NLP:Nature Language Processing
wangzf / 2022-04-05
目录
NLP 介绍
自然语言处理(Nature Language Processing, NLP)是人工智能和语言学领域的分支学科。 此领域探讨如何处理及运用自然语言。NLP 包括多方面和步骤,基本有认知、理解、生成等部分。
自然语言认知和理解是让计算机把输入的语言变成有意思的符号和关系,然后根据目的再进行处理。 所以简单来说,NLP 就是让计算机理解人类语言。为了达到这样的目的,我们需要在理论上基于 数学和统计理论建立各种自然语言,然后通过计算机来实现这些语言模型。因为人类语言的多样性和复杂性, 所以总体而言 NLP 是一门极具挑战的学科和领域。
NLP 难度
NLP 是个非常庞杂的领域,学习和应用起来都颇有难度。 难度体现在 语言场景、学习算法 和 语料 三个方面:
- 语言场景 是指人类语言的多样性、复杂性和歧义性
- 学习算法 指的是 NLP 的数理模型,一般都较为难懂,比如隐马尔科夫模型(HMM)、 条件随机场(CRF)以及基于 RNN 的深度学习模型
- 语料 的困难性指的是如何获取高质量的训练语料
NLP 结构
从自然语言的角度出发,NLP 结构如下:
- 自然语言理解(Natural Language Understanding,NLU):涉及语言、语境和各种语言形式的学科
- 音系学: 指代语言中发音的系统化组织
- 词态学: 研究单词构成以及相互之间的关系
- 句法学: 给定文本的那本分是语法正确的
- 语义学: 给定文本的含义是什么
- 语用学: 文本的目的是什么
- 自然语言生成(Natural Language Generation,NLG):从结构化数据中以读取的方式自动生成文本。该过程主要包含三个阶段:
- 文本规划:完成机构化数据中的基础内容规划
- 语句规划:从结构化数据中组合语句来表达信息流
- 实现:产生语法通顺的语句来表达文本
NLP 模型
NLP 的模型基本包括两类:
- 基于概率图方法的模型:在深度学习兴起之前,NLP 基本理论模型基础都是靠概率图模型撑起来的
- 贝叶斯网络
- 马尔科夫链
- 隐马尔科夫模型
- EM 算法
- CRF 条件随机场
- 最大熵模型
- 基于 RNN 的深度学习方法
- 词嵌入(Word Embedding)
- 词向量(Word Vector):word2vec
- 基于 RNN 的机器翻译
- 基于 Transformer 的大语言模型
NLP 任务
-
机器翻译: 计算机具备将一种语言翻译成另一种语言的能力
-
情感分析: 计算机能够判断用户评论是否积极
-
智能问答: 计算机能够正确回答输入的问题
-
文摘生成: 计算机能够准确归纳、总结并产生文本摘要
-
文本分类: 计算机能够采集各种文章,进行主题分析,从而进行自动分类
-
舆论分析: 计算机能够判断目前舆论的导向
-
知识图谱: 知识点相互连接而成的语义网路
-
分词(segment)
- 分词常用的方法是基于字典的最长串匹配,但是歧义分词很难
-
词性标注(part-of-speech tagging)
- 词性一般是指动词(noun)、名词(verb)、形容词(adjective)等
- 标注的目的是表征词的一种隐藏状态,隐藏状态构成的转移就构成了状态转义序列
-
命名实体识别(NER,Named Entity Recognition)
- 命名实体是指从文本中识别具有特定类别的实体,通常是名词
-
句法分析(syntax parsing)
- 句法分析是一种基于规则的专家系统
- 句法分析的目的是解析句子中各个成分的依赖关系,所以,往往最终生成的结果是一棵句法分析树
- 句法分析可以解决传统词袋模型不考虑上下文的问题
-
指代消解(anaphora resolution)
- 中文中代词出现的频率很高,它的作用是用来表征前文出现过的人名、地名等
-
情感识别(emotion recognition)
- 情感识别本质上是分类问题。通常可以基于词袋模型+分类器,或者现在流行的词向量模型+RNN
-
纠错(correction)
- 基于 N-Gram 进行纠错、通过字典树纠错、有限状态机纠错
-
问答系统(QA system)
- 问答系统往往需要语言识别、合成、自然语言理解、知识图谱等多项技术的配合才会实现得比较好
-
句法语义分析
-
关键词抽取
-
文本挖掘
-
信息检索
-
问答系统
-
对话系统
-
文档分类
-
自动文摘
-
信息抽取
-
舆情分析
-
机器写作
-
语音识别
-
语音合成
NLP 层面
- 词法分析
- 分词
- 词性标注
- 句法分析
- 短语结构句法体系
- 依存结构句法体系
- 深层文法句法分析
- 语义分析
- 语义角色标注(semantic role labeling)
NLP 技术
- 文本分类
- 朴素贝叶斯
- 逻辑回归
- 支持向量机
- 文本聚类
- K-means
- 特征提取
- Bag-of-words
- TF
- IDF
- TF-IDF
- N-Gram
- 标注
- 搜索与排序
- 推荐系统
- 序列学习
- 语音识别
- 文本转语音
- 机器翻译
NLP 语料库
- 中文
- 中文维基百科
- 搜狗新闻语料库
- IMDB 情感分析语料库
- 豆瓣读书
- 邮件相关
- 英文
构建 NLP Pipeline

数据
London is the capital and most populous city of England and the United
Kingdom. Standing on the River Thames in the south east of the island of
Great Britain, London has been a major settlement for two millennia. It
was founded by the Romans, who named it Londinium.
[数据来源 Wikipedia article “London”]
上面这段文本包含了一些有用的事实,我们需要让计算机能够理解以下内容:
- London is a city
- London is located in England
- London was settled by Romans
- …
分句
Sentence Segmentation
NLP Pipeline 的第一步就是 将文本分割为句子:
- “London is the capital and most populous city of England and the United Kingdom.”
- “Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia.”
- “It was founded by the Romans, who named it Londinium.”
分词
Word Tokenization
- 句子(Sentence):
- 分词(Tokenization):

分词对于英文来说非常容易,可以根据单词之间的空格对文本句子进行分割。 并且,也可以将标点符号也看成一种分割符,因为标点符号也是有意义的。
词性标注
Predicting Parts of Speech for Each Token
通过词性标注,可以知道每个词在句子中的角色,即词性,词性包括名词(noun)、 动词(verb)、形容词(adjective)等等,这样可以帮助计算机理解句子的意思。
通过将每个单词(以及其周围的一些额外单词用于上下文)输入到预先训练的词性分 类模型中进行词性标注. 词性分类模型完全基于统计数据根据以前见过的相似句子 和单词来猜词性。
- 词性标注过程
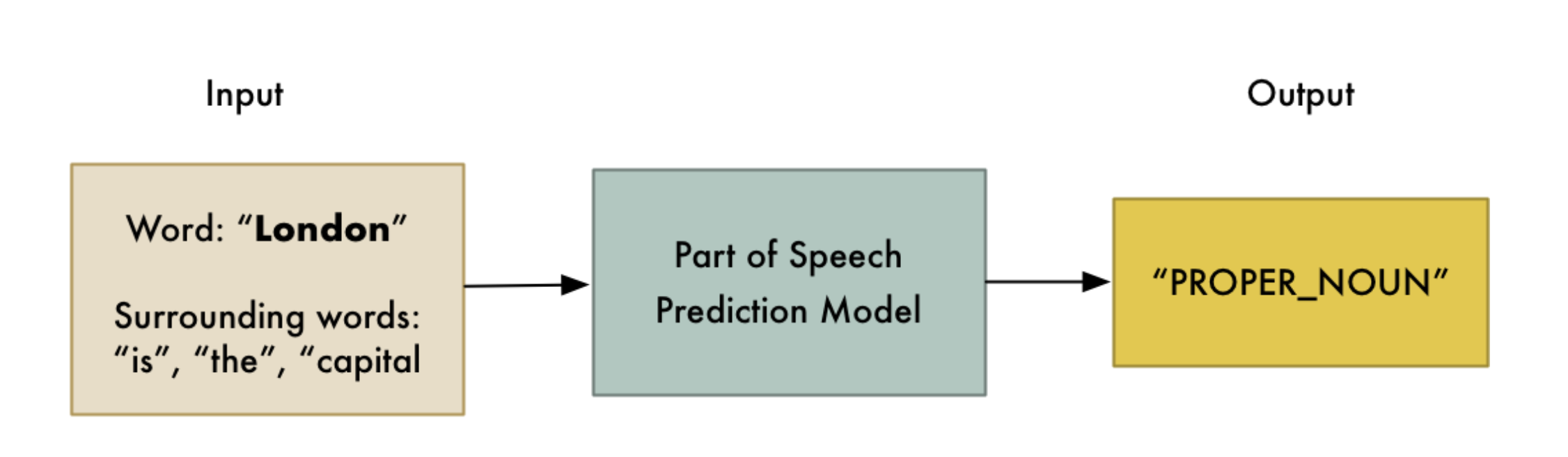
- 词性标注结果

通过词性标注后的信息,可以收集到一些关于句子的基本含义了,例如:可以看到句子中看到有"London"、 和 “captial” 两个名词(Noun),因此该句子可能在谈论 “London”。
Text Lemmatization
在 NLP 中,称此过程为 词性限制(lemmatization),即找出句子中每个单词的最基本形式或词缀(lemma)。
示例
在自然语言中,单词或词会以不同的形式同时出现:
- I had a pony.
- I had two ponies.
上面两个句子中都在表达 pony,但是两个句子中使用了 pony 不同的词缀。
在计算机处理文本时,了解每个单词的基本形式很有帮助,这样就可以知道两个句子都在 表达相同的概念,否则,字符串 “pony” 和 “ponies” 对于计算机来说就像两个完全 不同的词.
同样对于动词(verb)道理也一样:
- I had two ponies.
- I have two pony.
London 句子示例

识别停用词
Identifying Stop Words
停用词的识别主要是用来考虑句子中每个单词的重要性。
自然语言汇总有很多填充词,例如: “and”,“the”,“a”,这些词经常出现。 在对文本进行统计时,这些填充词会给文本数据带来很多噪音,因为他们比其他 单词更频繁地出现。一些 NLP Pipeline 会将它们标记为 停用词(Stop Word)。 这些停用词需要在进行任何统计分析之前将其过滤掉。
- London 示例:

- 通常仅通过检查已知停用词的硬编码列表即可识别停用词.
- 没有适用于所有应用程序的标准停用词列表,要忽略的单词列表可能会因应用程序而异.
- 例如:如果要构建摇滚乐队搜索引擎,则要确保不要过滤到单词 “The”。因为,“The” 一词 会经常出现在乐队的名字中,比如 1980年代的注明摇滚乐队 “The The!”.
句法依赖分析
Dependency Parsing
命名实体识别
共指解析
构建 Python NLP Pipeline
