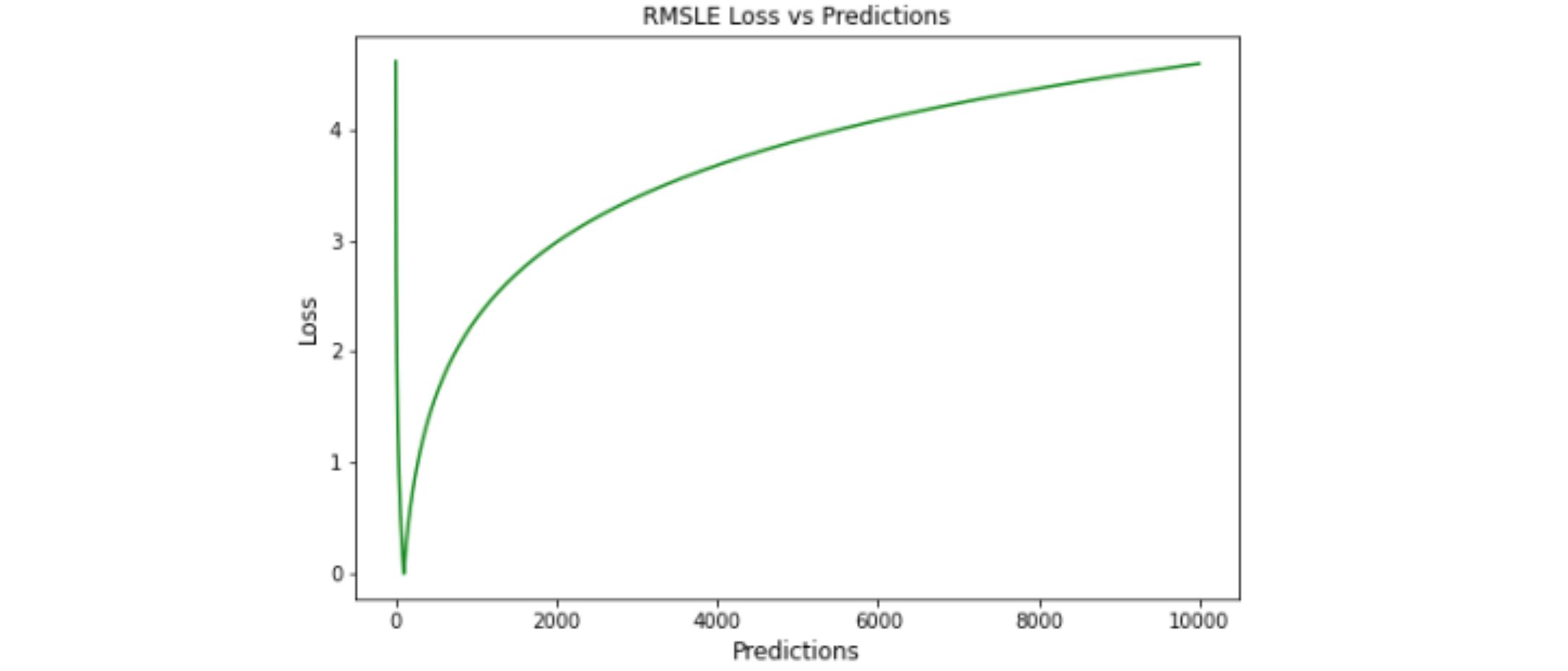
优点:
- 不依赖于比例,并且适用于各种比例。
- 它不受大异常值的影响。
- 它只考虑实际值和预测值之间的相对误差
- RMSLE 适用于多种尺度,且不依赖于尺度。它不受显著异常值的影响。仅考虑实际值与预期值之间的相对误差
缺点:
- RMSLE 是有偏见的处罚,低估比高估受到更严重的惩罚
MAPE
Mean Absolute Percentage Error,MAPE,平均绝对百分比误差
平均绝对百分比误差 (MAPE),也称为平均绝对百分比偏差 (MAPD),是用于评估预测系统准确性的指标。 它通过实际值减去预测值的绝对值除以实际值来计算每个时间段的平均绝对误差百分比。 由于单位缩放为百分比,因此广泛用于预测误差。当数据中没有异常值时,它效果很好,常用于回归分析和模型评估
MAPE 是通过将实际值与预测值之间的差值除以实际值来计算的。 MAPE 随着误差的增加而线性增加。MAPE 越小,模型性能越小
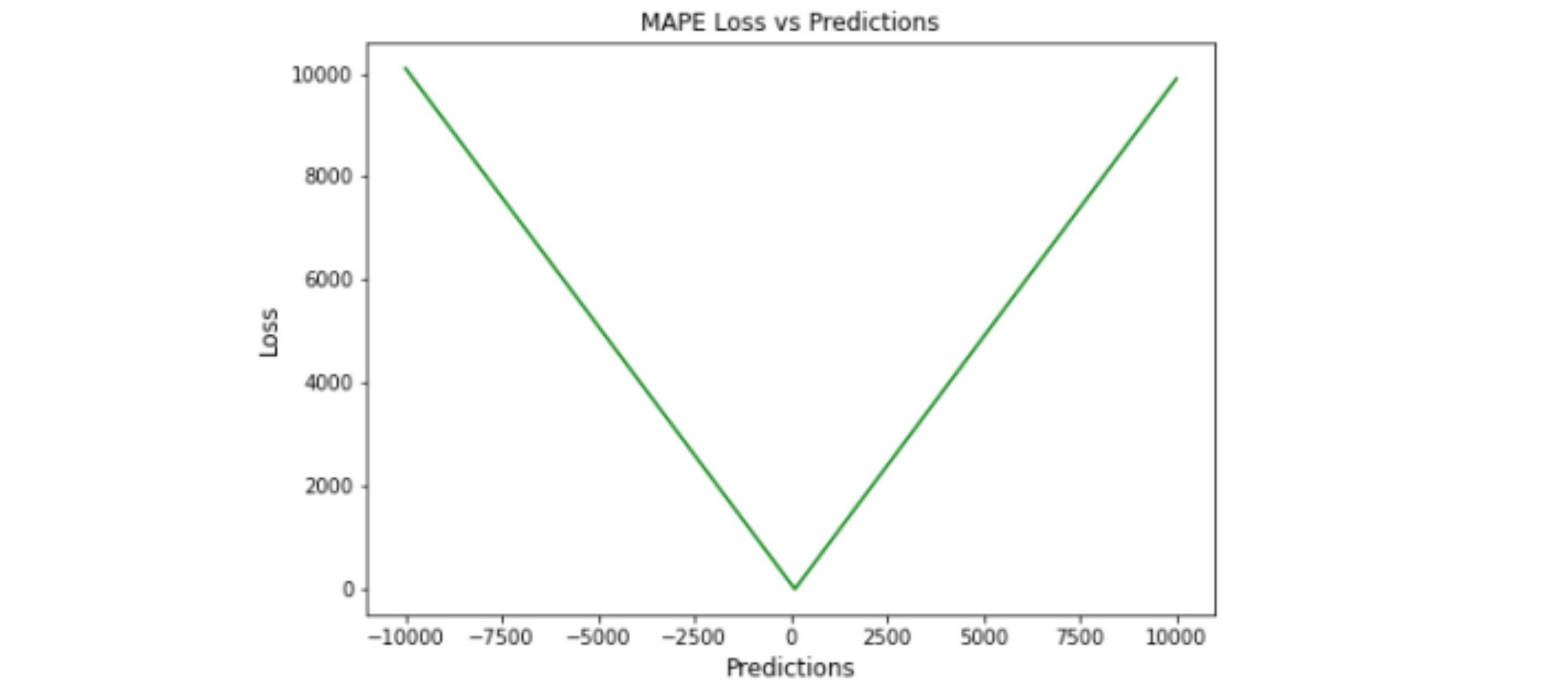
优点:
- MAPE 与变量的规模无关,因为它的误差估计是以百分比为单位的
- 所有错误都在一个共同的尺度上标准化,很容易理解
- MAPE 避免了正值和负值相互抵消的问题
- MAPE 损失是通过将所有误差标准化为百分比来计算的,因此与变量的规模无关,同时也可以避免正数抵消负数的问题
缺点:
- 因为 MAPE 方程的分母是预测输出,它可以是零,导致未定义的值。MAPE 对正 Loss 的惩罚小于负 Loss。 因此,当我们比较预测算法的精度时,它是有偏差的,因为它默认选择结果低的参数
- 分母值为零时,面临着“除以零”的问题
- MAPE 对数值较小的误差比对数值大的误差错误的惩罚更多
- 因为使用除法运算,对于相同的误差,实际值的变化将导致损失的差异
WMAPE 和 SMAPE
在指标方面,作为一个回归问题,可以使用 MAE,MSE 等方式来计算。但这类 metric 受到具体预测数值区间范围不同, 展现出来的具体误差值区间也会波动很大。比如预测销量可能是几万到百万,而预测车流量可能是几十到几百的范围, 那么这两者预测问题的 MAE 可能就差距很大,很难做多个任务间的横向比较
所以实际问题中,经常会使用对数值量纲不敏感的一些 metric,尤其是 SMAPE 和 WMAPE 这两种。 这类误差计算方法在各类不同的问题上都会落在 的区间范围内,方便来进行跨序列的横向比较,十分方便
在实际项目中还会经常发现,很多真实世界的时序预测目标,如销量,客流等,都会形成一个类似 tweedie 或 poisson 分布的情况。 如果用 WMAPE 作为指标,模型优化目标基本可以等价为 MAE(优化目标为中位数),则整体的预测就会比平均值小(偏保守)
在很多业务问题中,预测偏少跟预测偏多造成的影响是不同的,所以实际在做优化时,可能还会考察整体的预测偏差(总量偏大或偏小), 进而使用一些非对称 loss 来进行具体的优化
Huber Loss
Huber损失是线性和二次评分方法的组合。它有一个超参数 delta,可以根据数据进行调整。 对于高于 的值,损失将是线性的(L1 损失),对于低于 的值,损失将是二次的(L2 损失)。 它平衡并结合了 MAE(平均绝对误差)和 MSE(均方误差)的良好特性
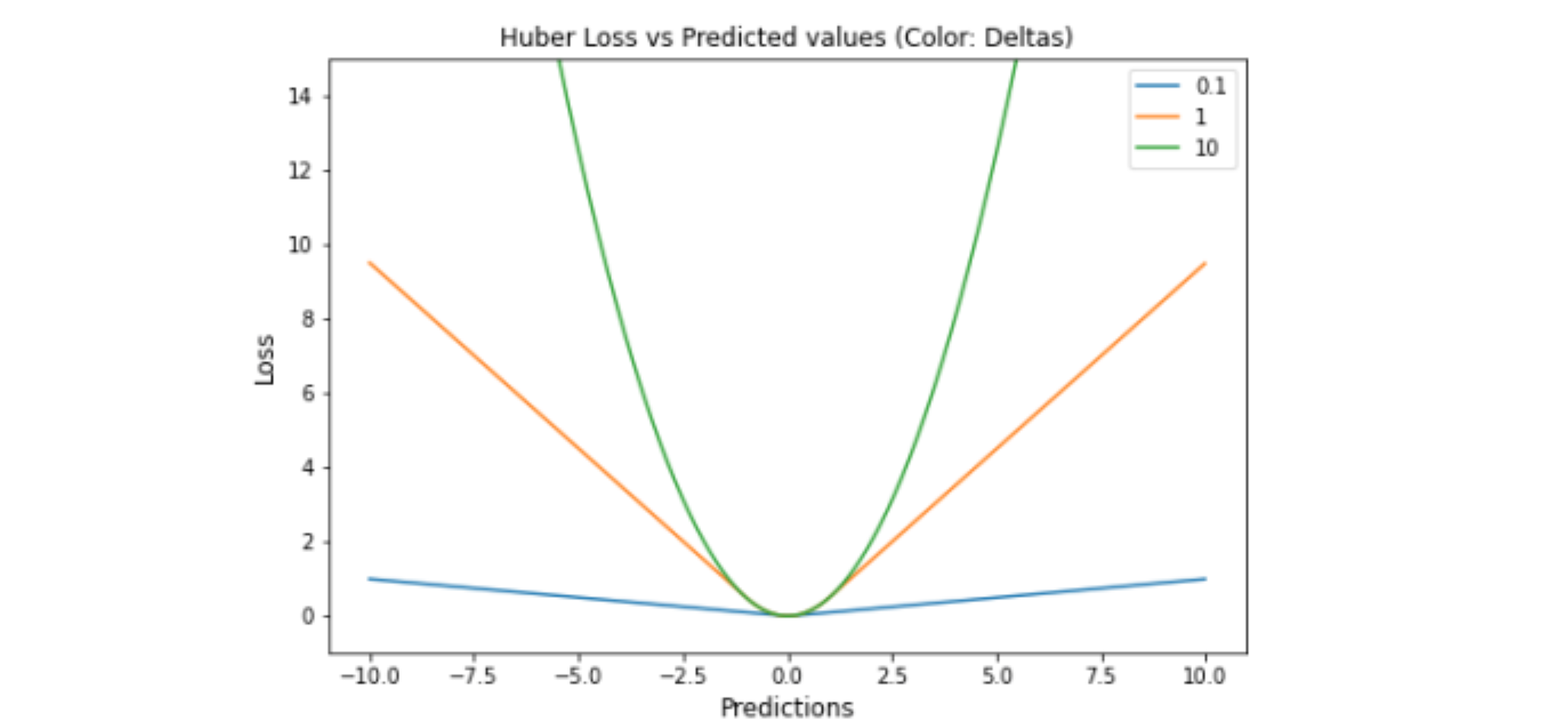
优点:
- 超参数 以上的线性保证了异常值被赋予适当的权重,不像 MSE 中那样极端, 并且允许灵活地适应任何分布。超参数 以下的弯曲形状保证了在反向传播过程中梯度长是正确的
- 它在零处是可微的
- 由于 以上的线性度,异常值得到了正确处理
- 可以调整超参数delta以最大限度地提高模型准确性
缺点:
- 为了最大限度地提高模型精度,需要优化delta,这是一个迭代过程
- 它只能微分一次
- 由于额外的条件和比较,Huber Loss 在计算上非常昂贵,特别是数据集很大的情况
Log Cosh Loss
LogCosh 计算 Loss 的双曲余弦对数。这个函数比二次损失函数更平滑。它的功能类似于 MSE, 但不受重大预测误差的影响。鉴于它使用线性和二次平分方法,它非常接近 Huber Loss
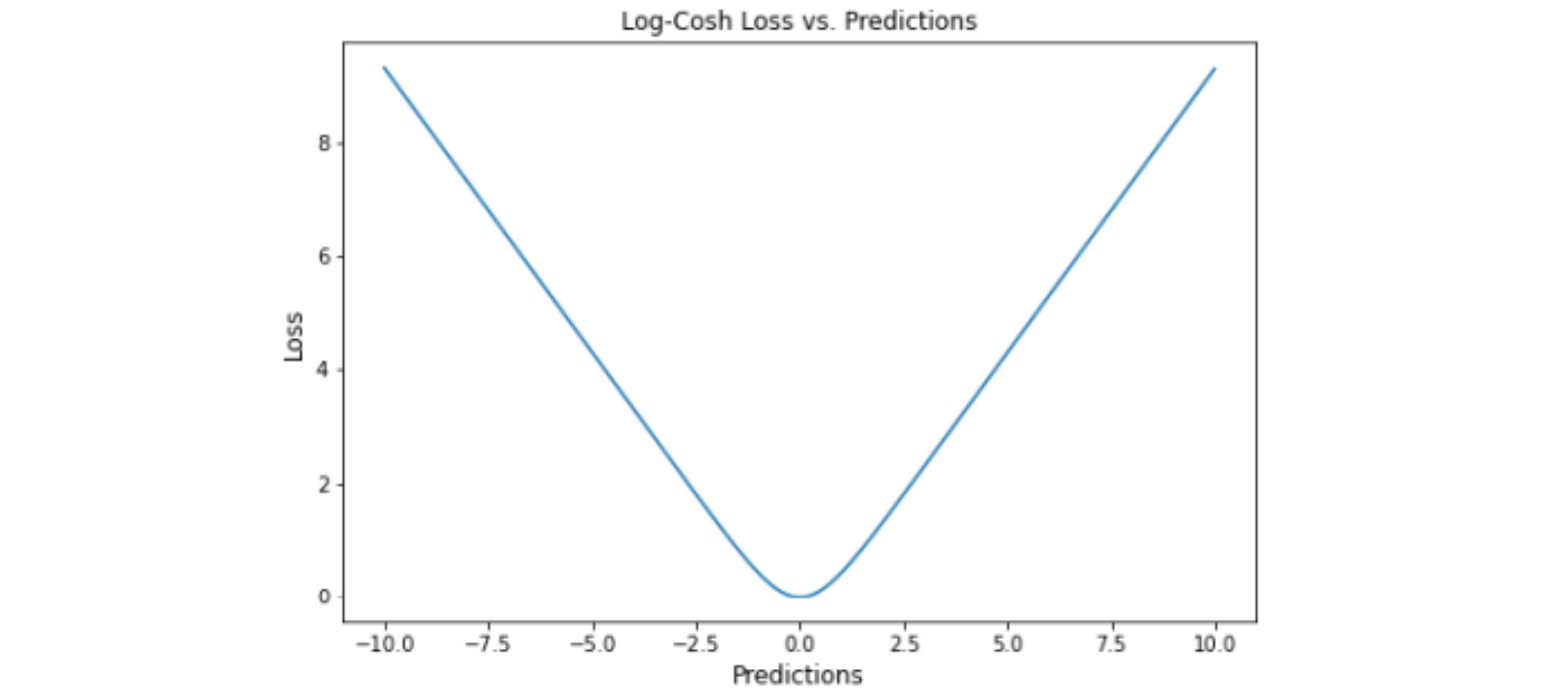
优点:
- 同时处处可二次微分
- 由于其连续性和可微性,它比Huber Loss 所需的计算要少
缺点:
- 适应性较差,因为它遵循固定的比例
- 它的适应性不如 Huber Loss,因为没有超参数进行调节。推导比 Huber Loss 更复杂,需要更多的研究
Quantile Loss
分位数回归损失函数用于预测分位数。分位数是确定组中有多少值低于或高于某个限制的值。 它跨预测变量(自变量)的值估计响应变量(因变量)的条件中位数或分位数
分位数回归损失函数用于预测分位数。分位数是指数据中有多少值低于或高于某特定的阈值。 除了第 50 个百分位数是 MAE,其余位置是 MAE 的扩展。它不对响应的参数分布做出任何假设
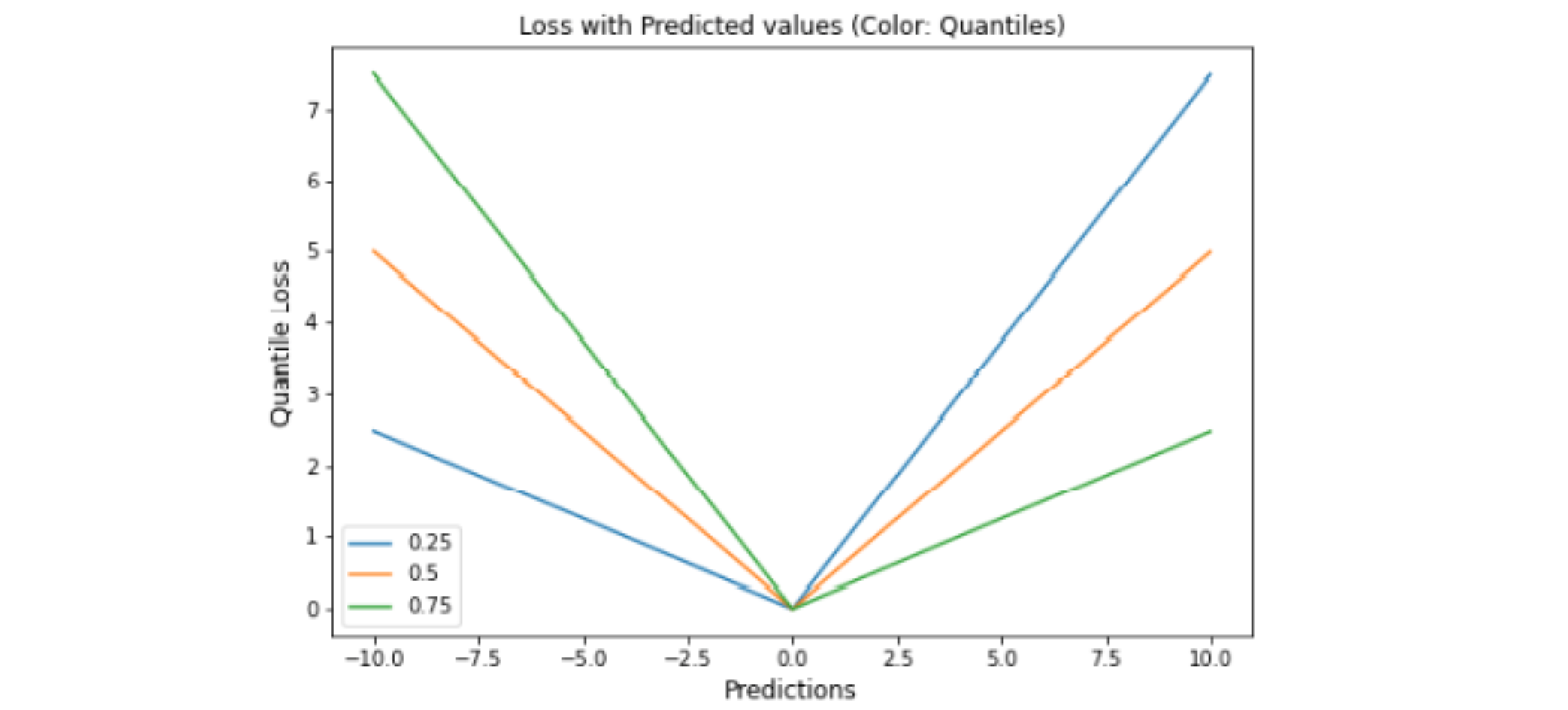
优点:
- 可以避免异常值的影响。与点预测相比,这有利于进行区间预测。该函数也可用于神经网络和基于树的模型中,以确定预测间隔
缺点:
- Quantile Loss 是计算密集型的。如果我们估计平均值或使用平方损失来量化效率,则 Quantile Loss 将比较糟
TILDE-Q 损失
第一个损失函数是 Amplitude Shifting Invariance with Softmax,目标是让所有时刻的预测结果和真实结果的距离是一个常数 k。 为了达成这个目标,文中使用了 softmax 函数。Softmax 中传入各个时间点的预测结果和真实结果的距离, 只有当所有距离都相同时候,这个函数才会得到最小值
第二个损失函数是 Invariances with Fourier Coefficients。通过对时间序列进行傅里叶变换, 获取预测结果和真实结果的主成分,使用范数对比两个序列的主成分差异作为损失函数,主成分差异越小, 对应的 loss 越小,以此引入了平移不变性
第三个损失函数是 Invariances with auto-correlation,计算真实序列的自相关系数, 以及预测结果和真实序列的相关系数,比较二者的差异
最终的 TILDE-Q 损失函数是上面 3 种衡量不变性损失函数的加权求和:
DTW