pmdarima
Auto ARIMA
wangzf / 2022-11-12
安装及加载
依赖
- Numpy (>=1.17.3)
- SciPy (>=1.3.2)
- Scikit-learn (>=0.22)
- Pandas (>=0.19)
- Statsmodels (>=0.11)
PyPI
$ pip install pmdarima
Conda
$ conda config --add channels conda-forge
$ conda config --set channel_priority strict
$ conda install pmdarima
常规使用方式
import pmdarima as pm
from pmdarima.arima import auto_arima
API
import pmdarima as pm
arima
from pmdarima import arima
- ARIMA estimator & statistical tests
arima.ADFTestarima.ARIMAarima.AutoARIMAarima.CHTestarima.KPSSTestarima.OCSBTestarima.PPTestarima.StepwiseContext
- ARIMA auto-parameter selection
arima.auto_arima
- Differencing helpers
arima.is_constantarima.ndiffsarima.nsidffs
- Seasonal decomposition
arima.decompose
datasets
from pydarima import datasets
- Dataset loading functions
datasets.load_airpassengersdatasets.load_ausbeerdatasets.load_austresdatasets.load_gasolinedatasets.load_heartratedatasets.load_lynxdatasets.load_msftdatasets.load_sunspotsdatasets.load_taylordatasets.load_wineinddatasets.load_woolyrnq
metrics
from pmdarima import metrics
- Metrics
metrics.smape:对称平均绝对百分比误差
import numpy as np
y_true = np.array([0.07533, 0.07533, 0.07533, 0.07533, 0.07533, 0.07533, 0.0672, 0.0672])
y_pred = np.array([0.102, 0.107, 0.047, 0.1, 0.032, 0.047, 0.108, 0.089])
smape = metrics.smape(y_true, y_pred)
print(smape)
42.60306631890196
model_selection
from pydarima import model_selection
- Cross validation & split utilities
model_selection.RollingForecastCV([h, step, …])model_selection.SlidingWindowForecastCV([h, …])model_selection.check_cv([cv])model_selection.cross_validate(estimator, y)model_selection.cross_val_predict(estimator, y)model_selection.cross_val_score(estimator, y)model_selection.train_test_split(*arrays[, …])
pipeline
from pydarima.pipeline import Pipeline
- Pipelines
pipeline.Pipeline
preprocessing
from pydarima import preprocessing
- Endogenous transformers
preprocessing.BoxCoxEndogTransformerpreprocessing.LogEndogTransformer
- Exogenous transformers
preprocessing.DateFeaturizerpreprocessing.FourierFeaturizer
utils
from pydarima import utils
- Array helper functions & metaestimators
utils.acfutils.as_seriesutils.cutils.check_endogutils.diffutils.diff_invutils.if_has_delegateutils.is_iterableutils.pacf
- Plotting utilities & wrappers
utils.autocorr_plotutils.decomposed_plotutils.plot_acfutils.plot_pacf
快速开始
创建 Array
import pmdarima as pm
# array like vector in R
x = pm.c(1, 2, 3, 4, 5, 6, 7)
print(x)
[1 2 3 4 5 6 7]
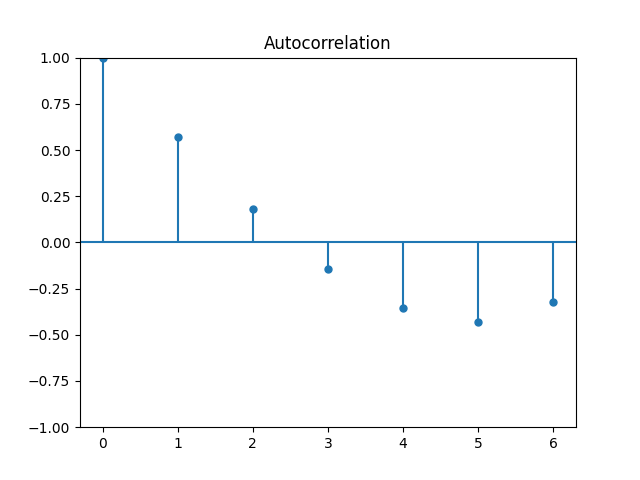
ACF 和 PACF
import pmdarima as pm
# acf
x_acf = pm.acf(x)
print(x_acf)
pm.plot_acf(x)
[ 1.0 0.57142857 0.17857143 -0.14285714 -0.35714286 -0.42857143 -0.32142857]
import pmdarima as pm
# pacf
x_pacf = pm.pacf(x)
print(x_pacf)
pm.plot_pacf(x)
Auto-ARIMA
载入依赖库
import numpy as np
from pmdarima.datasets import load_wineind
import pmdarima as pm
数据
# data
wineind = load_wineind().astype(np.float64)
wineind
array([15136., 16733., 20016., 17708., 18019., 19227., 22893., 23739.,
21133., 22591., 26786., 29740., 15028., 17977., 20008., 21354.,
19498., 22125., 25817., 28779., 20960., 22254., 27392., 29945.,
16933., 17892., 20533., 23569., 22417., 22084., 26580., 27454.,
24081., 23451., 28991., 31386., 16896., 20045., 23471., 21747.,
25621., 23859., 25500., 30998., 24475., 23145., 29701., 34365.,
17556., 22077., 25702., 22214., 26886., 23191., 27831., 35406.,
23195., 25110., 30009., 36242., 18450., 21845., 26488., 22394.,
28057., 25451., 24872., 33424., 24052., 28449., 33533., 37351.,
19969., 21701., 26249., 24493., 24603., 26485., 30723., 34569.,
26689., 26157., 32064., 38870., 21337., 19419., 23166., 28286.,
24570., 24001., 33151., 24878., 26804., 28967., 33311., 40226.,
20504., 23060., 23562., 27562., 23940., 24584., 34303., 25517.,
23494., 29095., 32903., 34379., 16991., 21109., 23740., 25552.,
21752., 20294., 29009., 25500., 24166., 26960., 31222., 38641.,
14672., 17543., 25453., 32683., 22449., 22316., 27595., 25451.,
25421., 25288., 32568., 35110., 16052., 22146., 21198., 19543.,
22084., 23816., 29961., 26773., 26635., 26972., 30207., 38687.,
16974., 21697., 24179., 23757., 25013., 24019., 30345., 24488.,
25156., 25650., 30923., 37240., 17466., 19463., 24352., 26805.,
25236., 24735., 29356., 31234., 22724., 28496., 32857., 37198.,
13652., 22784., 23565., 26323., 23779., 27549., 29660., 23356.])
训练模型
# 拟合 stepwise auto-ARIMA
stepwise_fit = pm.auto_arima(
y = wineind,
start_p = 1,
start_q = 1,
max_p = 3,
max_q = 3,
seasonal = True,
d = 1,
D = 1,
trace = True,
error_action = "ignore",
suppress_warnings = True, # 收敛信息
stepwise = True,
)
Performing stepwise search to minimize aic
ARIMA(1,1,1)(0,0,0)[0] intercept : AIC=3508.854, Time=0.17 sec
ARIMA(0,1,0)(0,0,0)[0] intercept : AIC=3587.776, Time=0.01 sec
ARIMA(1,1,0)(0,0,0)[0] intercept : AIC=3573.940, Time=0.01 sec
ARIMA(0,1,1)(0,0,0)[0] intercept : AIC=3509.903, Time=0.06 sec
ARIMA(0,1,0)(0,0,0)[0] : AIC=3585.787, Time=0.00 sec
ARIMA(2,1,1)(0,0,0)[0] intercept : AIC=3500.610, Time=0.09 sec
ARIMA(2,1,0)(0,0,0)[0] intercept : AIC=3540.400, Time=0.02 sec
ARIMA(3,1,1)(0,0,0)[0] intercept : AIC=3502.598, Time=0.14 sec
ARIMA(2,1,2)(0,0,0)[0] intercept : AIC=3503.442, Time=0.15 sec
ARIMA(1,1,2)(0,0,0)[0] intercept : AIC=3505.978, Time=0.19 sec
ARIMA(3,1,0)(0,0,0)[0] intercept : AIC=3516.118, Time=0.04 sec
ARIMA(3,1,2)(0,0,0)[0] intercept : AIC=3504.888, Time=0.10 sec
ARIMA(2,1,1)(0,0,0)[0] : AIC=3500.251, Time=0.04 sec
ARIMA(1,1,1)(0,0,0)[0] : AIC=3509.015, Time=0.04 sec
ARIMA(2,1,0)(0,0,0)[0] : AIC=3538.500, Time=0.02 sec
ARIMA(3,1,1)(0,0,0)[0] : AIC=3502.238, Time=0.09 sec
ARIMA(2,1,2)(0,0,0)[0] : AIC=3503.042, Time=0.10 sec
ARIMA(1,1,0)(0,0,0)[0] : AIC=3571.973, Time=0.01 sec
ARIMA(1,1,2)(0,0,0)[0] : AIC=3508.438, Time=0.05 sec
ARIMA(3,1,0)(0,0,0)[0] : AIC=3514.328, Time=0.03 sec
ARIMA(3,1,2)(0,0,0)[0] : AIC=3504.226, Time=0.12 sec
Best model: ARIMA(2,1,1)(0,0,0)[0]
Total fit time: 1.478 seconds
查看模型信息
开发环境信息:
print(pm.show_versions())
System:
python: 3.7.10 (default, Mar 6 2021, 16:49:05) [Clang 12.0.0 (clang-1200.0.32.29)]
executable: /Users/zfwang/.pyenv/versions/3.7.10/envs/ts/bin/python
machine: Darwin-22.1.0-x86_64-i386-64bit
Python dependencies:
pip: 22.2.2
setuptools: 47.1.0
sklearn: 1.0.2
statsmodels: 0.13.2
numpy: 1.21.6
scipy: 1.7.3
Cython: 0.29.30
pandas: 1.3.5
joblib: 1.1.0
pmdarima: 1.8.5
模型信息:
print(stepwise_fit.summary())
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 176
Model: SARIMAX(2, 1, 1) Log Likelihood -1746.125
Date: Sun, 13 Nov 2022 AIC 3500.251
Time: 00:19:45 BIC 3512.910
Sample: 0 HQIC 3505.386
- 176
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.1420 0.109 1.307 0.191 -0.071 0.355
ar.L2 -0.2572 0.125 -2.063 0.039 -0.502 -0.013
ma.L1 -0.9074 0.052 -17.526 0.000 -1.009 -0.806
sigma2 2.912e+07 1.19e-09 2.44e+16 0.000 2.91e+07 2.91e+07
===================================================================================
Ljung-Box (L1) (Q): 0.01 Jarque-Bera (JB): 0.48
Prob(Q): 0.92 Prob(JB): 0.79
Heteroskedasticity (H): 1.37 Skew: -0.12
Prob(H) (two-sided): 0.23 Kurtosis: 2.92
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[2] Covariance matrix is singular or near-singular, with condition number 2.74e+32. Standard errors may be unstable.
序列化模型
pickle
import pickle
# pickle serialize model
with open("arima.pkl", "wb") as pkl:
pickle.dump(stepwise_fit, pkl)
# pickle load model
with open("arima.pkl", "rb") as pkl:
pickle_preds = pickle.load(pkl).predict(n_periods = 5)
joblib
import joblib
# joblib serialize model
with open("arima.pkl", "wb") as pkl:
joblib.dump(stepwise_fit, pkl)
# joblib load model
with open("arima.pkl", "rb") as pkl:
joblib_preds = joblib.load(pkl).predict(n_periods = 5)
对比 pickle 和 joblib 结果
np.allclose(pickle_preds, joblib_preds)
使用新的观测样本更新模型
# data
wineind = load_wineind().astype(np.float64)
train, test = wineind[:125], wineind[125:]
# 拟合 stepwise auto-ARIMA
stepwise_fit = pm.auto_arima(
y = wineind,
start_p = 1,
max_p = 3,
start_q = 1,
max_q = 3,
seasonal = True,
d = 1,
D = 1,
trace = True,
error_action = "ignore",
suppress_warnings = True, # 收敛信息
stepwise = True,
)
# ARIMA model
arima = pm.ARIMA(order = (2, 1, 1), seasonal_order = (0, 0, 0, 0))
arima.fit(train)
# pickle serialize model
with open("arima.pkl", "wb") as pkl:
pickle.dump(arima, pkl)
# pickle load model
with open("arima.pkl", "rb") as pkl:
arima = pickle.load(pkl)
pickle_preds = arima.predict(n_periods = 5)
# 更新模型
arima.update(test)
# pickle serialize model
with open("arima.pkl", "wb") as pkl:
pickle.dump(arima, pkl)
auto_arima 使用
auto_arima 函数根据提供的信息准则(AIC、AICc、BIC 或 HQIC)将最佳 ARIMA 模型拟合到单变量时间序列。
该函数在提供的约束范围内对可能的模型和季节性阶数(seasonal orders) 执行搜索(逐步或并行),并选择最小化给定指标的参数
auto_arima 函数有很多参数需要调整,模型拟合的结果在很大程度上取决于其中的一些参数
了解 p, d 和 q
p:自回归模型(auto-regressive, AR)的阶数(order),即滞后观测值的数量- The order of the auto-regressive (AR) model (i.e., the number of lag observations). A time series is considered AR when previous values in the time series are very predictive of later values. An AR process will show a very gradual decrease in the ACF plot.
d:差分的自由度- The degree of differencing.
q:移动平均模型(moving average, MA)的阶数- The order of the moving average (MA) model. This is essentially the size of the “window” function over your time series data. An MA process is a linear combination of past errors.
ARIMA 模型的一般形式为 ,参数 和 可以用函数 auto_arima 进行迭代搜索,
但差分项 需要一组特殊的平稳性测试来估计
差分项 d
差分计算:
import pmdarima as pm
from pmdarima.utils import c, diff
# lag 1, diff 1
x = pm.c(10, 4, 2, 9, 34)
diff(x, lag = 1, differences = 1)
平稳性检验
自相关图:
import pmdarima as pm
from pmdarima import datasets
y = datasets.load_lynx()
pm.plot_acf(y)
ADFTest:
from pmdarima.arima.stationarity import ADFTest
adf_test = ADFTest(alpha = 0.05)
p_val, should_diff = adf_test.should_diff(y) # (0.01, False)
PPTest:
KPSSTest:
的估计:
from pmdarima.arima.utils import ndiffs
# ADF test
n_adf = ndiffs(y, test = "adf")
# KPSS test
n_kpss = ndiffs(y, test = "kpss")
# PP test
n_pp = ndiffs(y, test = "pp")
assert n_adf == n_kpss == n_pp == 0
在 ARIMA 模型的情况下,使数据平稳的最简单方法是允许 auto_arima 发挥其魔力,估计适当的 d 值,
并相应地区分时间序列。然而,其他用于强制平稳性的常见转换包括(有时相互结合):
- 平方根或 N 次根变换
- 去趋势化
- 对时间序列进行一次或多次差分
- 对数转换
了解 P, Q, D 和 m
季节性 ARIMA 模型有三个类似于 p, d, d 的参数:
P:自回归 (AR) 模型的季节性成分的阶数D:季节性过程的差分阶Q:移动平均 (MA) 模型的季节性成分的阶数
P 和 Q 的估计类似于通过 auto_arima 模型估计 p、q,而 D 的估计可以通过 Canova-Hansen 检验,
季节性差分项 D 的估计
默认情况下,如果在 auto_arima 中设置 seasonal=True,D 会被估计,但是要设置好 m 和 max_D
from pmdarima.datasets import load_lynx
from pmdarima.arima.utils import nsdiffs
# data
lynx = load_lynx()
# Canova-Hansen test
D = nsdiffs(
lynx,
m = 10,
max_D = 12,
test = "ch",
)
# OCSB test
nsdiffs(
lynx,
m = 10,
max_D = 12,
test = "ocsb"
)
设置 m
m 参数与每个季节周期的观察次数有关,并且是一个必须先验已知的参数。
通常,m 将对应于一些经常性的周期性,例如:
- 7 - daily
- 12 - monthly
- 52 - weekly
import pmdarima as pm
# data
data = pm.datasets.load_wineind()
train, test = data[:150], data[150:]
# model
m1 = pm.auto_arima(
train,
error_action = "ignore",
seasonal = True,
m = 1
)
m12 = pm.auto_arima(
train,
error_action = "ignore",
seasonal = True,
m = 12
)
并行和逐步
auto_arima 函数有两种模式:
- stepwise
- parallelized(比较慢)
基本步骤:
- 尝试从四个可能得模型开始
ARIMA(2, d, 2)ifm=1andARIMA(2, d, 2)(1, D, 1)ifm>1ARIMA(0, d, 0)ifm=1andARIMA(0, d, 0)(0, D, 0)ifm>1ARIMA(1, d, 0)ifm=1andARIMA(1, d, 0)(1, D, 0)ifm>1ARIMA(0, d, 1)ifm=1andARIMA(0, d, 1)(0, D, 1)ifm>1
- 考虑其他的模型
- Where one of p, q, P and Q is allowed to vary by ±1 from the current best model
- Where p and q both vary by ±1 from the current best model
- Where P and Q both vary by ±1 from the current best model
StepwiseContext
import pmdarima as pm
from pmdarima.arima import StepwiseContext
# data
data = pm.datasets.load_wineind()
train, test = data[:150], data[150:]
# model
with StepwiseContext(max_dur = 15):
model = pm.auto_arima(
train,
stepwise = True,
error_action = "ignore",
seasonal = True,
m = 12
)
Pipeline
可以应用的模型:
ARIMAAutoARIMA
import pmdarima as pm
from pmdarima.pipeline import Pipeline
from pmdarima.preprocessing import BoxCoxEndogTransformer
# data
wineind = pm.datasets.load_wineind()
train, test = wineind[:150], wineind[150:]
# pipeline
pipeline = Pipeline([
("boxcox", BoxCoxEndogTransformer()),
("model", pm.AutoARIMA(seasonal = True, suppress_warnings = True))
])
# model fit
pipeline.fit(train)
# model predict
pipeline.predict(n_periods = 5)