特征采样-分类任务
wangzf / 2022-09-13
不平衡数据集的问题描述
样本类别样本不平衡(class-imbalance)数据集是指一个类中的示例数量与另一类中的示例数量显著不同的情况。 例如在一个二元分类问题中,一个类只占总样本的一小部分,这被称为不平衡数据集。 类不平衡会在构建机器学习模型时导致很多问题。一般地,常情况下样本类别比例(imbalance ratio)明显大于 , 比如超过 (也有说 )的数据就可以称为不平衡数据
样本不平衡实际上是一种非常常见的现象。比如:在欺诈交易检测,欺诈交易的订单应该是占总交易数量极少部分; 工厂中产品质量检测问题,合格产品的数量应该是远大于不合格产品的;信用卡的征信问题中往往就是正样本居多
- 不平衡数据集的主要问题之一是模型可能会偏向多数类,从而导致预测少数类的性能不佳。 这是因为模型经过训练以最小化错误率,并且当多数类被过度代表时,模型倾向于更频繁地预测多数类。 这会导致更高的准确率得分,但少数类别得分较低
- 另一个问题是,当模型暴露于新的、看不见的数据时,它可能无法很好地泛化。 这是因为该模型是在倾斜的数据集上训练的,可能无法处理测试数据中的不平衡
机器学习算法的学习阶段和后续预测可能会受到不平衡数据集问题的影响。 平衡问题对应于不同类别中样本数量的差异。下面的示例说明了训练具有不同类平衡级别的线性 SVM 分类器的效果。 正如预期的那样,线性 SVM 的决策函数会根据数据的不平衡程度而有很大差异。 不平衡率越大,决策函数有利于样本数量越多的类,通常称为多数类
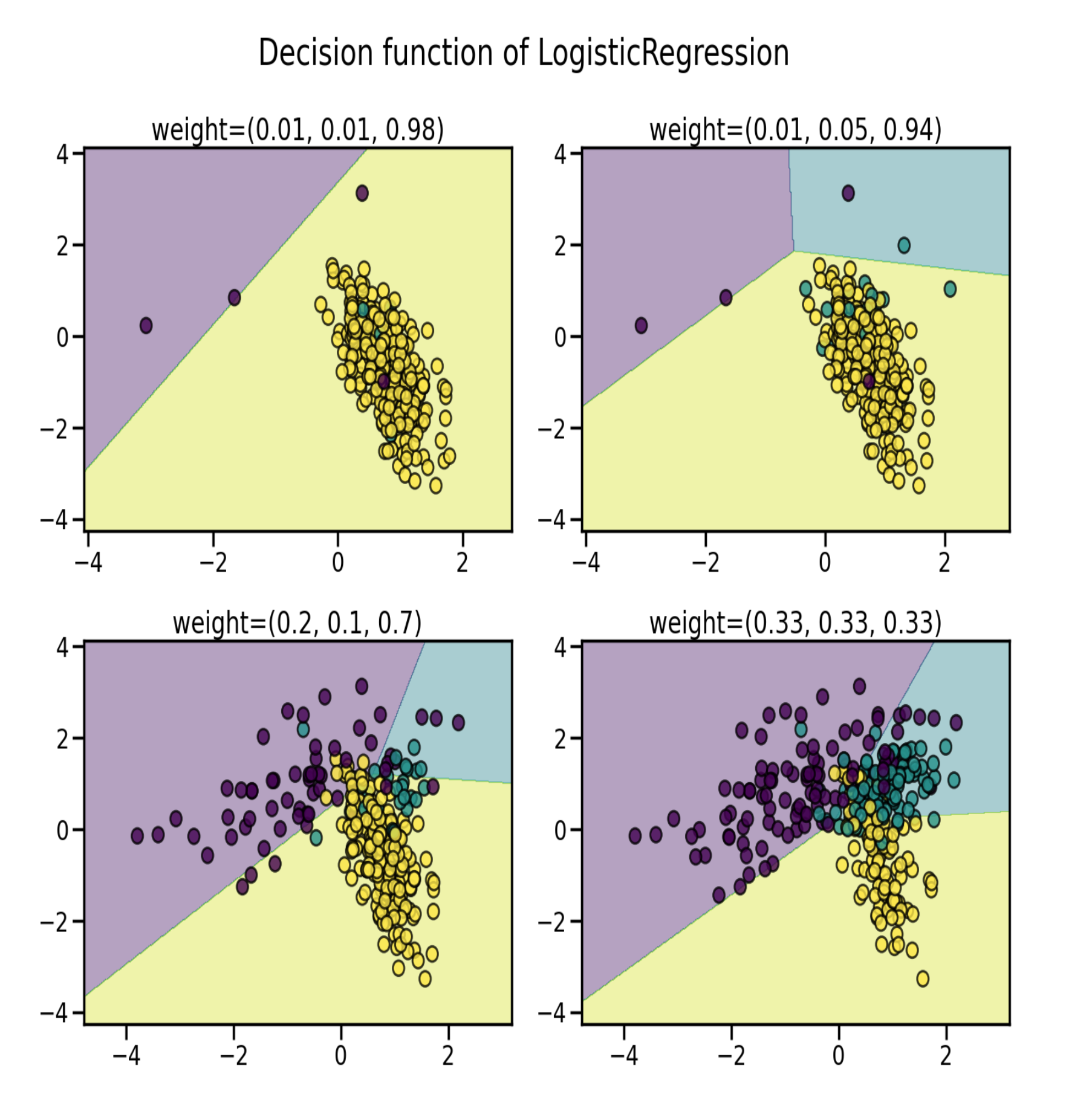
这里将讨论处理不平衡数据集和提高机器学习模型性能的各种技巧和策略。 将涵盖的一些技术包括重采样技术、代价敏感学习、使用适当的性能指标、集成方法和其他策略。 通过这些技巧,可以为不平衡的数据集构建有效的模型
不平衡数据集的处理方法
处理不平衡数据集的技巧
重采样技术是处理不平衡数据集的最流行方法之一。 这些技术涉及减少多数类中的示例数量或增加少数类中的示例数量
- 欠采样可以从多数类中随机删除示例以减小其大小并平衡数据集。 这种技术简单易行,但会导致信息丢失,因为它会丢弃一些多数类示例
- 过采样与欠采样相反,过采样随机复制少数类中的示例以增加其大小。 这种技术可能会导致过度拟合,因为模型是在少数类的重复示例上训练的
- SMOTE 是一种更高级的技术,它创建少数类的合成示例,而不是复制现有示例。 这种技术有助于在不引入重复项的情况下平衡数据集
- 代价敏感学习(Cost-sensitive learning)是另一种可用于处理不平衡数据集的技术。 在这种方法中,不同的错误分类成本被分配给不同的类别。这意味着与错误分类多数类示例相比, 模型因错误分类少数类示例而受到更严重的惩罚
在处理不平衡的数据集时,使用适当的性能指标也很重要。准确性并不总是最好的指标, 因为在处理不平衡的数据集时它可能会产生误导。相反,使用 AUC-ROC、F1 Measure 等指标可以更好地指示模型性能
集成方法,例如 bagging 和 boosting,也可以有效地对不平衡数据集进行建模。 这些方法结合了多个模型的预测以提高整体性能。
- Bagging 涉及独立训练多个模型并对它们的预测进行平均
- Boosting 涉及按顺序训练多个模型,其中每个模型都试图纠正前一个模型的错误
重采样技术、成本敏感学习、使用适当的性能指标和集成方法是一些技巧和策略, 可以帮助处理不平衡的数据集并提高机器学习模型的性能
在不平衡数据集上提高模型性能的策略
- 收集更多数据是在不平衡数据集上提高模型性能的最直接策略之一。 通过增加少数类中的示例数量,模型将有更多信息可供学习,并且不太可能偏向多数类。 当少数类中的示例数量非常少时,此策略特别有用
- 生成合成样本是另一种可用于提高模型性能的策略。合成样本是人工创建的样本, 与少数类中的真实样本相似。这些样本可以使用 SMOTE 等技术生成, 该技术通过在现有示例之间进行插值来创建合成示例。 生成合成样本有助于平衡数据集并为模型提供更多示例以供学习
- 使用领域知识来关注重要样本也是一种可行的策略,通过识别数据集中信息量最大的示例来提高模型性能。 例如,如果我们正在处理医学数据集,可能知道某些症状或实验室结果更能表明某种疾病。 通过关注这些例子可以提高模型准确预测少数类的能力
- 最后可以使用异常检测等高级技术来识别和关注少数类示例。 这些技术可用于识别与多数类不同且可能是少数类示例的示例。 这可以通过识别数据集中信息量最大的示例来帮助提高模型性能。
在收集更多数据、生成合成样本、使用领域知识专注于重要样本, 以及使用异常检测等先进技术是一些可用于提高模型在不平衡数据集上的性能的策略。 这些策略可以帮助平衡数据集,为模型提供更多示例以供学习,并识别数据集中信息量最大的示例
算法
随机过采样
通过有放回随机抽样替换当前可用样本来生成新样本,通过复制一些少数类的原始样本
SMOTE
SMOTE 算法简介
SMOTE(Synthetic Minority Oversampling Technique),合成少数类过采样技术。 它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本, 这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General)
SMOTE 算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中, 具体如下图所示,算法流程如下:
- 对于少数类中每一个样本 ,以欧氏距离为标准计算它到少数类样本集中所有样本的距离, 得到其 近邻
- 根据样本不平衡比例设置一个采样比例以确定采样倍率 ,, 对于每一个少数类样本 ,从其 近邻中随机选择若干个样本, 假设选择的近邻为
- 对于每一个随机选出的近邻 ,分别与原样本 按照如下的公式构建新的样本:
SMOTE 算法的伪代码如下:

SMOTE 算法的缺陷
- 一是在近邻选择时,存在一定的盲目性。从上面的算法流程可以看出,在算法执行过程中,需要确定
k值, 即选择多少个近邻样本,这需要用户自行解决。从k值的定义可以看出,k值的下限是M值(M值为从k个近邻中随机挑选出的近邻样本的个数,且有M < k),M的大小可以根据负类样本数量、正类样本数量和数据集最后需要达到的平衡率决定。但k值的上限没有办法确定, 只能根据具体的数据集去反复测试。因此如何确定k值,才能使算法达到最优这是未知的 - 另外,该算法无法克服非平衡数据集的数据分布问题,容易产生分布边缘化问题。由于负类样本的分布决定了其可选择的近邻, 如果一个负类样本处在负类样本集的分布边缘,则由此负类样本和相邻样本产生的"人造”样本也会处在这个边缘,且会越来越边缘化, 从而模糊了正类样本和负类样本的边界,而且使边界变得越来越模糊。这种边界模糊性,虽然使数据集的平衡性得到了改善, 但加大了分类算法进行分类的难度
针对 SMOTE 算法的进一步改进
针对 SMOTE 算法存在的边缘化和盲目性等问题,很多人纷纷提出了新的改进办法, 在一定程度上改进了算法的性能,但还存在许多需要解决的问题。
Han 等人在 SMOTE 算法基础上进行了改进, 提出了 Borderline-SMOTE(Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning) 算法, 解决了生成样本重叠(Overlapping)的问题,该算法在运行的过程中查找一个适当的区域,该区域可以较好地反应数据集的性质, 然后在该区域内进行插值,以使新增加的"人造”样本更有效。这个适当的区域一般由经验给定,因此算法在执行的过程中有一定的局限性
ADASYN
Adasyn: adaptive synthetic sampling approach for imbalanced learning
Borderline SMOTE
SVM SMOTE
KMeans SMOTE
联合采样
SMOTE Tomek
SMOTE ENN
edited nearest-neighbors
集成采样器
Bagging 分类器
随机森林分类器
Boosting 分类器
其他采样器
自定义采样器
自定义生成器
TensorFlow
Keras
不平衡数据集分类器指标
sklearn 指标
sklearn.metrics.balanced_accuracy_score
imblearn 指标
灵敏性和特异性指标
Macro-Averaged Mean Absolute Error
MA-MAE
重要性指标
imblearn
安装
$ pip install -U imbalanced-learn
使用
Estimator:
estimator = obj.fit(data, targets)
Resampler:
data_resampled, targets_resampled = obj.fit_resample(data, targets)
Inputs:
data- 2-D
list - 2-D
numpy.ndarray pandas.DataFramescipy.sparse.csr_matrixscipy.sparse.csc_matrix
- 2-D
targets- 1-D
numpy.ndarray pandas.Series
- 1-D
Outputs:
data_resampled- 2-D
numpy.ndarray pandas.DataFramescipy.sparse.csr_matrixscipy.sparse.csc_matrix
- 2-D
targets_resampled- 1-D
numpy.ndarray pandas.Series
- 1-D
过采样
Over-sampling
-
SMOTE
SMOTE
-
Borderline SMOTE
BorderlineSMOTE
-
SMOTE NC
SMOTENC
-
SMOTEN
SMOTEN
-
SVM SMOTE
SVMSMOTE
-
KMeans SMOTE
KMeansSMOTE
-
ADASYN
ADASYN
-
imblearn.over_samplingRandomOverSamplerADASYNBorderlineSMOTEKMeansSMOTESMOTESMOTENCSVMSMOTE
Random Over Sampler
- Naive Strategy: generate new samples by randomly sampling with replacement the current available samples
- API:
imblearn.over_sampling.RandomOverSampler
随机过采样:
from sklearn.datasets import make_classification
from imblearn.over_sampling import RandomOverSampler
from collections import Counter
from sklearn.svm import LinearSVC
# data
X, y = make_classificaion(
n_samples = 5000,
n_features = 2,
n_informative = 2,
n_redundant = 0,
n_repeated = 0,
n_classes = 3,
n_clusters_per_class = 1,
weights = [0.01, 0.05, 0.94],
class_sep = 0.8,
random_state = 0
)
# resample
ros = RandomOverSampler(random_state = 0)
X_resampled, y_resampled = ros.fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
# model
clf = LinearSVC()
clf.fit(X_resampled, y_resampled)
随机过采样对异构数据进行采样:
import numpy as np
from imblearn.over_sampling import RandomOverSampler
# data
X_hetero = np.array(
[["xxx", 1, 1.0],
["yyy", 2, 2.0],
["zzz", 3, 3.0]],
dtype = object
)
y_hetero = np.array([0, 0, 1])
# 过采样
ros = RandomOverSampler(random_state = 0)
X_resampled, y_resampled = ros.fit_resample(X_hetero, y_hetero)
print(X_resampled)
print(y_resampled)
随机过采样支持 Pandas DataFrame:
from sklearn.datasets import fetch_openml
from imblearn.over_sampling import RandomOverSampler
# data
df_adult, y_adult = fetch_openml(
"adult",
version = 2,
as_frame = True,
return_X_y = True
)
df_adult.head()
# 过采样
ros = RandomOverSampler(random_state = 0)
df_resampled, y_resampled = ros.fit_resample(df_adult, y_adult)
df_resampled.head()
随机过采样示例(Random Over-Sampling Examples)Training and assessing classification rules with imbalanced data:
SMOTE
from imblearn.over_sampling import ADASYN
X_resampled, y_resampled = SMOTE().fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
clf_smote = LinearSVC().fit(X_resampled, y_resampled)
ANASYN
from imblearn.over_sampling import ADASYN
X_resampled, y_resampled = ADASYN().fit(X, y)
print(sorted(Counter(y_resampled).items()))
clf_adasyn = LinearSVC().fit(X_resampled, y_resampled)
Borderline SMOTE
from imblearn.over_sampling import BorderlineSMOTE
X_resampled, y_resampled = BorderlineSMOTE().fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
SMOTENC
处理类别型数据
import numpy as np
from imblearn.over_sampling import SMOTENC
rng = np.random.RandomState(42)
n_samples = 50
X = np.empty((n_samples, 3), dtype = object)
X[:, 0] = rng.choice(["A", "B", "C"], size = n_samples).astype(object)
X[:, 1] = rng.randn(n_samples)
X[:, 2] = rng.randint(3, size = n_samples)
y = np.array([0] * 20 + [1] * 30)
print(sorted(Counter(y).items()))
smote_nc = SMOTENC(categorical_features = [0, 2], random_state = 0)
X_resampled, y_resampled = smote_nc.fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
print(X_resampled[-5:])
SMOTEN
处理类别型数据
import numpy as np
from imblearn.over_sampling import SMOTEN
X = np.array(
["green"] * 5 + ["red"] * 10 + ["blue"] * 7,
dtype = object
).reshape(-1, 1)
y = np.array(
["apple"] * 5 + ["not apple"] * 3 + ["apple"] * 7 +
["not apple"] * 5 + ["apple"] * 2,
dtype = object
)
sampler = SMOTEN(random_state = 0)
X_res, y_res = sampler.fit_resample(X, y)
X_res[y.size:]
y_res[y.size:]
SVM SMOTE
KMeans SMOTE
降采样
Under-sampling
- imblearn.under_sampling
- Prototype generation
ClusterCentroids()
- Prototype selection
CondensedNearestNeighbour()EditedNearestNeighbours()RepeatedEditedNearestNeighbours()AllKNN()InstanceHardnessThreshold()NearMiss()NeighbourhoodCleaningRule()OneSidedSelection()RandomUnderSampler()TomekLinks()
- Prototype generation
原型生成
给定原始数据集 , 原型生成算法会生成一个新的集合 。其中:
换句话说,原型生成技术将减少目标类中的样本数量,但剩余的样本是从原始集合中生成的,而不是从中选择的。
ClusterCentroids 利用 K-means 来减少样本数量。因此,每个类将使用 K-means 方法的质心而不是原始样本进行合成
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.under_sampling import ClusterCentroids
X, y = make_classification(
n_samples = 5000,
n_features = 2,
n_informative = 2,
n_redundant = 0,
n_repeated = 0,
n_classes = 3,
n_clusters_per_class = 1,
weights = [0.01, 0.05, 0.94],
class_sep = 0.8,
random_state = 0
)
print(sorted(Counter(y).items()))
cc = ClusterCentroids(random_state = 0)
X_resampled, y_resampled = cc.fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
原型选择
与原型生成算法相反,原型选择算法将从原始集合中选择样本 . 所以, 被定义为 和 .
此外,这些算法可以分为两组:
- 受控欠采样技术和
- 清洁欠采样技术
第一组方法允许采用欠采样策略,其中样本数量在由用户指定。相比之下,清洁欠采样技术不允许此规范,并且旨在清洁特征空间
Controlled 降采样
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state = 0)
X_resampled, y_resampled = rus.fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
Cleaning 降采样
Tomek’s links:
Condensed nearest neighbors and derived algorithms
Instance hardness threshold:
联合采样
Combination of over and under sampling
- imblearn.combine
- imblearn.combine.SMOTEENN
- imblearn.combine.SMOTETomek
集成采样
Ensemble of samplers
- imblearn.ensemble
其他
- imblearn.keras
- imblearn.tensorflow
- imblearn.pipeline
- imblearn.metrics
- imblearn.datasets
- imblearn.utils